东阳的学习笔记
文章目录
- 12种常见方案
-
- 方案1( `fork()-per-client`)
- 方案2(`thread-per-connection`)
- 方案3和方案4
- 方案5(单线程Reactor)
- 方案6(reactor + thread-per-task)
- 方案7(reactor + worker thread)
- 方案8(reactor + thread poll)
- 方案9(Reactors in threads)
- 方案10(Reactors in processes)
- 方案11(reactors + thread poll)
- `one or more?(event loop(s))`
- 将高优先级的TCP连接交给单独的 event loop来处理
12种常见方案
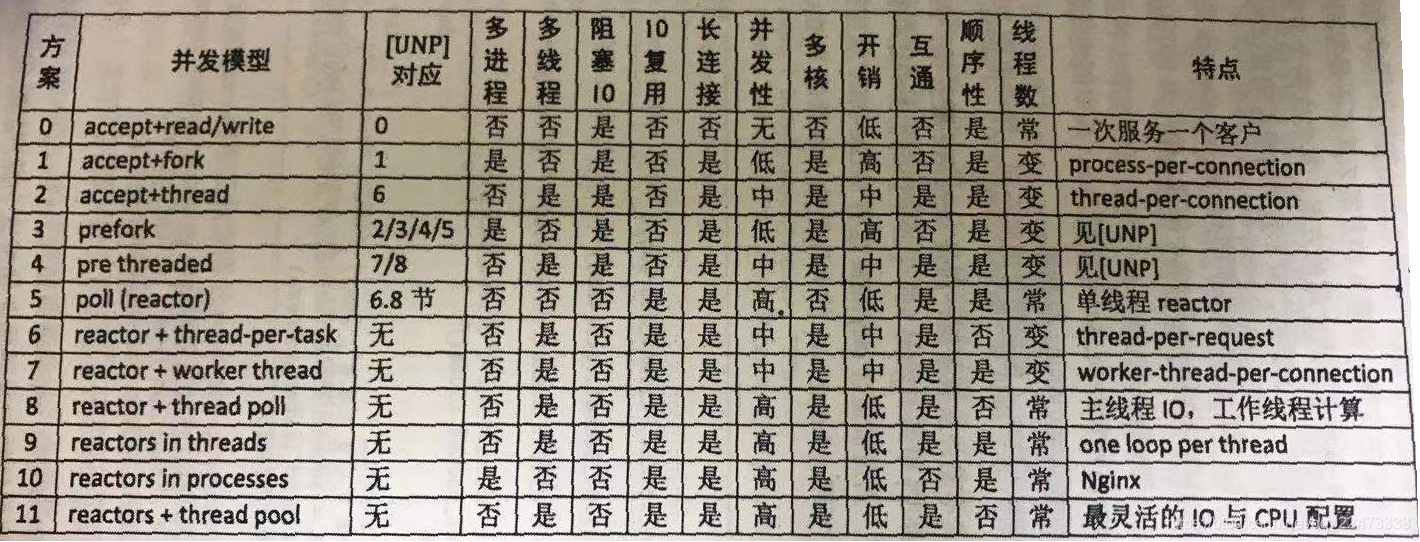
下表是作者总结的12种常见方案,其中:
- 互通:开发chat服务时,多个客户连接之间是否能方便地交换数据
- 顺序性:在 httpd/Sudoku 这类请求相应服务中,如果客户连接发送多个请求,那么计算得到的多个响应是否按
相同的顺序发还给客户(这里指的是自然状态下,不含刻意同步)。
方案1( fork()-per-client)
传统的 Unix 并发网络编程方案,[UNP]称之为 child-per-client 或 fork()-per-client,另外也俗称 process-per-connection。这种方案:
- 适合并发连接数不大的情景。
- 适合响应的工作量远大于 fork 的开销。(比如数据库服务器)
- 适合长连接,但不适合短连接
#!/usr/bin/python
from SocketServer import BaseRequestHandler, TCPServer
from SocketServer import ForkingTCPServer, ThreadingTCPServer
class EchoHandler(BaseRequestHandler):
def handle(self):
print "got connection from", self.client_address
while True:
data = self.request.recv(4096)
if data:
sent = self.request.send(data) # sendall?
else:
print "disconnect", self.client_address
self.request.close()
break
if __name__ == "__main__":
listen_address = ("0.0.0.0", 2007)
server = ForkingTCPServer(listen_address, EchoHandler)
server.serve_forever()
方案2(thread-per-connection)
这是传统的 Java 网络编程方案 thread-per-connection,在 Java 1.4 引入 NIO 之前,Java 网络服务多采用这种方案:
- 开销比方案1小不少
- 仍然不适合短连接
- 这种方案的伸缩性
受线程数的限制
#!/usr/bin/python
from SocketServer import BaseRequestHandler, TCPServer
from SocketServer import ForkingTCPServer, ThreadingTCPServer
class EchoHandler(BaseRequestHandler):
def handle(self):
print "got connection from", self.client_address
while True:
data = self.request.recv(4096)
if data:
sent = self.request.send(data) # sendall?
else:
print "disconnect", self.client_address
self.request.close()
break
if __name__ == "__main__":
listen_address = ("0.0.0.0", 2007)
# 这里改了
server = ThreadingTCPServer(listen_address, EchoHandler)
server.serve_forever()
方案3和方案4
方案3是对方案1的优化,方案4是对方案2的优化。这两种方案都是 Apache httpd 长期使用的方案
以上几种方案都是
阻塞式网络编程,程序流程( thread of control )通常阻塞在 read()上
但 TCP 是哥全双工协议,同时支持 read() 和 write() 操作:
- TCP连接在读的时候如何同时写数据?
- client 同时从 网络 和 stdin 读?
一种解决的办法是采用 IO 复用。也就是 select、poll、epoll、kqueue等一系列的 “多路选择器”,让一个 thread of control能处理多个连接。
- 复用的不是IO连接而是线程
- 使用 select/poll 几乎肯定需要配合
non-blocking IO - 使用
non-blocking IO肯定要配合使用应用层buffer
还好有现成的方案可以帮助我们解决上面这些麻烦事——Reactor模式是不错的选择。现在也有许多通用库,比如 libevent、muduo、Netty、Twisted、POE供我们选择。
Reactor在另一篇博客中有提到:常见的5种IO模式扫描二维码关注公众号,回复: 12836304 查看本文章
一个Python示例
下面的代码并没有开启
non-blocking,也没有考虑数据发送不完整(&28)。
首先定义一个文件描述符到 socket 的映射(&14)
程序的主体是一个事件循环(&15~&22)
每当有IO事件发生时,就针对不同的文件描述符执行不同的操作。(&16, &17)
对于 listening fd,接受(accept)新连接,并注册到 IO 事件关注列表(watch list),让后把连接添加到 connections 字典中(&18~&23)
对于客户连接,则读取并回显数据,处理连接的关闭(&24~&32)#!/usr/bin/python import socket import select server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) server_socket.bind(('', 2007)) server_socket.listen(5) # server_socket.setblocking(0) poll = select.poll() # epoll() should work the same poll.register(server_socket.fileno(), select.POLLIN) connections = { } while True: events = poll.poll(10000) # 10 seconds for fileno, event in events: if fileno == server_socket.fileno(): (client_socket, client_address) = server_socket.accept() print "got connection from", client_address # client_socket.setblocking(0) poll.register(client_socket.fileno(), select.POLLIN) connections[client_socket.fileno()] = client_socket elif event & select.POLLIN: client_socket = connections[fileno] data = client_socket.recv(4096) if data: client_socket.send(data) # sendall() partial? else: poll.unregister(fileno) client_socket.close() del connections[fileno]
但是像上面这样将业务代码隐藏在一个大循环中的做法器是对于将来功能的扩展和代码的维护都十分不利。
Rector模式的意义是:将消息分发到用户提供的处理函数,并保持网络部分的通用代码不变,独立于用户的处理逻辑。
单线程Reactor
单线程的 Reactor 的程序执行顺序如下图(左)所示。在没有事件的时候,线程等待在 select / poll / epoll_wait 上。事件到达后由网络库处理IO,再把消息通知(回调)客户端代码。Reactor 事件循环所在的线程通常叫
IO线程。通常由网络库负责读写 socket,用户代码负责解码、计算、编码。注意由于只有一个线程,因此事件是顺序处理的,一个线程同时只能做一件事情。在这种协作式多任务中,事务的
优先级得不到保证,因为从 “poll返回之后”,到下一次调用 “poll进入等待之前“这段时间内,线程不会被其他连接上的数据或事件抢占。
如果我们想要延迟计算,应该注册超时回调,而不能使用 sleep

方案5(单线程Reactor)
本文以方案5作为对比其他方案的基准,这种方案:
优点:
- 由网络库搞定数据收发,程序只关心业务逻辑
缺点:
- 适合IO密集应用,不太适合CPU密集应用,因为较难发挥多核CPU的威力
- 与方案2相比,方案5处理网络消息的延迟可能要略大一点,因为多了一次
poll系统调用
Reactor 代码示意
- 为了节省空间,直接使用了全局变量,也没有处理异常
- 程序的核心仍然是事件循环(&42~&46)
- 事件的处理通过
handle转发到各个函数中去,而不是集中在一坨
- listening fd 的处理函数是 handle_accept,它会注册客户连接的 handle。
- 普通客户连接的处理函数是 handle_request,其中又把连接断开和数据到达这两个事件分开
注意:在使用非阻塞IO + 事件驱动方式编程的时候,一定要注意避免在事件回调中执行耗时的操作,包括阻塞 IO 等,否则会影响程序的响应。这和 Windows GUI 消息循环十分类似。#!/usr/bin/python import socket import select server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) server_socket.bind(('', 2007)) server_socket.listen(5) # serversocket.setblocking(0) poll = select.poll() # epoll() should work the same connections = { } handlers = { } def handle_input(socket, data): socket.send(data) # sendall() partial? def handle_request(fileno, event): if event & select.POLLIN: client_socket = connections[fileno] data = client_socket.recv(4096) if data: handle_input(client_socket, data) else: poll.unregister(fileno) client_socket.close() del connections[fileno] del handlers[fileno] def handle_accept(fileno, event): (client_socket, client_address) = server_socket.accept() print "got connection from", client_address # client_socket.setblocking(0) poll.register(client_socket.fileno(), select.POLLIN) connections[client_socket.fileno()] = client_socket handlers[client_socket.fileno()] = handle_request poll.register(server_socket.fileno(), select.POLLIN) handlers[server_socket.fileno()] = handle_accept while True: events = poll.poll(10000) # 10 seconds for fileno, event in events: handler = handlers[fileno] handler(fileno, event)
方案6(reactor + thread-per-task)
这是一个过渡方案,收到 Sudoku 请求之后,不在 Reactor 线程计算,而是创建一个新的线程去计算。这是非常初级的多线程应用。
- 它为每个请求(而不是每个连接)创建了一个新的线程。(这个开销可以用线程池去避免,即方案8)
- 这个方案是
out of order的,即同时创建多个线程去计算同一个连接上收到的多个请求,其算出结果的次序是不确定的- 这也是一开始协议设计时使用了 id 的原因,方便对应
方案7(reactor + worker thread)
为了让返回结果的顺序确定,方案7为每个连接创建一个计算线程,每个连接上的请求固定发给同一个线程去算,先到先得。
- 过渡方案
- 并发连接数受限于线程数目
- 或许不如直接使用阻塞IO的
thread-per-connection的方案2
方案7与方案6的对比
- 方案6中,对于某一个TCP连接上发送的一长串突发请求,可能会占满全部8个core
- 方案7,最多占用12.5%的CPU资源。
- 这两种方案各有优劣,取决于应用场景的需要(到底时公平性重要还是突发性能重要)
需要根据实际的应用场景做取舍
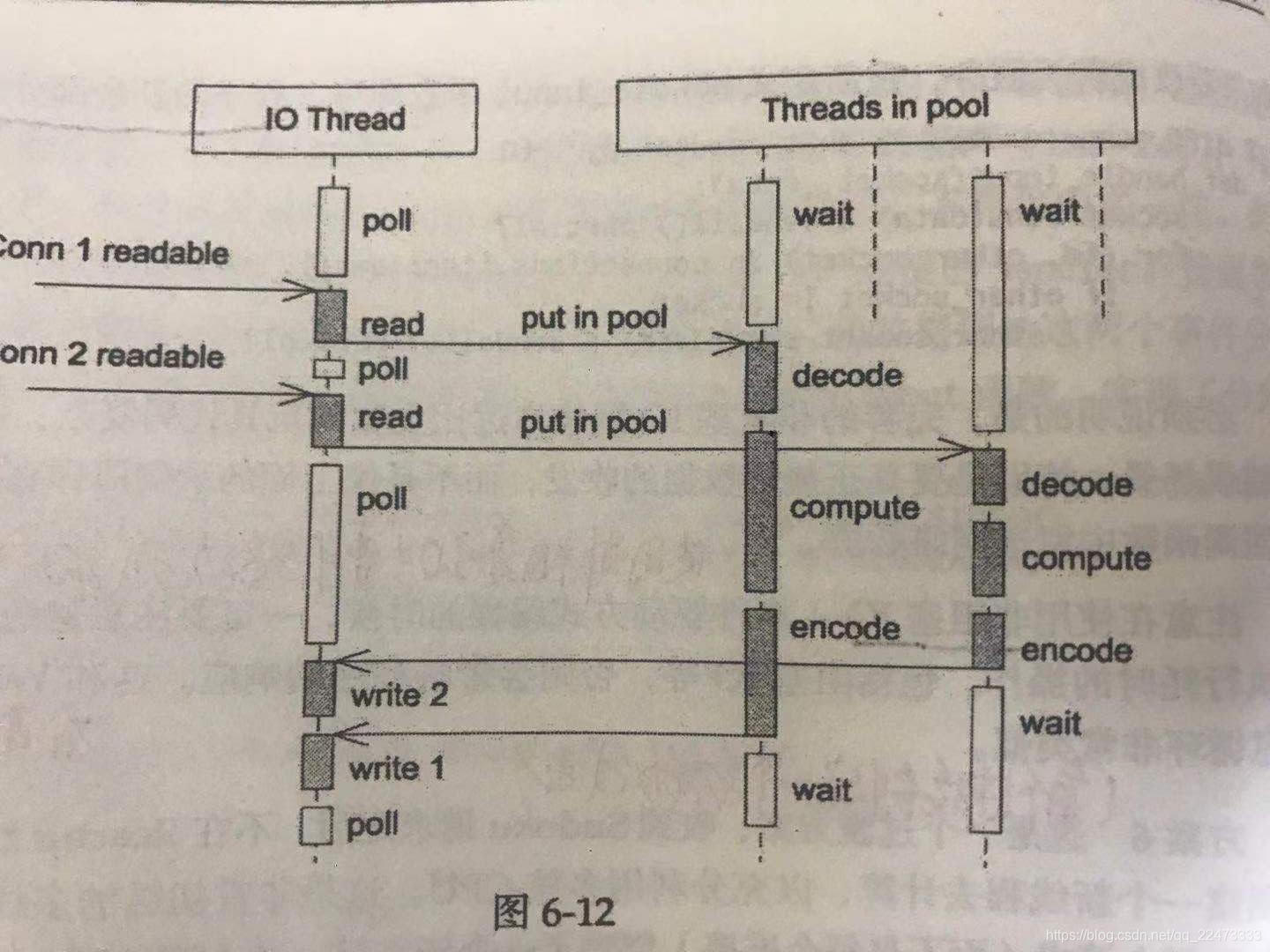
方案8(reactor + thread poll)
为了弥补方案6中为每个请求创建线程的缺陷,方案8使用了固定的线程池。
程序结构如图所示:
- 全部的IO工作都在一个Reactor线程完成,而计算任务交给
thread poll。- 如果
计算任务彼此独立,而且IO的压力不大,这种方案是非常适用的。有乱序返回的可能,需要根据 ID 来匹配响应
代码示例
- 线程池的另外一个作用是执行阻塞操作(
即我们可以将阻塞操作从IO线程移到线程池中),比如数据库操作。这样不会影响客户连接- 如果 IO 压力比较大,一个Reactor处理不过来,则可考虑方案9.
void onMessage(const TcpConnectionPtr& conn, Buffer* buf, Timestamp) { // ...... if (!processRequest(conn, request)) { conn->send("Bad Request!\r\n"); conn->shutdown(); break; } // ...... } bool processRequest(const TcpConnectionPtr& conn, const string& request) { // ...... if (puzzle.size() == implicit_cast<size_t>(kCells)) { threadPool_.run(std::bind(&solve, conn, puzzle, id)); } // ...... }
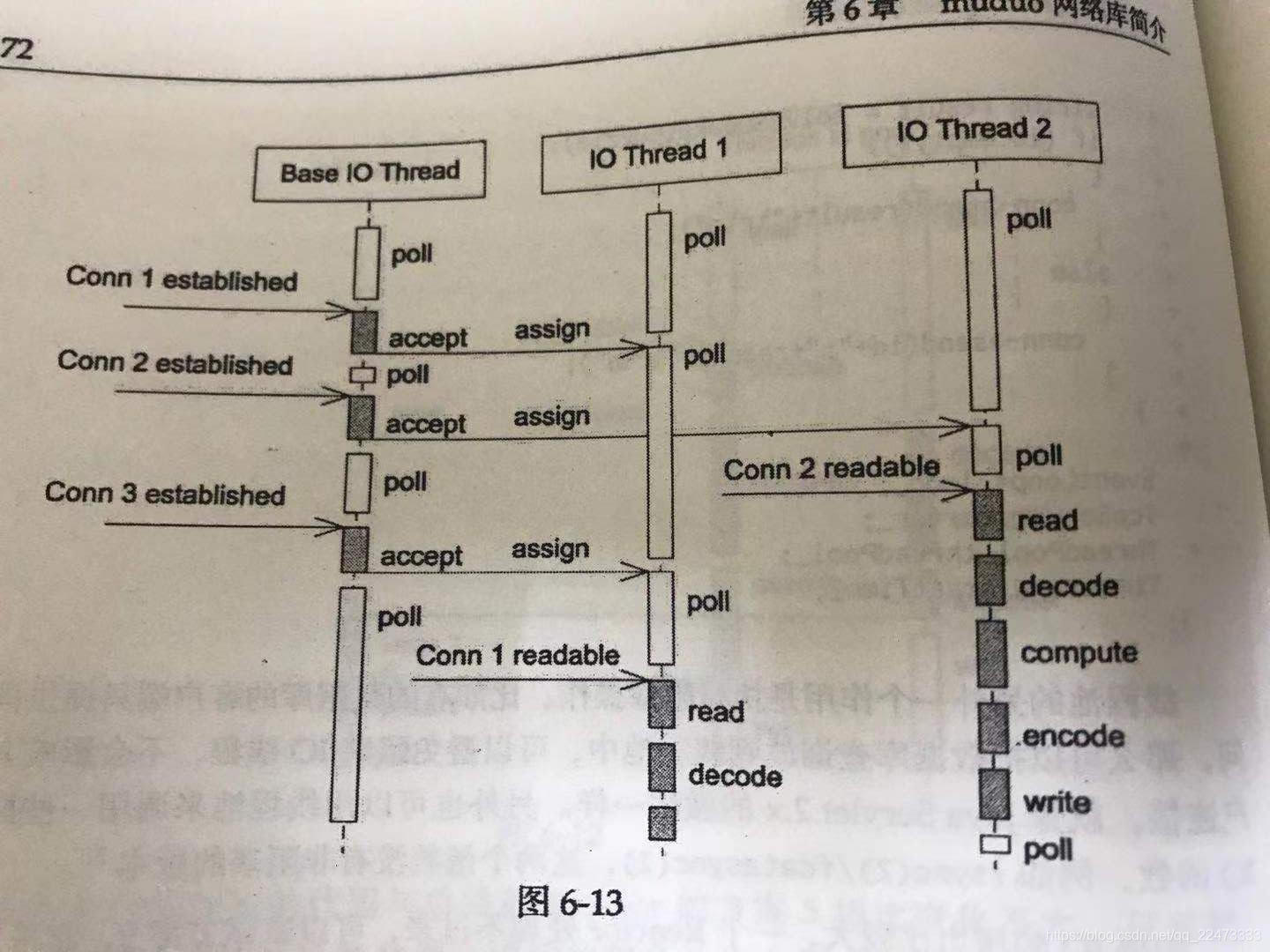
方案9(Reactors in threads)
这是 muduo 内置方案,也是Netty内置的多线程方案。它的特点是:
one loop per thread。有一个Main Reactor负责 accept(2)连接,然后把连接挂在某个Sub Reactor中- 这样该连接的所有操作都在这个
sub Reactor所处的线程中完成。多个连接可被分配到多个线程中,以充分利用CPU (起到类似负载均衡的效果)
muduo采用的固定大小的Reactor Poll,池子的大小根据CPU确定。
这种方案能够把 IO 分配给多个线程,防止一个 Reactor 出现饱和
相比较方案8,减少了进出 thread poll 的两次上下文转换(因为方案9的请求的返回是有序的)
适应性很强,是 muduo 的默认线程模型
代码示例
SudokuServer(EventLoop* loop, const InetAddress& listenAddr, int numThreads) : server_(loop, listenAddr, "SudokuServer"), numThreads_(numThreads), startTime_(Timestamp::now()) { server_.setConnectionCallback( std::bind(&SudokuServer::onConnection, this, _1)); server_.setMessageCallback( std::bind(&SudokuServer::onMessage, this, _1, _2, _3)); server_.setThreadNum(numThreads); // 与server_basic.cc的为一差别 }
方案10(Reactors in processes)
- 这是 Nginx 的内置方案。如果连接之间无交互,这种方案也是很好的选择。工作进程之间相互独立
可以热升级
方案11(reactors + thread poll)
- 将方案8和方案9相结合
- 即既使用多个 Reactor来处理 IO,又使用线程池来处理计算。
- 适合既有突发 IO(利用多线程处理多个连接上的IO), 又有突发计算的应用(利用线程池把一个连接上的计算任务分配给多个线程去做)
在 muduo 中使用方案11只需要把方案8的代码加上一行 server_.setThreadNum(numThreads);
one or more?(event loop(s))
- ZeroMQ的手册给出的建议是:
按照每千兆比特每秒的吞吐量配一个 event loop 的经验来设置 event loops的数目。按照这条经验:
- 在编写运行于千兆以太网上的网络程序时,用一个event loop 就够了
- 如果程序本身没有多少计算量,而主要瓶颈在网络带宽,则可以按照这条规则来办,即只用一个 event loop
- 如果程序的
IO带宽较小,计算量较大,而且对延迟不敏感,那么可以把计算放到thread pool,也可以只用一个 event loop.
将高优先级的TCP连接交给单独的 event loop来处理
在muduo中,属于同一个 event loop 的连接之间没有优先级的差别,这样做是为了
防止优先级反转。
- 比如说一个服务程序有10个心跳连接,有10个数据连接请求都属于一个 event loop。按理说,心跳连接应该被优先处理
但是:如果数据请求先于心跳连接到达,那么这个 event loop 就会调用相应的 event handle 去处理数据请求。这样心跳连接就必须等下一次 epoll_wait() 的时候再来处理