题目描述
Description
小明爱上了炒股。经过近段时间的观察和整理,他发现了如果一个股票出现了某种形态的k线,那么这个股票不久之后一定会大涨。小明想利用这种神奇的k线来做一个股票软件。他将一条k线用整数序列a来表示,并规定当且仅当a[i+1]-a[i]=p[i]时,这条k线是一条神奇的k线。但是事情总不是一帆风顺的,小明发现许多k线不是神奇的,但之后也能大涨。不过他发现这些k线都和神奇的k线很接近。为了进一步扩展神奇的k线的用途,小明定义了两条k线b和a的差异度:
将b中某一个元素修改成任意值的代价为cost1,将b中某一个元素删除的代价为cost2。将b修改成a的前缀的最小的代价和就是b和a的差异度。这里的前缀的定义有点特别,假设b的长度为m,b是a的前缀当且仅当b[i+1]-b[i]=a[i+1]-ai。
一条k线与神奇的k线差异度越小,那么之后大涨的概率就越高。
虽然小明自己可以很快地算出某条k线和神奇的k线的差异度,但是如果要做成软件,还得写个程序来计算。你能帮帮他吗?
Input
第一行三个个正整数n,cost1,cost2。n表示给出的k线a的长度,cost1和cost2的含义如题。
第二行n-1个整数,依次表示p[1]到p[n-1],含义如题。
第三行n个整数,依次表示给出的k线a中的n个元素。
Output
一个数,a和神奇的k线的差异度。
Sample Input
8 1 2
1 2 3 4 5 6 7
0 1 999 6 10 -999 15 21
Sample Output
3
Data Constraint
Hint
【样例解释】
将999改为3,删去-999,得到序列0 1 3 6 10 15 21。不存在代价更小的方案。
【数据范围】
对于30%的数据:n<=100
对于60%的数据:n<=500
对于100%的数据:n<=1500
cost1,cost2<=1000000
p中每个元素的绝对值均<=1000
a中每个元素的绝对值均<=1000000
题解
先考虑一个naive的dp:
设f[i][j]表示a中第i个元素被保留,得到新序列长度为j的最小代价
转移:
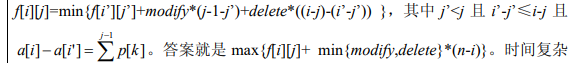
考虑把f[i][j]的含义改变,设f[i][j]表示a中第i个元素被保留,得到新序列长度为j的最大保留数

初值:f[i][j]=1,因为可以通过修改+删除,使得a[i]变成长度为1~a[i]的结尾
转移长这样
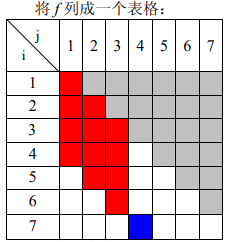
可以发现,如果两种序列的开头不同,那么这两种序列的转移互不影响
即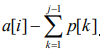 不同
不同
按照这个分类,·同一类的之间转移没有限制
所以貌似可以O(n3)
在同一类里维护每列的最大值,按(i-j)从小到大,j从小到大单调维护+线段树即可
时间:O(n2 log n)
code
#include <algorithm>
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <cstdio>
#define fo(a,b,c) for (a=b; a<=c; a++)
#define fd(a,b,c) for (a=b; a>=c; a--)
#define min(a,b) (a<b?a:b)
#define max(a,b) (a>b?a:b)
using namespace std;
struct type{
int x,y,s,first;
} A[1125751];
int a[1501];
int p[1501];
int tr[4503001][3];
int n,mod,del,i,j,k,l,ans,tot,len,s;
bool cmp(type a,type b)
{
return a.first<b.first || a.first==b.first && a.s<b.s || a.first==b.first && a.s==b.s && a.y<b.y;
}
void clear(int t)
{
tr[t][0]=0;
tr[t][1]=0;
tr[t][2]=-2133333333;
}
void New(int t,int x)
{
if (!tr[t][x])
{
tr[t][x]=++len;
clear(len);
}
}
void change(int t,int l,int r,int x,int s)
{
int mid=(l+r)/2;
tr[t][2]=max(tr[t][2],s);
if (l==r)
return;
if (x<=mid)
{
New(t,0);
change(tr[t][0],l,mid,x,s);
}
else
{
New(t,1);
change(tr[t][1],mid+1,r,x,s);
}
}
int find(int t,int l,int r,int x,int y)
{
int mid=(l+r)/2,ans=-2133333333,s;
if (x<=l && r<=y)
return tr[t][2];
if (x<=mid)
{
if (tr[t][0])
{
s=find(tr[t][0],l,mid,x,y);
ans=max(ans,s);
}
}
if (mid<y)
{
if (tr[t][1])
{
s=find(tr[t][1],mid+1,r,x,y);
ans=max(ans,s);
}
}
return ans;
}
int main()
{
// freopen("a.in","r",stdin);
// freopen("b.out","w",stdout);
// freopen("kei2.in","r",stdin);
// freopen("S8_7_3.in","r",stdin);
scanf("%d%d%d",&n,&mod,&del);
fo(i,1,n-1)
{
scanf("%d",&p[i]);
p[i]+=p[i-1];
}
fo(i,1,n)
scanf("%d",&a[i]);
fo(i,1,n)
{
fo(j,1,i)
{
++tot;
A[tot].x=i;
A[tot].y=j;
A[tot].s=i-j;
A[tot].first=a[i]-p[j-1];
}
}
sort(A+1,A+tot+1,cmp);
ans=min(del,mod)*n;
len=1;
clear(1);
fo(l,1,tot)
{
if (A[l].y>1)
s=find(1,1,n,1,A[l].y-1);
else
s=-2133333333;
s=max(s+1,1);
ans=min(ans,(A[l].x-A[l].y)*del+(A[l].y-s)*mod+min(del,mod)*(n-A[l].x));
change(1,1,n,A[l].y,s);
if (l<tot && A[l].first!=A[l+1].first)
{
len=1;
clear(1);
}
}
printf("%d\n",ans);
}