Python之Pandas模块讲解及案例
一、安装Pandas
pip install Pandas
二、简介
Pandas是一个开源的,BSD许可的库,为Python (opens new window)编程语言提供高性能,易于使用的数据结构和数据分析工具。
Pandas是NumFOCUS (opens new window)赞助的项目。这将有助于确保Pandas成为世界级开源项目的成功,并有可能捐赠 (opens new window)给该项目。
另外,获得 Pandas 的最佳方式是通过 conda(opens new window):
conda install Pandas
但是此方法安装较慢,不太推荐,可以直接pip。
三、Series类
1、Series对象的实现
Series对象是相当于一个一维的数组
方法1
import pandas as pd
"""
导入pandas模块
"""
ser_0 = pd.Series(data=[0, 1, 2, 3, 4, 5])
# data 参数表示:所取得的数值是多少
print(ser_0)
# output>
0 0
1 1
2 2
3 3
4 4
5 5
dtype: int64
# 第一列是索引(indexs)
# 第二列是数值(values)
方法2
import pandas as pd
ser_1 = pd.Series(data=[0, 1, 2, 3], index=['a', 'b', 'c', 'd'])
# index 表示自定义索引
print(ser_1)
# output>
a 0
b 1
c 2
d 3
dtype: int64
方法3
import pandas as pd
config = {
'one':1,
'two':2,
'three':3,
'four':4
}
# 字典
ser_2 = pd.Series(config)
print(ser_2)
# output>
one 1
two 2
three 3
four 4
dtype: int64
2、Head与Tail
head() 与 tail() 用于快速预览 Series 与 DataFrame,默认显示 5 条数据,也可以指定显示数据的数量。
这里先以Series为例,DataFrame会在后续讲解。
下面将用到numpy模块,关于numpy模块的讲解可以参见我的另一篇博文:
python 之 numpy 模块详细讲解及其应用案例
链接:
https://blog.csdn.net/m0_54218263/article/details/114272263
import pandas as pd
import numpy as np
index_list = list('abcdefghijklmnopqrst')
data_list = np.arange(20)
ser = pd.Series(data=data_list, index=index_list)
print(ser.head())
print(ser.head(3))
print(ser.tail())
print(ser.tail(3))
# output>
a 0
b 1
c 2
d 3
e 4
dtype: int32
a 0
b 1
c 2
dtype: int32
p 15
q 16
r 17
s 18
t 19
dtype: int32
r 17
s 18
t 19
dtype: int32
3、属性与底层数据
index属性
values属性
import pandas as pd
ser = pd.Series(data=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10], index=['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'j', 'k', 'l'])
print(ser.index)
print(ser.values)
# output>
Index(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'j', 'k', 'l'], dtype='object')
[ 0 1 2 3 4 5 6 7 8 9 10]
4、Series对象的切片操作
实际上,Series对象的切片与数组的切片差别并不大。
import pandas as pd
ser = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 11])
print(ser[0])
print(ser[1:7])
print(ser[0:8:2])
print(ser[:])
print(ser[-5:-2])
# output>
1
1 2
2 3
3 4
4 5
5 6
6 7
dtype: int64
0 1
2 3
4 5
6 7
dtype: int64
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 0
10 11
dtype: int64
6 7
7 8
8 9
dtype: int64
5、Series对象的一些常用方法
1、Series.index
索引
2、Series.values
数值
3、Series.drop(index)
删除某一个数据
4、Series.sum
求所有元素的和
等
四、DataFrame类
1、DataFrame对象的实现
方法1
import pandas as pd
df = pd.DataFrame([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
print(df)

方法2
import pandas as pd
df = pd.DataFrame(data=[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]], index=['a', 'b'])
print(df)

方法3
import pandas as pd
config={
'a': [1, 2, 3, 4, 5],
'b': [4, 5, 6, 7, 8],
'c': [2, 4, 6, 8, 10]
}
df = pd.DataFrame(data=config,index=['one', 'two', 'three', 'four', 'five'])
print(df)

2、DataFrame的取值以及切片
1、取值
Head、 Tail 方法
import pandas as pd
config = {
'a': [0, 1, 2, 3, 4, 5, 6, 7],
'b': [8, 9, 10, 11, 12, 13, 14, 15],
'c': [3, 6, 9, 11, 13, 15, 17, 19],
'd': [2, 4, 6, 9, 12, 14, 16, 18,]
}
df = pd.DataFrame(data=config, index=['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
print(df)
print(df.head())
print(df.tail())
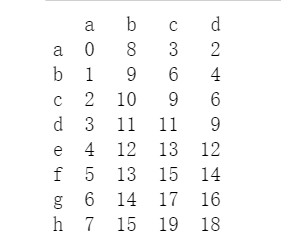
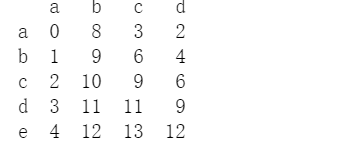
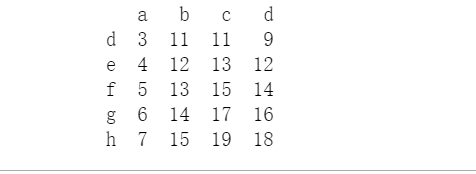
某一个位置处的值:
import pandas as pd
config = {
'a': [0, 1, 2, 3, 4, 5, 6, 7],
'b': [8, 9, 10, 11, 12, 13, 14, 15],
'c': [3, 6, 9, 11, 13, 15, 17, 19],
'd': [2, 4, 6, 9, 12, 14, 16, 18,]
}
df = pd.DataFrame(data=config, index=['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
print(df.a.a)
print(df.a.b)
print(df.c.f)
# 实际上是相当于取出字典中的数据的类似方法,
# 先去取一列,
# 再从这一列中去取出来某一行的数据点。
# output>
0
1
15
2、切片
1、行切片
import pandas as pd
config = {
'a': [0, 1, 2, 3, 4, 5, 6, 7],
'b': [8, 9, 10, 11, 12, 13, 14, 15],
'c': [3, 6, 9, 11, 13, 15, 17, 19],
'd': [2, 4, 6, 9, 12, 14, 16, 18,]
}
df = pd.DataFrame(data=config, index=['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
print(df[0:4])
# 从第零行切刀第三行数据
print(df['a':'c'])
# 从下标为 a 的行一直切到下标为 b 的行


2、列切片
import pandas as pd
config = {
'a': [0, 1, 2, 3, 4, 5, 6, 7],
'b': [8, 9, 10, 11, 12, 13, 14, 15],
'c': [3, 6, 9, 11, 13, 15, 17, 19],
'd': [2, 4, 6, 9, 12, 14, 16, 18,]
}
df = pd.DataFrame(data=config, index=['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
print(df.a)
print(df.b)
print(df.c)
# output>
a 0
b 1
c 2
d 3
e 4
f 5
g 6
h 7
Name: a, dtype: int64
a 8
b 9
c 10
d 11
e 12
f 13
g 14
h 15
Name: b, dtype: int64
a 3
b 6
c 9
d 11
e 13
f 15
g 17
h 19
Name: c, dtype: int64
3、举一个例子,利用以上的类以及numpy来实现一个时间列表
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df)
print(df.dtypes)
# 查看类型
print(df.describe())
# 查看对数据的统计结果
# output>
A B C D
2013-01-01 -1.177484 0.516432 -0.425316 -0.499715
2013-01-02 -0.128610 -1.052472 -0.151716 -0.019494
2013-01-03 0.257262 -0.857907 0.111126 -1.584577
2013-01-04 0.383851 -0.952546 -0.867269 -0.760178
2013-01-05 1.489054 -0.727922 -0.190620 0.230165
2013-01-06 -0.210085 1.699750 -0.100482 -0.784437
A float64
B float64
C float64
D float64
dtype: object
A B C D
count 6.000000 6.000000 6.000000 6.000000
mean 0.102332 -0.229111 -0.270713 -0.569706
std 0.873513 1.106510 0.339157 0.641838
min -1.177484 -1.052472 -0.867269 -1.584577
25% -0.189716 -0.928886 -0.366642 -0.778372
50% 0.064326 -0.792915 -0.171168 -0.629947
75% 0.352204 0.205343 -0.113291 -0.139549
max 1.489054 1.699750 0.111126 0.230165


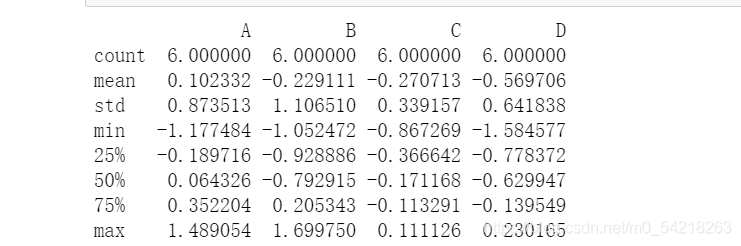
这里就是一个简单的介绍了,也就是一个入门简介,更深入的学习可以参考官方文档,链接如下:
https://www.pypandas.cn/docs/getting_started/tutorials.html#%E5%AE%98%E6%96%B9%E6%8C%87%E5%8D%97
谢谢大家的阅读 !! ~~~