目录
更多内容可以到专栏查看:https://blog.csdn.net/sunshine543123/category_10899368.html
1.顺序查找(线性查找)
最基本的查找技术,从表中第一个记录开始,逐个进行记录的关键字和给定值比较
最优时间复杂度:O(1)
最坏时间复杂度:O(n)
平均时间复杂度:O(n)
2.有序表查找
2.1二分法查找*
元素必须是有序的,如果是无序的则要先进行排序操作。
二分法查找针对的是一个有序的数据集合,每次通过与区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为0。
public static int Binary(int[] a,int key){
int low=0;
int high=a.length-1;
int mid;
while (low<high){
mid=(low+high)/2;
if (key<a[mid]){
high=mid-1;
}
else if (key>a[mid]){
low=mid+1;
}
else {
return mid;
}
}
return -1;
}
时间复杂度:O(logn)
2.2. 插值查找(对mid进行改进)*
基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
注:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
int mid = low+(value-a[low])/(a[high]-a[low])*(high-low);
时间复杂度:O(logn)
2.3. 斐波那契查找*
基本思想:也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。
mid=low+F[K-1]-1
public class FibonacciSearch {
//斐波那契数列
static int[] F={
0,1,1,2,3,5,8,13,21,34};
public static void main(String[] args) {
int[] a={
0,1,16,24,35,47,59,62,73,88,99};
int result=FibonacciSearch(a,47)+1;
System.out.println("47在数组中的位置为:"+result);
}
public static int FibonacciSearch(int[] a,int key){
int low,high,mid,k;
low=0;
high = a.length-1; //最高下标
k=0;
while (a.length-1>F[k]-1){
//计算n位于斐波那契数列的位置
k++;
}
int[] b=new int[F[k]-1];
for (int i = 0; i < a.length; i++) {
b[i]=a[i];
}
for (int i = a.length-1; i < F[k]-1; i++) {
//将不满的数值补全
b[i]=a[a.length-1];
}
while (low<=high){
mid=low+F[k-1]-1;
if (key<b[mid]){
high=mid-1;
k=k-1;
}
else if (key>b[mid]){
low=mid+1;
k=k-2;
}
else{
if (mid<=a.length-1){
return mid;
}
else {
return a.length-1;
}
}
}
return -1;
}
}
时间复杂度:O(logn)
3.线性索引查找
索引就是把一个关键字与它对应的记录相关联的过程,一个索引由若干个索引项组成。
所谓线性索引就是将索引项集合组织为线性结构,也称为索引表。
3.1.稠密索引
将数据集中的每个数据对应一个索引项
稠密索引的索引表中,索引项一定是按照关键码有序的排列。
3.2.分块索引
将数据集的记录分成若干块,快间有序,块内无序。
3.3.倒排索引
根据属性来查找记录(索引项=属性值+具有该属性值的各记录地址)
4.二叉排序树
二叉排序树(Binary SortTree),又称为二叉查找树。它或者是一棵空树,或者是具有下列性质的二叉树。
若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若它的右子树不空 ,则右子树上所有结点的值均大于它的根结点的值;
它的左、右子树也分别为二叉排序树。
https://blog.csdn.net/sunshine543123/article/details/110592282
5.平衡二叉树(AVL树)
平衡二叉树是一种二叉排序树,其中每一个节点的左子树和右子树的高度差至多等于1。
平衡因子(BF):二叉树节点上左子树的深度减右子树的深度。
最小不平衡子树:距离插入节点最近的,且平衡因子的绝对值大于1的节点为根的子树。
实现思想:按照二叉排序树插入,每次插入时先检查是否因插入破坏了树的平衡,若是找出最小不平衡树,对其进行旋转调整,使其成为新的平衡子树。
6.红黑树
红黑树是一种相对平衡的(自平衡)二叉排序树
特点
- 每个节点非红即黑
- 根节点总是黑色的
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定)
- 每个叶子节点都是黑色的空节点(NIL节点)
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
7.多路查找树(B树)
多路查找树
多路查找树,其每一个结点的孩子数可以多于两个,且每一个结点处可以存储多个元素
7.1 2-3树
2-3树是一颗每个结点都具有两个孩子或三个孩子的多路查找树(一个2结点包括一个元素和两个孩子(或没有孩子),其中左孩子值小于该结点,右孩子值大于该结点;一个3结点包括一大一小两个元素和三个孩子(或没有孩子),其中左孩子值小于较小结点,右孩子值大于较大结点,中间孩子位于两元素之间)
7.2 B树
B树是一种平衡的多路查找树(节点最大的孩子数目称为B树的阶)。
B树的数据结构就是为内外存的数据交互准备的(减少磁盘等存储设备调入调出内存页面的次数)。
方法:使B树的阶数(或结点元素数)与磁盘存储的页面大小相匹配,减少了必须访问结点和数据块的数量。
在B树结构中,往返于每个节点之间也就意味着,在硬盘的页面之间进行多次访问。
7.3 B+树
B树的变形树(为了解决所有元素遍历等基本问题)
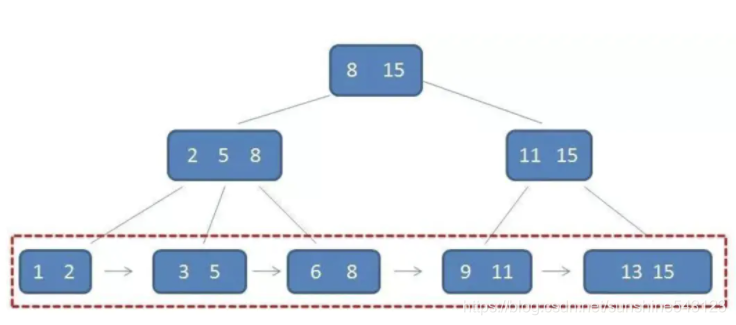
每个叶子节点都有一个指针,指向下一个数据,形成一个有序链表。
而只有叶子节点才会有data,其他都是索引。
而B+树中间节点没有Data数据,所以同样大小的磁盘页可以容纳更多的节点元素。所以数据量相同的情况下,B+树比B树更加“矮胖“,因此使用的IO查询次数更少。
8.哈希表
在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。
hashTable如果没有冲突,查找的时间复杂度为O(1)