一、response.getWriter().write()和 response.getWriter().print()的区别
response.getWriter()返回的是PrintWriter,这是一个打印输出流
response.getWriter().write()和 response.getWriter().print()是响应给客户端的东西,如果不用ajax接收将数据放在合适的位置,就会在浏览器上生成一个新的页面来显示内容。
-
print
response.getWriter().print(),不仅可以打印输出文本格式的(包括html标签),还可以将一个对象以默认的编码方式转换为二进制字节输出 -
writer
response.getWriter().writer(),只能打印输出文本格式的(包括html标签),不可以打印对象
二、常见乱码问题分析
1、中文变成看不懂的字符
如果一串中文字符变成了一串看不懂的字符如:“Ì Ô £ ¡Î Ò Ï²»¶ £ ¡”,这种情况通常是编码
字符集与解码时所用的字符集不一致所造成的。比如使用GBK编码,如果使用ISO-8859-1解码
的话结果就是这样。
2、一个汉字变成了一个问号
如果编码和解码的字符集都是一致的,那么可以确定该字符编码不支持中文,例如:ISO-8859-1
3、一个汉字变成了两个问号
中文经过多次编码且其中有一次编码或者解码使用了不支持中文的字符集
三、乱码相关知识点:
1.UTF-8国际编码,GBK中文编码。GBK包含GB2312,即如果通过GB2312编码后可以通过GBK解码,反之可能不成立;
2、web tomcat:默认是ISO8859-1,不支持中文的
3.java.nio.charset.Charset.defaultCharset() 获得平台默认字符编码;
4.getBytes() 是通过平台默认字符集进行编码;
5.码表:是一种规则,用来让我们看得懂的语言转换为电脑能够认识的语言的一种规则,有很多中码表,IS0-8859-1,GBK,UTF-8,UTF-16等一系列码表,比如GBK,UTF-8,UTF-16都可以标识一个汉字,而如果要标识英文,就可以用IS0-8859-1等别的码表。
6.编码:将我们看得懂的语言转换为电脑能够认识的语言。这个过程就是编码的作用
7.解码:将电脑认识的语言转换为我们能看得懂得语言。这个过程就是解码的作用
浏览器使用的是UTF-8码表,通过http协议传输,http协议只支持IS0-8859-1,到了服务器,默认也是使用的是IS0-8859-1的码表,看图
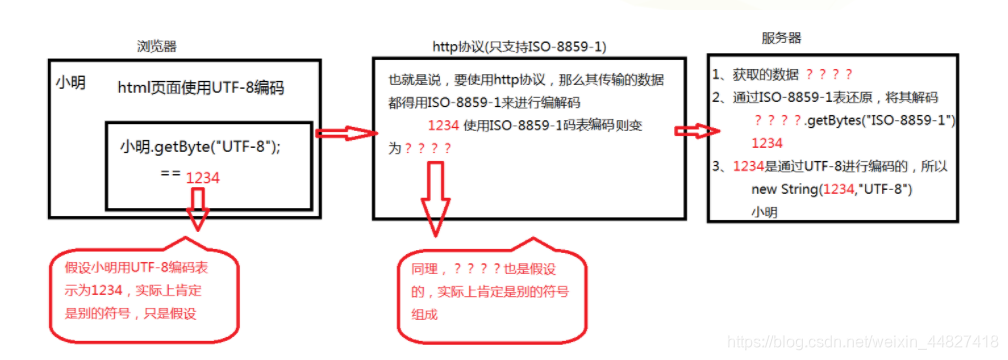
也就是三个过程,经历了两次编码,所以就需要进行两次解码,
1、浏览器将"小明"使用UTF-8码表进行编码(因为小明这个是汉字,所以使用能标识中文的码表,这也是我们可以在浏览器上可以手动设置的,如果使用了不能标识中文的码表,那么就将会出现乱码,因为码表中找不到中文对应的计算机符号,就可能会用??等其他符号表示),编码后得到的为 1234 ,将其通过http协议传输。
2、在http协议传输,只能用ISO-8859-1码表中所代表的符号,所以会将我们原先的1234再次进行一次编码,这次使用的是ISO-8859-1,得到的为 ??? ,然后传输到服务器
3、服务器获取到该数据是使用UTF-8编码的,而tomcat服务器默认使用ISO-8859-1解码,由于编码和解码所使用的字符集不一致,所以会出现乱码问题。
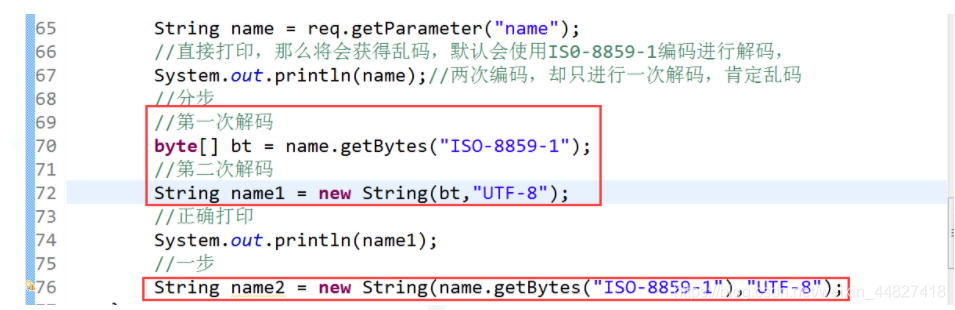
解决方案: 如果我们在客户端使用UTF-8编码的JSP页面发出请求,浏览器编码后的UTF-8字节会以ISO-8859-1的形式传递到服务器端。所以要得到经HTTP协议传输的原始字节,我们需要先调用getBytes(“ISO-8859-1”)得到原始的字节,但由于我们客户端的原始编码是UTF-8,如果继续按照ISO-8859-1解码,那么得到的将不是一个中文字符,而是3个乱码的字符。所以我们需要再次调用new String(bytes,“UTF-8”),将字节数组按照UTF-8的格式,每3个一组进行解码,才能还原为客户端的原始字符。
???.getBytes(“ISO-8859-1”);//第一次解码,转换为电脑能够识别的语言,
new String(1234,“UTF-8”);//第二次解码,转换为我们认识的语言
四、Servlet相关的几种乱码
1、 浏览器调用jsp,html等页面中文显示乱码
解决这类乱码需要满足两个要求:
1)文件本身是以utf-8编辑保存的(myEclipse中在properties中鼠标右键选择utf-8)
2)浏览器用utf-8解析:
(手动)==> 在浏览器中右键选择编码格式为utf-8
(智能)==> 在文件中写入如: 通过标签模拟response头,起到告诉浏览器用utf-8的编码解析
(智能)==> response.setContentType(“text/html;charset=UTF-8”);起到告诉浏览器用utf-8的编码解析
常用:
<meta name="content-type" content="text/html; charset=UTF-8">或<meta charset="utf-8">
<%@ pageEncoding="utf-8"%>
<?xml encoding="UTF-8"?>
2、通过浏览器调用servlet,页面显示乱码。
Servlet乱码分为request乱码和response乱码:
(1)response响应回浏览器出现的中文乱码:
首先介绍一下,response对象是如何向浏览器发送数据的。两种方法,一种getOutputStream,一种getWriter。
1)ServletOutputStream getOutputStream(); //获取输出字节流。提供write() 和 print() 两个输出方法
2)PrintWriter getWriter(); //获取输出字符流 提供write() 和 print()两个输出方法
print()方法底层都是使用write()方法的,相当于print()方法就是将write()方法进行了封装,使开发者更方便快捷的使用,想输出什么,就直接选择合适的print()方法,而不用考虑如何转换字节。
1、ServeltOutputStream getOutputStream();不能直接输出中文,直接输出中文会报异常

解决:
resp.getoutputStream().write(“哈哈哈,我要输出到浏览器”.getBytes(“UTF-8”));
要输出的汉字先用UTF-8进行编码,而不用让tomcat来进行编码,这样如果浏览器用的是UTF-8码表进行解码的话,那么就会正确输出,如果浏览器用的不是UTF-8,那么还是会出现乱码,所以说这个关键要看浏览器用的什么码表,这个就不太好,这里还要注意一点,就是使用的是write(byte)方法,因为print()方法没有输出byte类型的方法。
注意:response.setContentType 等效于 response.setCharacterEncoding + response.setHeader
解决方法:
方法一:response.setContentType(“text/html;charset=uft-8”);
使用Servlet API 来通知tomcaat和强制浏览器使用UTF-8来进行编码解码,这个的底层代码就是 response.setCharacterEncoding + response.setHeader的代码,进行了简单的封装而已。
/*
通过设置响应头,来设置浏览器也使用UTF-8字符集 目的是为了控制浏览器的行为,即控制浏览器用UTF-8进行解码
response.setContentType 等效于 response.setCharacterEncoding + response.setHeader
因为在setContentType方法中已经调用了setCharacterEncoding方法设置了Response容器的编码了。
注意:
1.response.setContentType它会通是设置服务器和客户端都使用UTF-8字符集,
2.还设置了响应头
3.调用response.setCharacterEncoding 和 response.setContentType方法,
必须在getWriter执行之前或者response被提交之前,否则依旧会出现乱码问题
*/
response.setContentType("text/html;charset=UTF-8");
方法二:使用Servlet API response.setCharacterEncoding(“UTF-8”);
让tomcat将我们要响应到浏览器的中文用UTF-8进行编码,而不使用默认的ISO-8859-1了,这个还是要取决于浏览器是不是用的UTF-8的码表,跟上面的一样有缺陷,
所以需要配合response.setHeader(“Content-Type”,“text/html;charset=UTF-8”);来使用,作用为手动设置响应内容,通知tomcat和浏览器使用utf-8来进行编码和解码。
/*
response.setCharacterEncoding("UTF-8"):设置服务器的响应对象所采用的字符编码类型为UTF-8,即设置服务器字符集为UTF-8
目的是用于解决response.getWriter()输出的字符流的乱码问题。
*/
response.setCharacterEncoding("UTF-8");
response.setHeader("Content-Type","text/html;charset=UTF-8");
(setHeader是HttpServletResponse的方法。如果想在拦截器Filter中设置字符编码,则无此方法,因为Filter的doFilter方法的参数类型是ServletResponse)
这里有几个小细节需要注意:
-
response.setCharacterEncoding(“UTF-8”);需要写在PrintWriter out = response.getWriter();的前面。拿到字符流后再设置编码是没有用的。
-
response.setContentType(“text/html;charset=UTF-8”);这句代码其实有两个作用:通知response以UTF-8输出和浏览器以UTF-8打开。即等价于response.setHeader(“content-type”, “text/html;charset=UTF-8”);和response.setCharacterEncoding(“UTF-8”);两句代码。
-
response.setContentType(“text/html;charset=UTF-8”); 目的是为了控制浏览器的行为,即控制浏览器用UTF-8进行解码;
-
response.setCharacterEncoding(“UTF-8”);目的是用于response.getWriter()输出的字符流的乱码问题。如果是response.getOutputStream()是不需要此种解决方案的,因为这句话的意思是为了将response对象中的数据以UTF-8解码后的字节流发向浏览器;
(2)request乱码问题
request请求分为post和get,对于不同的请求方式有不同的解决乱码的方案
第一种:POST请求
post请求方式的参数是在请求体中,相对于get请求简单很多,没有经过http协议这一步的编码过程,所以只需要在服务器端,设置服务器解码的码表跟浏览器编码的码表是一样的就行了,在这里浏览器使用的是UTF-8码表编码,那么服务器端就设置解码所用码表也为UTF-8就OK了
解决方案:
request.setCharacterEncoding(“UTF-8”);//命令Tomcat使用UTF-8码表解码,而不用默认的ISO-8859-1了。
所以在很多时候,在doPost方法的第一句,就是这句代码,防止获取请求参数时乱码。
注意:该设置只对post请求有效
第二种:GET请求(URI方式传递参数乱码),TOMCAT 8.0 以上用 GET 方式请求已经不存在乱码问题
get请求的参数是在url后面提交过来的,也就是在请求行中

FormServlet是一个普通的Servlet,浏览器访问它时,使用get请求方式提交了一个name=小明的参数值,在doGet中获取该参数值,并且打印到控制台,发现出现乱码
法一:要解决这个问题,修改tomcat服务器的配置文件。
[注意] TOMCAT 8.0 以上用 GET 方式请求,传送的参数已默认为 UTF-8 编码,所以可以不需要修改配置文件
修改tomcat目录下的conf/server.xml文件的第69行:
修改前内容:
<Connector port="8080" protocol="HTTP/1.1"
maxThreads="150" connectionTimeout="200000"
redirecPort="8443"/>
修改后内容:
<Connector port="8080" protocol="HTTP/1.1"
maxThreads="150" connectionTimeout="200000"
redirecPort="8443" URIEncoding="utf-8"/>

法二:
String username= request.getParameter(“name”);
String usernameString = new String(username.getBytes(“ISO-8859-1”),“UTF-8”);
tomcat默认全部都是用ISO-8859-1编码,不管你页面用什么显示,Tomcat最终还是会替你将所有字符转做ISO-8859-1.那么,当在另目标页面再用GBK翻译时就会将本来错的编码翻译成GBK的编码,这时的文字会乱码.
1.xxx.getBytes( )叫做编码,new String(byte[ ],encodingname)这个叫解码
2.http协议不会对请求参数进行编解码!只是传输,传输的是二进制。解码是tomcat的工作,utf8编码的字节序列被tomcat默认以iso8895-1方式解码所以有了乱码,所以要重新编码再解码。
a. 所以需要先将得到"字符"(不管是什么)都先用字节数组表示,
b. 且使用ISO-8859-1进行翻译,得到一个在ISO-8859-1编码环境下的字节数组.例如:AB表示成[64,65].
c. 然后再用GBK编码这个数组,并翻译成一个字符串.
那么我们可以得到一个编码转换的过程
假设:GBK码(“你”)->URLencode后变成->(%3F%2F)->Tomcat自动替你转一次ISO-8859-1->得到( 23 43 68 23 42 68 每一个符号表示为ISO-8859-1中的一个编码)->接收页面—>再转一次为ISO-8859-1的Byte数组[23,43,68,23,42,68]—>用GBK再转为可读的文字—>(%3F%2F"---->转为(“你”)
法三:URL转换
String username= request.getParameter(“name”);
String usernameString = new String(username.getBytes(“ISO-8859-1”),“gb2312”);
**
因为浏览器默认编码为gb2312
小结请求参数乱码问题:
get请求和post请求方式的中文乱码问题处理方式不同
1)get:请求参数在请求行中,涉及了http协议,手动解决乱码问题,知道出现乱码的根本原因,对症下药,其原理就是进行两次编码,两次解码的过程
new String(xxx.getBytes(“ISO-8859-1”),“UTF-8”);
2)post:请求参数在请求体中,使用servlet API解决乱码问题,其原理就是一次编码一次解码,命令tomcat使用特定的码表解码。
request.setCharaterEncoding(“UTF-8”);
五、总结
1)如果是post请求,加上这两句基本上可以解决所有的乱码问题
response.setContentType("text/html;charset=UTF-8");
request.setCharacterEncoding("UTF-8");
2)如果是get请求,TOMCAT 8.0 以上用 GET 方式请求,传送的参数已默认为 UTF-8 编码,所以不会出现get请求乱码问题,可以不需要修改配置文件。
a. 修改tomcat服务器的配置文件后 再加上 response.setContentType(“text/html;charset=UTF-8”);
b. 不想修改配置文件的话,可以使用下面的方式:
response.setContentType("text/html;charset=UTF-8");
String username= request.getParameter("name");
String usernameString = new String(username.getBytes("ISO-8859-1"),"UTF-8");
请求乱码
1)get请求:
经过了两次编码,所以就要两次解码
第一次解码:xxx.getBytes(“ISO-8859-1”);得到yyy
第二次解码:new String(yyy,“utf-8”);
连续写:new String(xxx.getBytes(“ISO-8859-1”),“UTF-8”);
2)post请求:
只经过一次编码,所以也就只要一次解码,使用Servlet API request.setCharacterEncoding();
request.setCharacterEncoding("UTF-8");
//不一定解决,取决于浏览器是用什么码表来编码,浏览器用UTF-8,那么这里就写UTF-8。
响应乱码
1)getOutputStream();
使用该字节输出流,不能直接输出中文,会出异常,要想输出中文,解决方法如下
解决:getOutputStream().write(xxx.getBytes(“UTF-8”));//手动将中文用UTF-8码表编码,变成字节传输,变成字节后,就不会报异常,并且tomcat也不会在编码,因为已经编码过了,所以到浏览器后,如果浏览器使用的是UTF-8码表解码,那么就不会出现中文乱码,反之则出现中文乱码,所以这个方法,不能完全保证中文不乱码
2)getWrite();
使用字符输出流,能直接输出中文,不会出异常,但是会出现乱码。能用三种方法解决,一直使用第二种方法
解决:通知tomcat和浏览器使用同一张码表。
response.setContentType(“text/html;charset=utf-8”); //通知浏览器使用UTF-8解码 同时通知tomcat和浏览器使用UTF-8编码和解码。
这个方法的底层原理是这句话:response.setHeader(“contentType”,“text/html;charset=utf-8”);
注意:getOutputStream()和getWrite() 这两个方法不能够同时使用,一次只能使用一个,否则报异常