@[TOC](Mysql(Innodb) 索引、事务、查询优化…(持续更新中))
Mysql (Innodb) 索引
索引的定义
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
索引的一个主要目的就是加快检索表中数据,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构。
索引的类型
1. primary key 主键索引
它是一种特殊的唯一索引,不允许有空值。一张表只能有一个主键
2. unique 唯一索引
唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
3. index 普通索引
这是最基本的索引,它没有任何限制。
4. fulltext 全文索引
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。它能够利用分词技术等多种算法智能分析出文本文字中关键字词的频率及重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。
5. 组合索引
组合索引,即一个索引包含多个列。
索引的结构
mysql中普遍使用B+Tree做索引,但在实现上又根据聚簇索引和非聚簇索引而不同,在这儿不做详细介绍,后续篇章中再展开详细说明。
建立索引
我们现在有一个订单表,表结构如下:
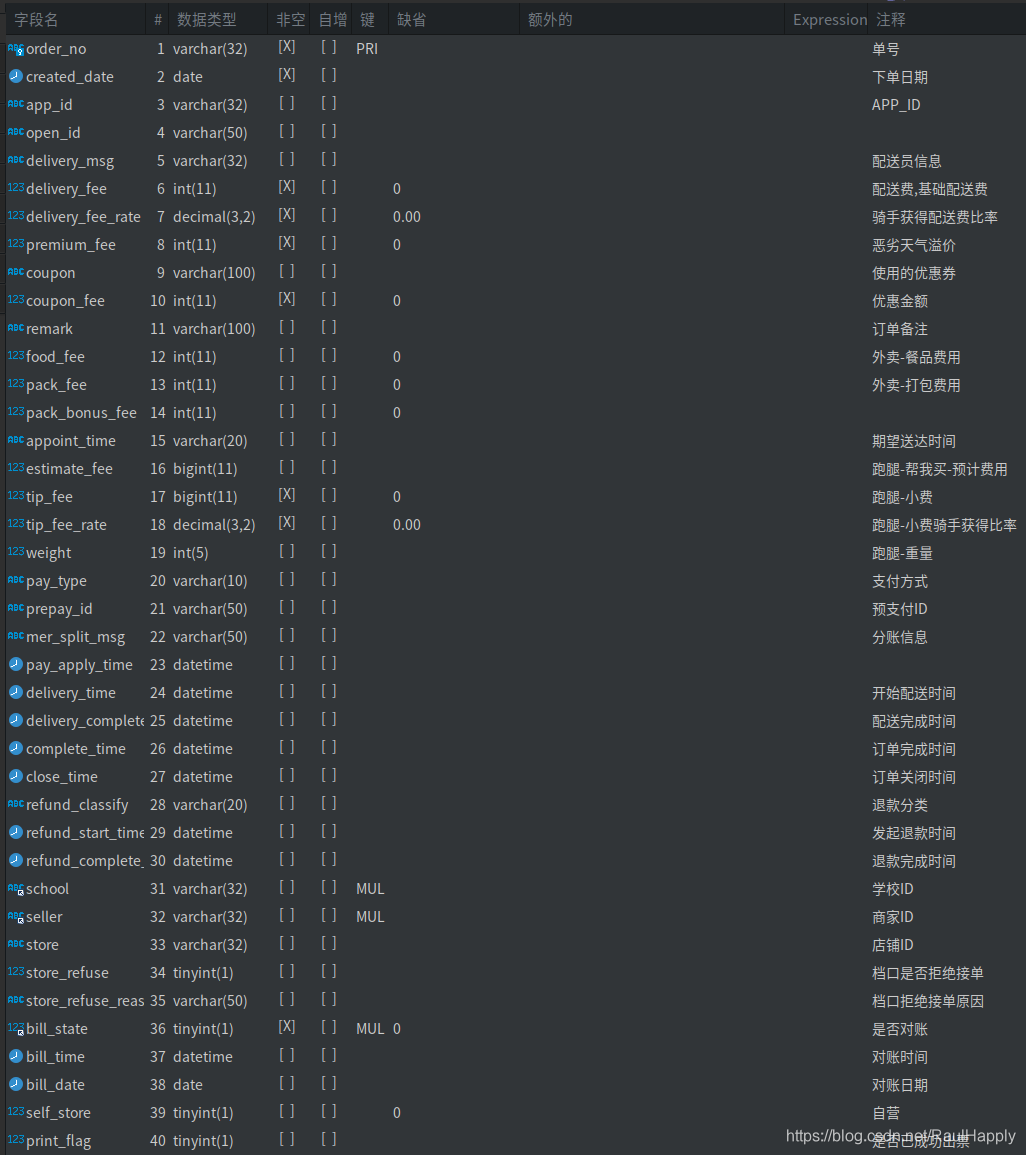
大约有六万多条数据。数据库脚本及数据备份可以点击下载
1. 最左前缀匹配原则
非常重要的原则,mysql会从左向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
创建一个索引
CREATE INDEX IDX_T_1 USING BTREE ON xa87_v2.t_xa87_order_info (store,delivery_msg,food_fee,delivery_fee);
我们执行一个sql
explain select * from t_xa87_order_info where delivery_msg='高玥静,17836031' and food_fee>1000;
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | t_xa87_order_info | NULL | ALL | NULL | NULL | NULL | NULL | 62017 | 3.33 | Using where |
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
在where中并没有store这个字段,所以不会使用IDX_T_1这个索引。
我们把store这个查询条件加上,看一下效果:
explain select * from t_xa87_order_info where store='f9fd2705ad1d740a4bef42833b487cea' and delivery_msg='高玥静,17836031' and food_fee=1000;
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | t_xa87_order_info | NULL | ref | IDX_T_1 | IDX_T_1 | 267 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
explain select * from t_xa87_order_info where store='f9fd2705ad1d740a4bef42833b487cea' and delivery_msg like '%17836031' and food_fee=1000;
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | t_xa87_order_info | NULL | ref | IDX_T_1 | IDX_T_1 | 131 | const | 633 | 1.11 | Using index condition |
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------+------+----------+-----------------------+
上面两个查询都用了IDX_T_1这个索引, 第一个效率更高, 因为第二个查询在delivery_msg条件上使用了like所以不再继续匹配food_fee
2. 选择区分度高的列作为索引
所谓区分度高就是指相同的值少。比如性别这个字段,只有男、女两个值,区分度很低,就不适合作为索引。
3. =、in 中的列可以乱序
explain select * from t_xa87_order_info where delivery_msg='高玥静,17836031' and food_fee=1000 and store='f9fd2705ad1d740a4bef42833b487cea';
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | t_xa87_order_info | NULL | ref | IDX_T_1 | IDX_T_1 | 267 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
我们把查询条件中的store放到最后,发现依然可以匹配到IDX_T_1这个索引,且效率和store在最前面的时候是一样的。
4. 索引列不参与计算
在created_date上创建一个索引
CREATE INDEX IDX_T_2 USING BTREE ON xa87_v2.t_xa87_order_info (created_date);
explain select * from t_xa87_order_info where created_date='2020-08-24';
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t_xa87_order_info | NULL | ref | IDX_T_2 | IDX_T_2 | 3 | const | 123 | 100.00 | NULL |
+----+-------------+-------------------+------------+------+---------------+---------+---------+-------+------+----------+-------+
explain select * from t_xa87_order_info where DATE_FORMAT(created_date,'%Y-%m-%d')='2020-08-24';
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | t_xa87_order_info | NULL | ALL | NULL | NULL | NULL | NULL | 62017 | 100.00 | Using where |
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
可以看到第一条查询语句使用了索引而第二天并没有。
5. 拓展索引,尽量不要新建索引
比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。