在大数据集群搭建过程中,HBASE是使用noSQL(非关系型数据库)重要的利器,但是Hmaster使用start-hbase.sh启动后又闪退,今天是周六我来一探究竟。
问题现象复现
ERROR org.apache.hadoop.hbase.master.HMasterCommandLine: Failed to start master
java.lang.RuntimeException: HMaster Aborted然后Hmaster在进程中JPS不到,但是当使用start-hbase.sh的时候,又会提示有这个进程,需要先kill。
根据网络收集的资料,推测大致原因如下:
1. 未将hdfs中的core-site.xml以及hdfs-site.xml文件拷贝至hbase/conf文件夹下
2. 在进行节点部署时对于某台机器由于所部署的组件过多导致在启动中内存分配不足
3. 由于hdfs启动中产生数据和hbase不同步导致
我们看到第1,3原因都和hdfs有关,所以我先搭建一个伪分布式(使用linux自带的file系统作为存储,使用自带的zookeeper组件作为管理)。
搭建步骤如下:
#!/bin/bash
INSTALL_PATH=/opt/hbase
INSTALL_TAR=$(find ./ -name hbase*)
tar -zxvf ${INSTALL_TAR}
mv ./hbase* ./hbase
#手动cp hbase-env.sh和hbase-site.xml覆盖conf文件夹下同名
#删除tar和配置
echo "##HBASE_HOME @ `date` @ by YuanYihan" >>/etc/profile
echo "export HBASE_HOME=/opt/hbase">>/etc/profile
echo "export PATH=\$PATH:\$HBASE_HOME/bin">>/etc/profile
source /etc/profile
#0。ip网络hosts,jdk
#1.上传tar安装包并解压;
#2、hbase-env.sh中配置JAVA_HOME
#3、copy 配置
echo "hbase:::@ by YuanYihan#done!"其中两个配置文件中,我修改的地方为:
########hbase-env.sh#######第29行左右添加source语句(懒得写javahome了)####
# The java implementation to use. Java 1.6 required.
source /etc/profile
#export JAVA_HOME=/usr/java/jdk1.6.0/
########hbase-env.sh#######第117行左右定义了文件夹(tmp文件我认为不靠谱)####
# The directory where pid files are stored. /tmp by default.
export HBASE_PID_DIR=$HBASE_HOME/pids
########hbase-env.sh#######第124行左右定义ZK的使用,当然默认就是true####
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=true<!-- hbase-site.xml文件中定义了几个目录文件 -->
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///var/yyh/hbase/hbase_local/rootdir</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/var/yyh/hbase/hbase_local/zookeeper</value>
</property>
</configuration>本地测试结论
这么搭建的依托于linux本身的文件系统,不依靠HDFS文件系统,结果测试仍然是hmaster闪退,于是可以判断:至少我的电脑的闪退和HDFS集群没有太大关系
那么进行深入的测试结果如下:
1)今天上午排查了问题发现处于active的NN和Hmaster在一台电脑上,那么这Hmaster容易挂。
2)强行杀掉第一台的NN(杀zkfc),然后在第一台起hmaster以后都没有问题了(不会被挂掉)。
基于以上两点特征,我认为是内存资源不足造成的影响比较大。
解决办法的提出
考虑到是内存等因素,解决办法为改善集群的结构,使其变为如下的结构关系,减少第一个虚拟机的设备负载:
新的集群结构
| 虚拟机 | hdfs及ZK角色 | Yarn及HIVE角色 | Hbase角色 | 对外端口 |
| yyh1 | HIVEC | HM,HR,HZK(自带) |
60010 | |
| yyh2 | NN,DN,JN,ZK,ZKFC | NM,HIVEC | 50070,8020 | |
| yyh3 | DN,JN,ZK | NM,RM,HIVES | 8088,10000,9083 | |
| yyh4 | DN,JN,ZK | NM,MYSQL,HIVEC,RM | 3306,8088 |
集群搭建完毕,使用如下步骤进行集群启动:
新的集群的启动顺序
新集群启动顺序如下步骤
1:【自动脚本:防火墙关闭,ntp对时】【yyh4里面的Mysql】---本部分不需要操作
2:zookeeper 【yyh2,3,4】zkServer.sh start ---status --stop
3:Hapdoop:【yyh2】start-all.sh { start-dfs.sh start-yarn.sh}----stop-all.sh
4:RM:【yyh3,yyh4】yarn-daemon.sh start resourcemanager---
5:HIVES:【如果yyh1-3要用请在yyh3】hive --service metastore其余hive或hiveservice2 其余BEELINE过来
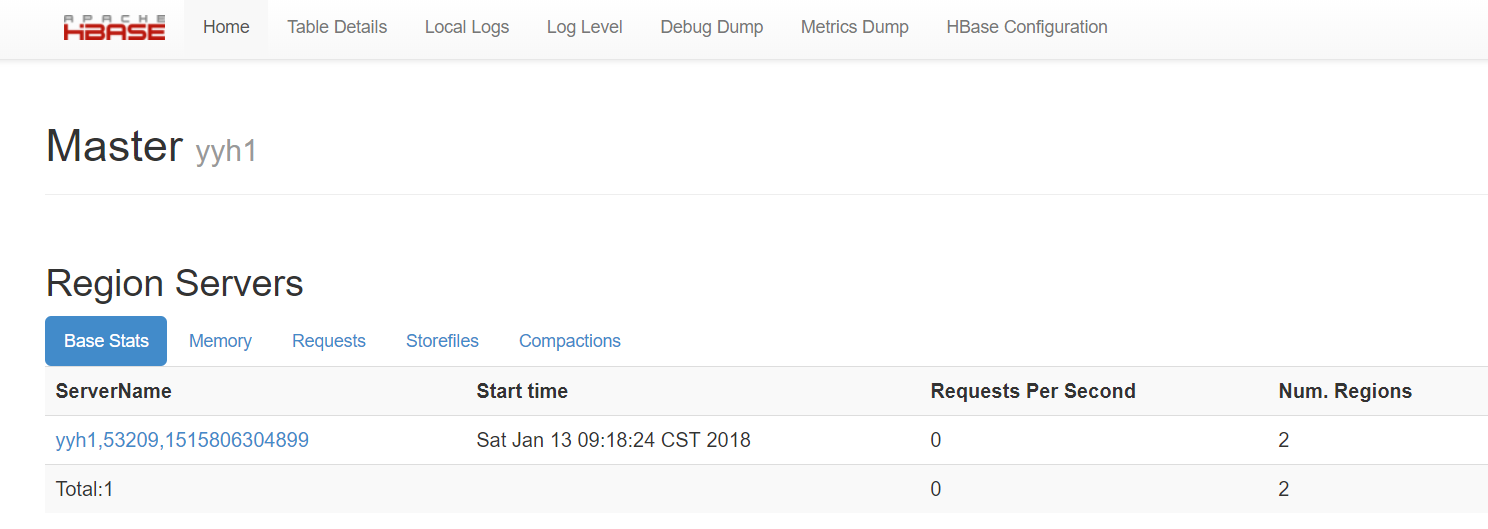
6:HBASE:【yyh1】start-hbase.sh 然后 hbase shell
新集群测试结果
HDFS:
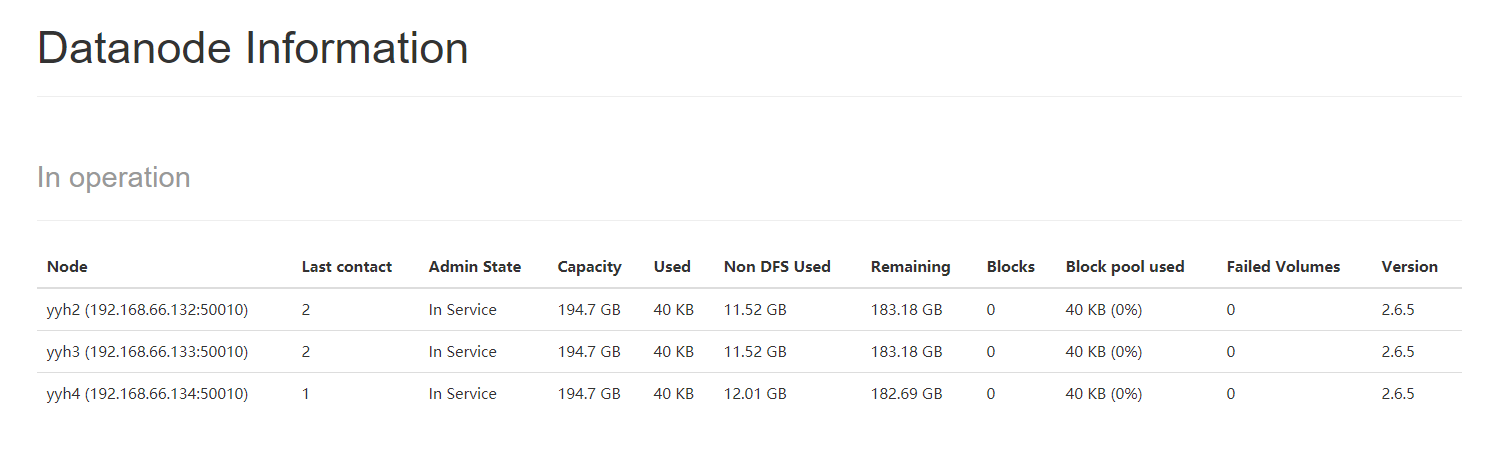
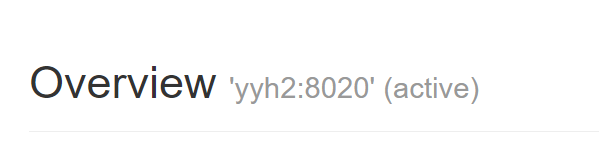
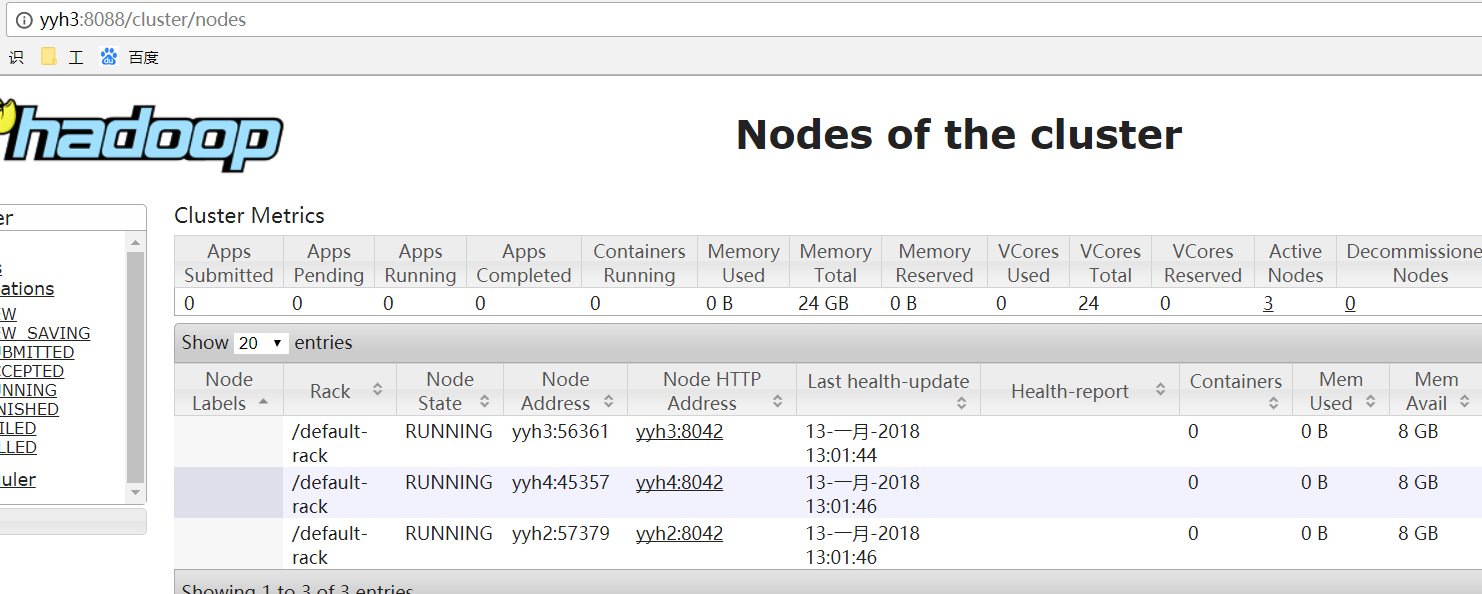
YARN:
HIVE:
HBASE: