运行模式
\quad \quad Spark注重建立良好的生态系统,它不仅支持多种外部文件存储系统,也提供了多种多样的集群运行模式。部署在单台机器上时,既可以用本地(Local)模式运行,也可以使用伪分布式模式来运行;当以分布式集群部署的时候,可以根据自己集群的实际情况选择Standalone模式(Spark自带的模式)、Spark on YARN模式或者Spark on mesos模式。Spark的各种运行模式虽然在启动方式、运行位置、调度策略上各有不同,但它们的目的基本都是一致的,就是在合适的位置安全可靠的根据用户的配置和Job的需要运行和管理Task。
\quad \quad Spark 的运行模式有 Local(也称单节点模式),Standalone(集群模式),Spark on Yarn(运行在Yarn上),Mesos以及K8s等常用模式。应用最多的就是前三种。
1、Spark Local模式
\quad \quad Local 模式是最简单的一种Spark运行方式,它采用单节点多线程(cpu)方式运行,直接运行在本地,利用本地资源进行计算。主要分为以下三种情况:
-
local:所有计算都运行在一个线程中;
-
local[K]:指定K个线程来运行计算,通常CPU有几个Core(线程数),就指定K为几,最大化利用CPU并行计算能力;
-
local[*]:自动设定CPU的最大Core数;
1.1 环境搭建
\quad \quad 只需要一台机器,只需要把Spark的安装包解压后,默认也不需修改任何配置文件,取默认值。不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS)。
-
下载Spark的安装包
下载地址

-
shell命令:
解压 Spark 安装包
tar -zxvf spark-2.0.2-bin-hadoop2.6.tgz
- 可重命名(我没有重命名)
mv spark-2.0.2-bin-hadoop2.6 spark
- 解压目录说明
bin 可执行脚本
conf 配置文件
data 示例程序使用数据
examples 示例程序
jars 依赖 jar 包
python pythonAPI
R R 语言 API
sbin 集群管理命令
yarn 整合yarn需要的文件
1.2 启动spark-shell
- 直接启动bin目录下的spark-shell:
./spark-shell
- 若想指定进程个数,可后面加参数
spark-shell --master local[N]
表示在本地模拟N个线程来运行当前任务
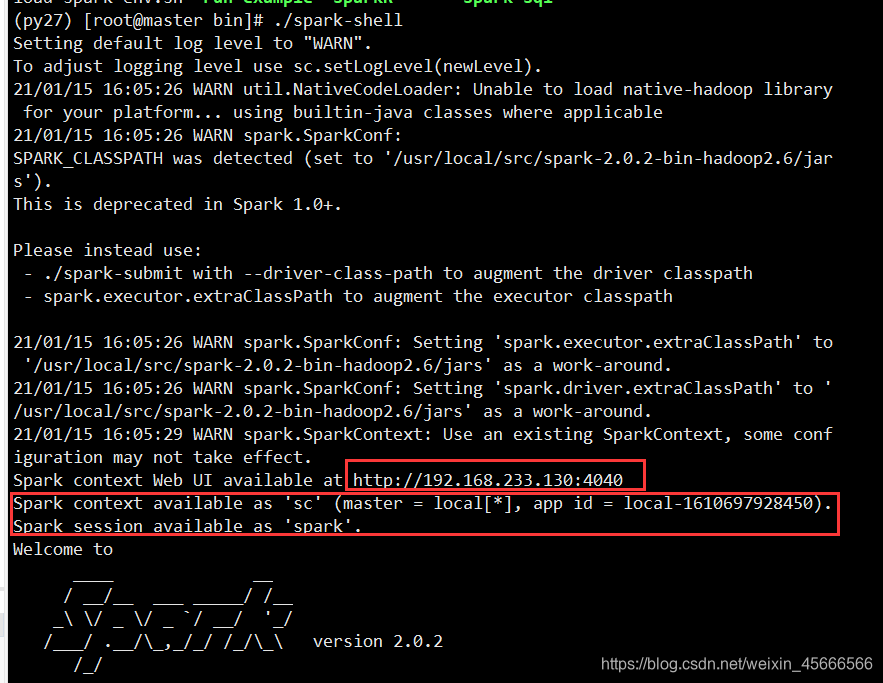
-
一些关键点,图中已经用红框标了出来!
-
我们开发中所用的SparkContext在命令行中已经为我们预先准备好了:即sc
-
给了一个SparkContext浏览的web页面,可以通过4040端口访问查看进程!
-
scala>命令行,表明里面可以直接写scala的代码,也就是说我们可以直接在命令行里面完成Spark程序并运行!
-
使用jps命令可以查看到spark-shell是一个SparkSubmit进程,也就是我们可以使用这种方式向本地Spark提交并运行我们的Spark程序(即Job)
1.3 单词统计
1、读取本地文件
(1)准备数据
(py27) [root@master data]# vim words.txt
(py27) [root@master data]# cat words.txt
hello me you her
hello you her
hello her
hello
(2)读取数据
- 注意本地文件路径之前需要加
file://,否则报错
scala> val textFile = sc.textFile("file:///root/data/words.txt")
textFile: org.apache.spark.rdd.RDD[String] = file:///root/data/words.txt MapPartitionsRDD[219] at textFile at <console>:26
(3)单词统计实验
scala> val counts = textFile.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect
counts: Array[(String, Int)] = Array((hello,4), (me,1), (you,2), (her,3))
2、读取HDFS文件
(1) 准备数据
- 首先查看一下hdfs 所有目录
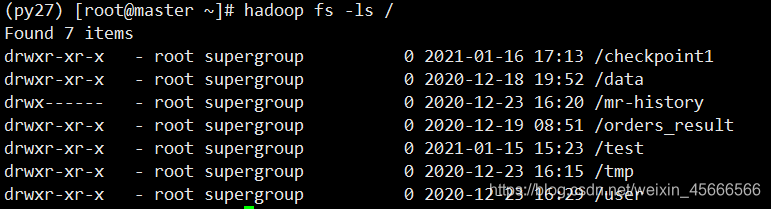
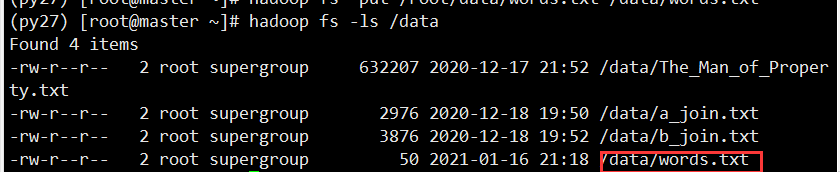
- 上传本地文件words.txt到hdfs
hadoop fs -put /root/data/words.txt /data/words.txt
(2) Spark-shell 读取数据
scala> val textFile = sc.textFile("hdfs://master:9000/data/words.txt")
textFile: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/data/words.txt MapPartitionsRDD[224] at textFile at <console>:26
(3)单词统计
scala> val counts = textFile.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[227] at reduceByKey at <console>:28
(4)将输出结果保存到Hdfs上
scala> counts.saveAsTextFile("hdfs://master:9000/data/output1")
待到程序执行完毕,我们进入到HDFS的UI界面进行查看

1.4 应用场景
\quad \quad Local模式,只适合开发阶段使用,我们可以在该模式下开发和测试代码,验证代码的逻辑没问题,后面再提交到集群上去运行和测试。如果是学习或者做测试,为了搭建环境的简化,可以搭建本地模式。
2、Spark Standalone模式
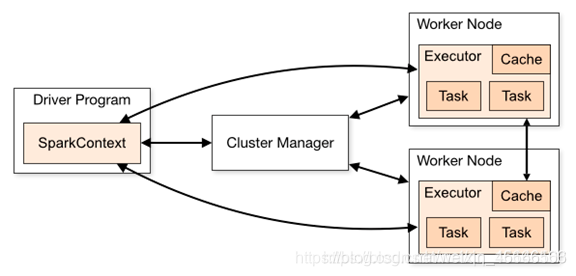
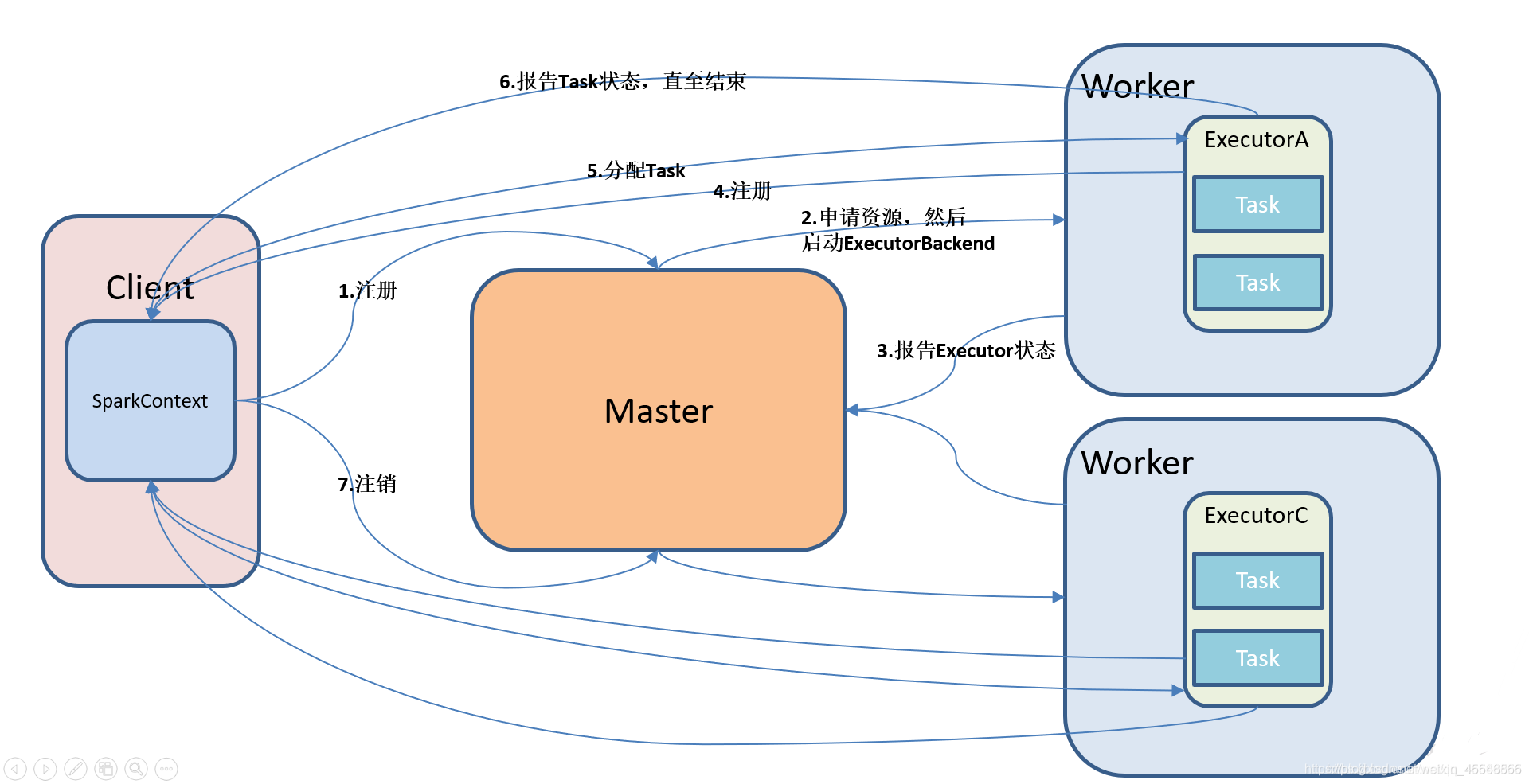
\quad \quad Spark是基于内存计算的大数据并行计算框架,实际中运行计算任务肯定是使用集群模式,那么我们先来学习Spark自带的standalone集群模式了解一下它的架构及运行机制。
\quad \quad Standalone模式即独立模式,自带完整的服务,可以单独部署到一个集群中,不需要任何的资源管理系统,只支持FIFO调度,在该模式下没有AM和NM的概念,也没有RM的概念,用户节点直接与Master交互,由Driver负责向Master申请资源,由Driver进行资源的分配和调度等。
- Standalone集群使用了分布式计算中的master-slave模型
- master是集群中含有master进程的节点
- slave是集群中的worker节点含有Executor进程
2.1 环境搭建
- 这里一并把Yarn模式也搭建了
(1)修改Spark配置文件
- 进入spark/conf下
(py27) [root@master spark-2.0.2-bin-hadoop2.6]# cd conf
- 执行命令1
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
添加以下内容
#配置Scala环境变量
export SCALA_HOME=/usr/local/src/scala-2.11.8
#配置Java环境变量
export JAVA_HOME=/usr/local/src/jdk1.8.0_172
#YARN模式配置文件
export HADOOP_HOME=/usr/local/src/hadoop-2.6.1
export HADOOP_CONF_DIR=/usr/local/src/hadoop-2.6.1/etc/hadoop
#指定spark老大Master的IP
export SPARK_MASTER_IP=master
export SPARK_LOCAL_DIRS=/usr/local/src/spark-2.0.2-bin-hadoop2.6
export SPARK_DRIVER_MEMORY=1G
mv slaves.template slaves
vim slaves
(2)分发spark
# A Spark Worker will be started on each of the machines listed below.
slave1
slave2
通过scp 命令将配置文件分发到其他机器上
scp -rp spark-2.0.2-bin-hadoop2.6/ root@slave1:/usr/local/src/
scp -rp spark-2.0.2-bin-hadoop2.6/ root@slave2:/usr/local/src/
2.2 启动 /停止Spark 集群
1、集群的启动和停止
- 首先启动hadoop集群
- 在主节点上启动Spark集群:在sbin目录下启动
./start-all.sh
- 在主节点上停止spark集群
./stop-all.sh
2、单独启动和停止
- 在 master 安装节点上启动和停止 master:
start-master.sh
stop-master.sh
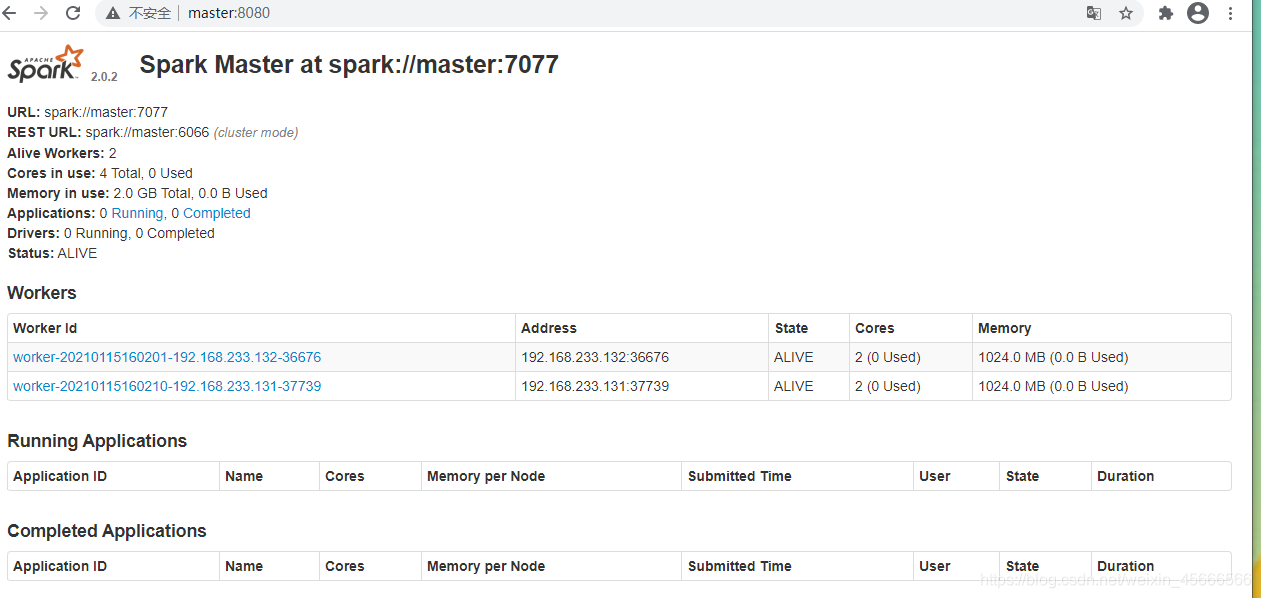
3、查看web界面
正常启动Spark集群后,查看Spark的web界面
2.3 环境验证
使用 Standalone 模式运行计算 PI 的程序
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
--executor-memory 1G \
--total-executor-cores 6 \
--executor-cores 2 \
./examples/jars/spark-examples_2.11-2.0.2.jar 100
2.4 配置历史服务器
\quad \quad 在 Spark-shell 没有退出之前, 我们是可以看到正在执行的任务的日志情况:http://master:4040. 但是退出 Spark-shell 之后, 执行的所有任务记录全部丢失。所以需要配置任务的历史服务器, 方便在任何需要的时候去查看日志。
1、在配置之前,如果spark服务还在启动中请先停止!
(py27) [root@master sbin]# ./stop-all.sh
2、 配置spark-default.conf文件, 开启 Log
(py27) [root@master spark-2.0.2-bin-hadoop2.6]# mv spark-defaults.conf.template spark-defaults.conf

在spark-defaults.conf文件中, 添加如下内容
(py27) [root@master conf]# vim spark-defaults.conf
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs://master:9000/tmp/spark-yarn-logs
spark.eventLog.compress=true
-
spark.eventLog.enabled
是否记录Spark事件,用于应用程序在完成后的筹够WebUI。
-
spark.eventLog.dir
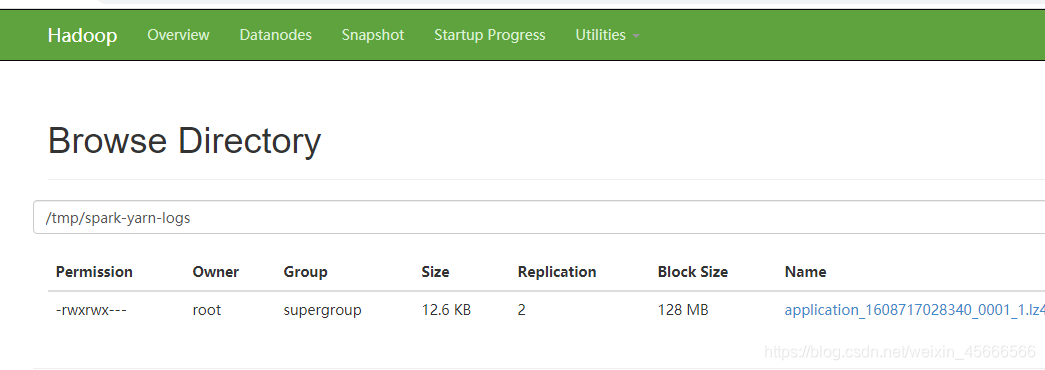
设置spark.eventLog.enabled为true后,该属性为记录spark时间的根目录。在此根目录中,Spark为每个应用程序创建分目录,并将应用程序的时间记录到此目录中。用户可以将此属性设置为HDFS目录,以便History Server读取。存放目录
/tmp/spark-yarn-logs必须提前在HDFS中建立相应的目录专门存放文件。
-
spark.eventLog.compress
否压缩记录Spark事件,前提spark.eventLog.enabled为true,默认使用的是snappy。
3、启动历史服务器
// 1. 需要先启动 HDFS
(py27) [root@master spark-2.0.2-bin-hadoop2.6]sbin/start-dfs.sh
// 2. 启动spark
(py27) [root@master spark-2.0.2-bin-hadoop2.6] sbin/start-all.sh
// 2. 然后再启动:
(py27) [root@master spark-2.0.2-bin-hadoop2.6] sbin/start-history-server.sh
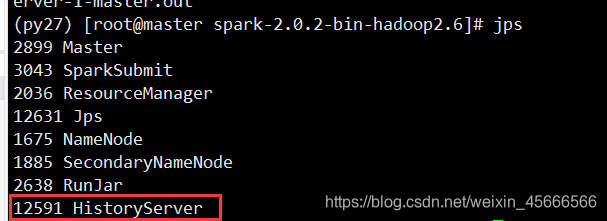
登录Web界面
http://master:18080
2.5 工作流程图
2.6 启动spark-shell
- 在bin目录下启动
./spark-shell --master spark://master:7077
- SparkContext web UI
2.7 单词统计
- 读取HDFS文件
scala> val textFile = sc.textFile("hdfs://master:9000/data/words.txt")
textFile: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/data/words.txt MapPartitionsRDD[1] at textFile at <console>:24
- 单词统计
val counts = textFile.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
- 保存结果
counts.saveAsTextFile("hdfs://master:9000/data/output2")
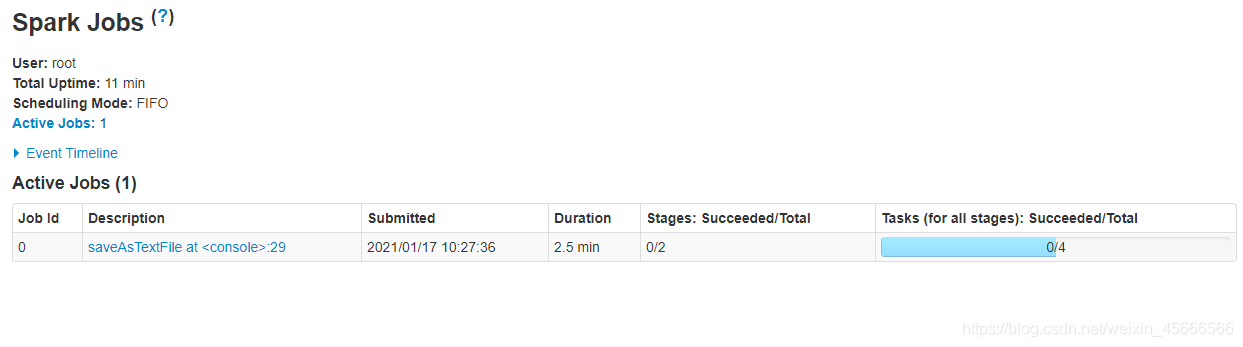

注意:集群模式下程序是在集群上运行的,不要直接读取本地文件,应该读取hdfs上的。因为程序运行在集群上,具体在哪个节点上我们运行并不知道,其他节点可能并没有那个数据文件。
3、Spark on Yarn 模式
\quad \quad Spark 客户端可以直接连接 Yarn,不需要额外构建Spark集群。因为把Spark程序提交给YARN运行本质上是把字节码给YARN集群上的JVM运行,但是得有一个东西帮我去把任务提交上个YARN,所以需要一个单机版的Spark,里面的有spark-shell命令,spark-submit命令。
3.1 环境搭建
- 这里只需要修改配置即可。
- 在standlone模式已经把配置文件弄好了,这里不再追述。
3.2 分类
Yarn模式有 client 和 cluster 两种模式,主要区别在于:Driver 程序的运行节点不同。
- client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
- cluster:Driver程序运行在由 RM(ResourceManager)启动的 AM(AplicationMaster)上,适用于生产环境。
3.3 Yarn Client 模式
流程图:
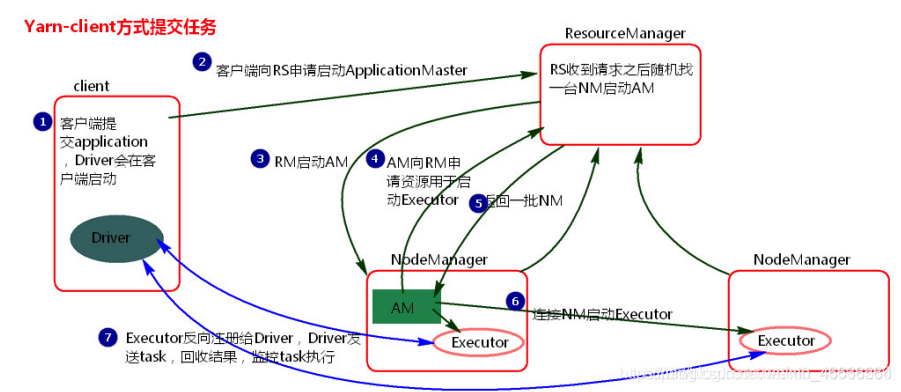
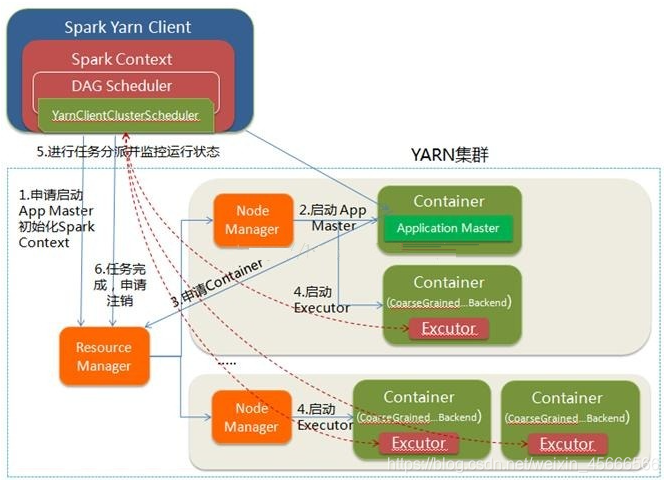
流程:
1.客户端提交一个Application,在客户端启动一个Driver进程
2.Driver进程会向ResourceManger发送请求,会启动ApplicationMaster的资源
3.ResourceManger会随机选择一台NodeManger,然后改NodeManger回到HDFS中下载jar包和配置,接着启动ApplicationMaster【ExecutorLuacher】。这里的NodeManger相当于StandAlone中的Worker节点
4.ApplicationMaster启动后,会向ResourceManager请求一批container资源,用于启动Executor.
5.ResourceManager会找到一批符合条件NodeManager返回给ApplicationMaster,用于启动Executor。
6.ApplicationMaster会向NodeManager发送请求,NodeManager到HDFS下载jar包和配置,然后启动Executor。
7.Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端
3.4 Yarn Cluster模式
流程图:
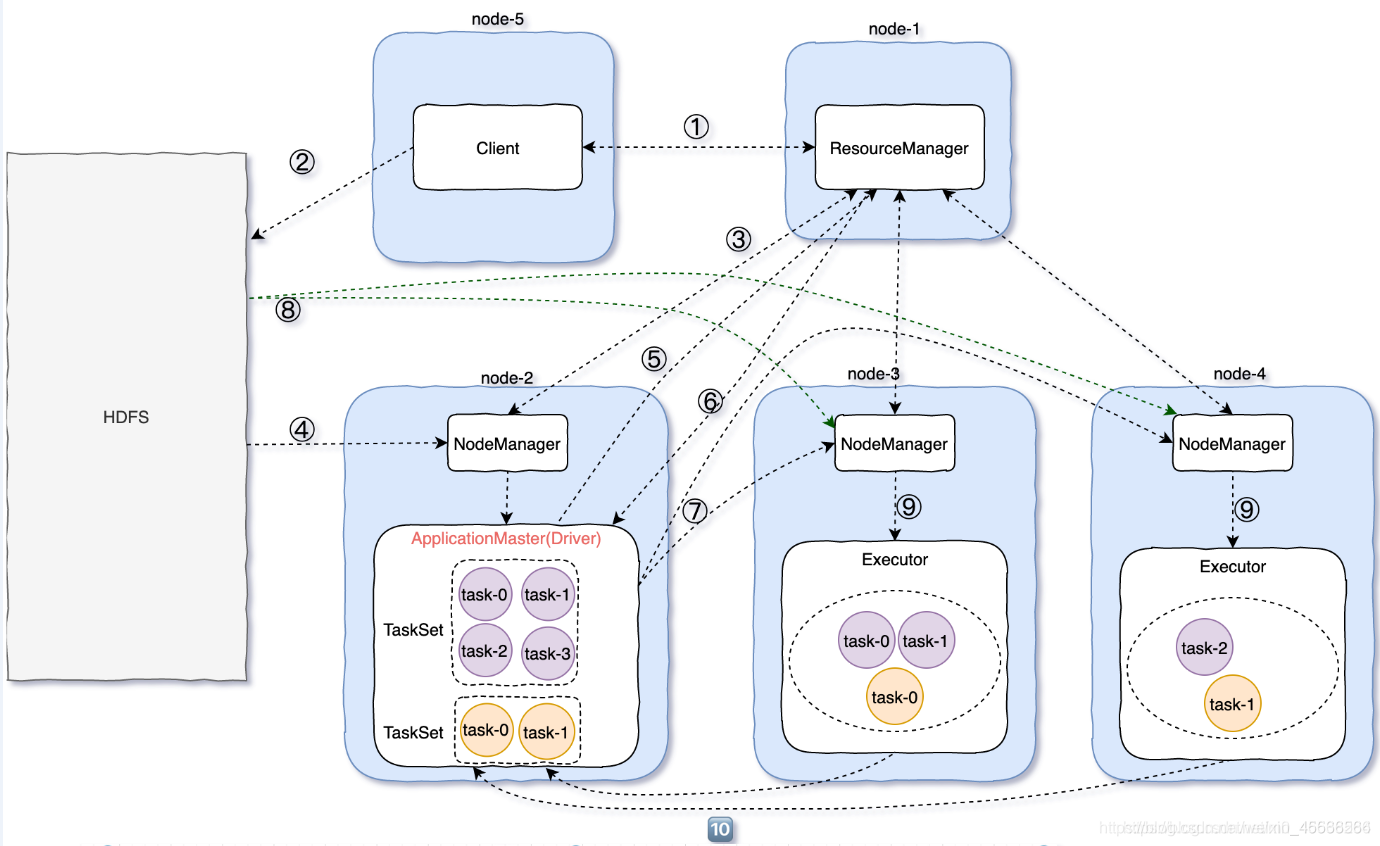
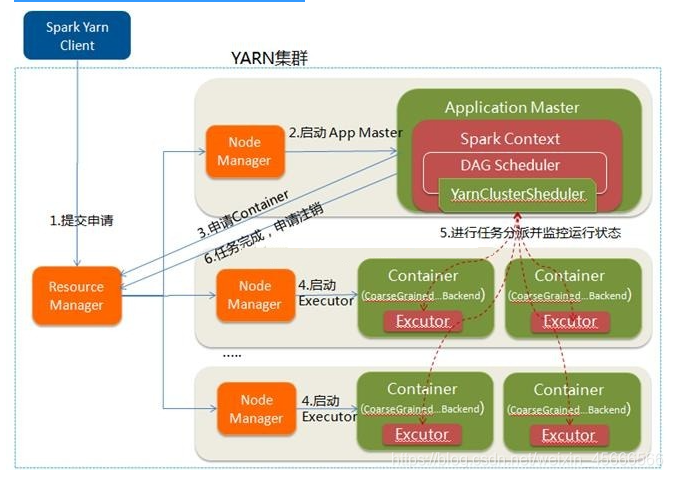
执行流程:
1.client向RM申请资源,RM会返回一个application ID
2.client上传spark jars下面的jar包以及自己写的jar包和配置
3.RM随机找一个资源充足的NodeManger
4.然后通过RPC通信让NodeManger从HDFS中下载jar包和配置,并启动ApplicationMaster
5.ApplicationMaster向RM申请资源
6.RM中的ResourceScheduler找到符合条件的NM,将NM的信息返回给ApplicationMaster
7.ApplicationMaster跟返回的NM进行通信
8.NM从HDFS中下载依赖
9.NM启动Executor
10.Executor启动之后反向向ApplicationMaster【Diver】注册
3.5 Cluster和Client模式区别
1、 Cluster和Client模式最最本质的区别是:Driver程序运行在哪里!
2、 运行在YARN集群中就是Cluster模式,
3、运行在客户端就是Client模式
4、Cluster模式:生产环境中使用该模式
- Driver程序在YARN集群中
- 应用的运行结果不能在客户端显示
- 该模式下Driver运行ApplicattionMaster这个进程中,
如果出现问题,yarn会重启ApplicattionMaster(Driver)
5、Client模式:测试环境
- Driver运行在Client上的SparkSubmit进程中
- 应用程序运行结果会在客户端显示
3.6 启动spark-shell
- Client模式:在bin目录下启动
(py27) [root@master bin]# ./spark-shell --master yarn-client
- Cluster模式:在bin目录下启动
(py27) [root@master bin]# ./spark-shell --master yarn-cluster
4、模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 学习和测试 |
| Standalone | 多台 | Master及Worker | Spark | 数据量不是很大的情况 |
| Yarn Client | 1 | Yarn及HDFS | Hadoop | 测试场景:交互与调式 |
| Yarn Cluster | 1 | Yarn及HDFS | Hadoop | 实际生产环境 |