C++ 11 引入了 std::thread 标准库,方便了多线程相关的开发工作。
说到多线程开发,可不仅仅是创建一个新线程就好了,不可避免的要涉及到线程同步的问题。
而保证线程同步,实现线程安全,就要用到相关的工具了,比如信号量、互斥量、条件变量、原子变量等等。
这些名词概念都是来操作系统里面引申来的,并不是属于哪一种编程语言所特有的,在不同语言上的表现形式不一样,但其背后的原理是一致的。
线程池150行代码实现的视频讲解,有需要学习的朋友可以点击观看:150行代码,手写线程池
C++ 11 同样引入了 mutex、condition_variable、future 等实现线程安全的类,下面就来一一了解它们。
mutex
mutex 作为互斥量,提供了独占所有权的特性。
一个线程将互斥量锁住,直到调用 unlock 之前,该线程都是拥有该锁的,而其他线程访问被锁住的互斥量,则会被阻塞住。
使用示例:
#include <thread>
#include <iostream>
int num = 0;
std::mutex mutex;
void plus(){
std::lock_guard<std::mutex> guard(mutex);
std::cout << num++ <<std::endl;
}
int main(){
std::thread threads[10];
for (auto & i : threads) {
i = std::thread(plus);
}
for (auto & thread : threads) {
thread.join();
}
return 0;
}如上代码,创建了 10 个线程,每个线程都会先打印 num 的值,然后再将 num 变量加一,依次打印 0 到 9 。
众所周知,+1 的操作不是线程安全的,实际包含了三步,先读取,再加一,最后赋值。但是因为使用了互斥量 mutex ,保证独占性,所以结果都是按照顺序递增打印的。
如果不使用互斥量,那么可能前一个线程还没有赋值完,后一个线程就进行了读取,最后的结果就是随机不可预料的。
condition_variable
condition_variable 作为条件变量,它会调用 wait 函数等待某个条件满足,如果不满足的话,就通过 unique_lock 来锁住当前线程,当前线程就处于阻塞状态,直到其他线程调用了条件变量的 nofity 函数来唤醒。
使用示例:
#include <iostream>
#include <thread>
int num = 0;
std::mutex mutex;
std::condition_variable cv;
void plus(int target){
std::unique_lock<std::mutex> lock(mutex);
cv.wait(lock,[target]{return num == target;});
num++;
std::cout << target <<std::endl;
cv.notify_all();
}
int main(){
std::thread threads[10];
for (int i = 0; i < 10; ++i) {
threads[i] = std::thread(plus,9-i);
}
for (auto & thread : threads) {
thread.join();
}
return 0;
}同样是创建了 10 个线程,每个线程都会有一个 target 参数,代表该线程要打印的数值,按照 9 -> 0 顺序创建线程,最后运行结果是依次打印 0 -> 9 。
每个线程运行时都会先调用 wait 函数等待 num == target 这一条件满足,一旦满足就会将 num 加一,并打印 target 值,然后唤醒下一个满足条件的值。
通过改变条件变量的 wait 函数唤醒条件,就可以实现不同的多线程模式,比如常见的生产者-消费者模型。
分享更多关于C/C++ Linux后端开发网络底层原理知识学习提升 学习资料,完善技术栈,内容知识点包括Linux,Nginx,ZeroMQ,MySQL,Redis,线程池,MongoDB,ZK,流媒体,音视频,Linux内核,CDN,P2P,epoll,Docker,TCP/IP,协程,DPDK等等。
视频学习资料点击:C/C++Linux服务器开发/Linux后台架构师-学习视频

condiation_variable 实现生产消费者模式
#include <iostream>
#include <thread>
#include <queue>
int main(){
std::queue<int> products;
std::condition_variable cv_pro,cv_con;
std::mutex mtx;
bool end = false;
std::thread producer([&]{
for (int i = 0; i < 10; ++i) {
std::unique_lock<std::mutex> lock(mtx);
cv_pro.wait(lock,[&]{return products.empty();});
products.push(i);
cv_con.notify_all();
}
cv_con.notify_all();
end = true;
});
std::thread consumer([&]{
while (!end){
std::unique_lock<std::mutex> lock(mtx);
cv_con.wait(lock,[&]{return !products.empty();});
int d = products.front();
products.pop();
std::cout << d << std::endl;
cv_pro.notify_all();
}
});
producer.join();
consumer.join();
return 0;
}future & promise
future 这一特性在日常开发中用的比较少,它可以用来获取异步任务的结果,也可以当做一种线程间同步的手段。
假设现在程序要创建一个线程去执行耗时操作,并且等耗时操作结束了之后要拿到返回值,那么可以通过 condiation_variable 来实现,在异步线程执行完了之后调用 notify 方法来唤醒主线程,同样也可以通过 future 来实现。
当程序通过特定方法创建了一个异步操作之后会返回一个 future ,该 future 可以访问到异步线程的状态。
在异步线程里面设置某个共享状态的值,与该共享状态相关联的 future 就可以通过 get 方法来获取结果,get() 方法会阻塞调用线程,从而等待异步线程完成设置。
future 的 get 方法其实就相当于 condiation_variable 的 wait 方法,而异步线程设置共享状态的值的方法就相当于 condiation_variable 的 notify 方法。
future 的创建有如下三种方式:
std::promise
promise 就像它的字面意思一样,代表承诺,说明它一定会在异步线程设置共享状态的,而 future 就耐心等待好了。
promise 和 future 的调用流程如下图所示:

代码示例如下:
#include <iostream>
#include <thread>
#include <chrono>
#include <future>
void task(std::promise<int>& promise){
std::this_thread::sleep_for(std::chrono::seconds(1));
promise.set_value(10);
}
int main(){
std::promise<int> promise;
std::future<int> future = promise.get_future();
std::thread t(task,std::ref(promise));
int result = future.get();
std::cout << "thread result is " << result << std::endl;
t.join();
return 0;
}
复制代码promise 通过 get_future 方法获取与该 promise 关联的 future 对象,并且通过 set_value 方法设置共享状态的值。
std::packaged_task
packaged_task 可以用来包装一个可调用的对象 ,并且能作为线程的运行函数,有点类似于 std::function 。
但不同的是,它将其包装的可调用对象的执行结果传递一个相关联的 future ,从而实现状态的共享,future 通过 get 方法来等待可调用对象执行结束。
如下代码所示:
#include <iostream>
#include <thread>
#include <chrono>
#include <future>
int task(){
std::this_thread::sleep_for(std::chrono::seconds(1));
return 10;
}
int main(){
std::packaged_task<int(void)> packaged_task(task);
std::future<int> future = packaged_task.get_future();
std::thread thread(std::move(packaged_task));
int result = future.get();
std::cout << "thread result is " << result << std::endl;
thread.join();
return 0;
}packaged_task 通过 get_future 方法来获得相关联的 future 对象。
std::async
async 也能创建 future ,并且它更像是对 std::thread,std::packaged_task,std::promise 的封装。
如下代码所示:
#include <iostream>
#include <thread>
#include <chrono>
#include <future>
int task(){
std::this_thread::sleep_for(std::chrono::seconds(1));
return 10;
}
int main(){
std::future<int> future = std::async(std::launch::async,task);
int result = future.get();
std::cout << "thread result is " << result << std::endl;
return 0;
}
复制代码通过 async 直接创建异步线程并且获取相关联的 future 对象,连 thread 创建线程的操作都省了。
async 有两种执行策略,launch::async 和 launch::deferred 。其中前者是立即执行,后者是等调用 future.get() 方法时才会创建线程执行任务。
线程池的建设
了解了以上的线程相关操作类,就可以进一步进阶,通过它们来打造一个线程池了。
关于线程池建设,根据具体业务和使用场景,会有很多不同支持,但有些本质内容还是不会变的。
线程池的出发点当然是为了减少在频繁创建和销毁线程上所花的时间和系统资源的开销,表现形式上就是有一池子的线程,向线程池提交任务,最终分配到某个线程上去执行。
如下图所示,就是一个简易线程池的雏形,有任务 Task,有 Thread Pool 来分发任务,也有 Worker Thread 来最终执行任务,麻雀虽小五脏俱全。

接下来就详细拆解以上部分内容。
分享更多关于C/C++ Linux后端开发网络底层原理知识学习提升 学习资料,完善技术栈,内容知识点包括Linux,Nginx,ZeroMQ,MySQL,Redis,线程池,MongoDB,ZK,流媒体,音视频,Linux内核,CDN,P2P,epoll,Docker,TCP/IP,协程,DPDK等等。
视频学习资料点击:C/C++Linux服务器开发/Linux后台架构师-学习视频
任务类型
任务 Task 的类型根据业务需求可以有多种定义,主要差别在于任务需要的参数类型以及返回值类型。
另外,任务本身也可以有一些属性来标识该属性的类型,应该放到什么样的线程去执行等等。
简单起见,定义一个简单的 Task 类型,无需参数,也不需要返回值类型。
using task = std::function<void()>;线程数量
一个线程池该有多少线程呢?如果数量太多,会导致资源浪费,有些线程不一定能充分使用。如果太少就会导致频繁创建新线程。
一个灵活的线程池应该是可以动态改变线程数量的,参考 Java线程池实现原理及其在美团业务中的实践。
在 Java 的 ThreadPoolExecutor 中通过 corePoolSize 和 maximumPoolSize 来限制线程的数量,线程数量会在 [0 ~ corePoolSize] 和 [corePoolSize ~ maximumPoolSize] 之间波动。
当任务吃紧,线程和缓存都满了,就会申请线程,数量达到 [corePoolSize ~ maximumPoolSize] 范围,一旦任务松懈,就会释放一些空闲线程,数量回落到 [0 ~ corePoolSize] 范围,如果任务持续吃紧,那么就会拒绝任务了。
当然,也有其他确定线程数量的策略,根据具体的业务需求来核定,比如根据 CPU 多核来决定线程数量多少。
简单起见,这里就以固定线程数量作为演示了。
size_t N = std::thread::hardware_concurrency();任务缓存
假设现在已经固定了 N 个线程,并且每个线程都有任务在执行,这时有来了一个新任务,那么该怎么处理呢? 这时候就需要任务缓存机制了(当然也可以直接拒绝该任务)。
任务缓存也分多种形式:
- 全局缓存
- 线程缓存
- 全局缓存 + 线程缓存
全局缓存
全局缓存,顾名思义就是在线程池有一个全局的缓存队列,凡是进入到线程池的任务都会先进到全局缓存中,然后由全局缓存进行任务的分发,最后由不同的工作线程去执行任务。
线程缓存
线程缓存,顾名思义就是在每个工作线程都有一个缓存队列,然后线程不断循环处理自己缓存队列上的任务。凡是进入到线程池的任务,都会由线程池进到调度和分发,然后进入到工作线程对应的缓存队列中,最终被执行结束
全局缓存 + 线程缓存
全局缓存 + 线程缓存 就是将上面两者结合起来了,用如下图来汇总演示:
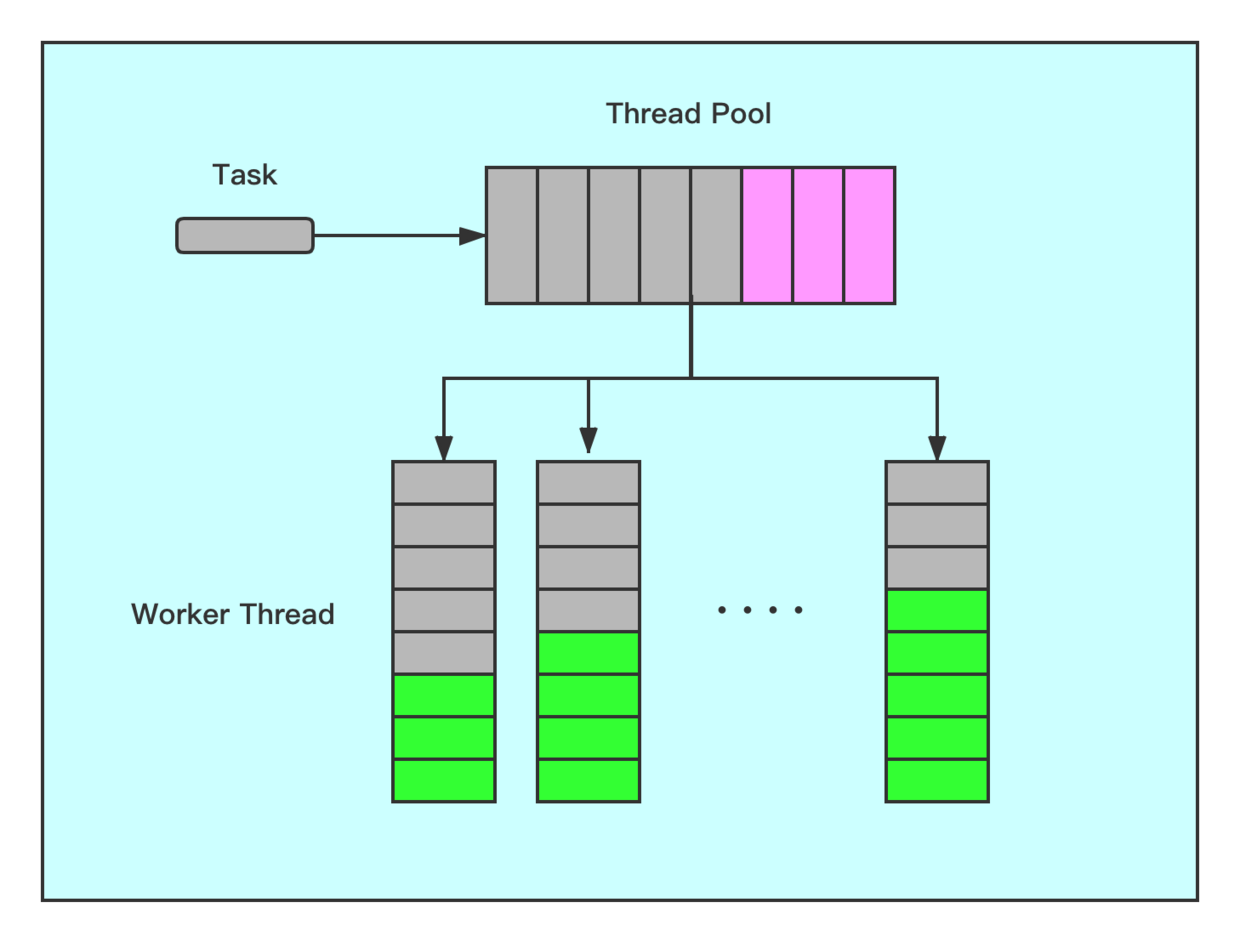
这种缓存方式算是比较复杂的情形了,适用于那种计算量大且快速执行的情形,一般来说还是全局缓存用的比较普遍。
缓存队列
有了任务缓存,那么还应该定义一下缓存队列。毫无疑问,缓存队列必须是线程安全的,因为它要在多个工作线程之间共享任务。
缓存队列的形式有很多,比如阻塞队列,双向链表的阻塞队列等等,这里定义一个简单的队列,把 std::queue 做一下线程安全的封装。
#pragma once
#include <mutex>
#include <queue>
// Thread safe implementation of a Queue using an std::queue
template <typename T>
class SafeQueue {
private:
std::queue<T> m_queue;
std::mutex m_mutex;
public:
SafeQueue() {
}
bool empty() {
std::unique_lock<std::mutex> lock(m_mutex);
return m_queue.empty();
}
int size() {
std::unique_lock<std::mutex> lock(m_mutex);
return m_queue.size();
}
void enqueue(T& t) {
std::unique_lock<std::mutex> lock(m_mutex);
m_queue.push(t);
}
bool dequeue(T& t) {
std::unique_lock<std::mutex> lock(m_mutex);
if (m_queue.empty()) {
return false;
}
t = std::move(m_queue.front());
m_queue.pop();
return true;
}
};定义了 enqueue 和 dequeue 方法向队列中塞任务和取任务,通过加锁来保证线程安全。
线程调度
线程池最核心的部分也就是线程调度了,假设使用了全局缓存的形式,那么如何把全局缓存中的任务分发给空闲线程呢?
实际上从某种角度来说,全局缓存的线程池也可以认为是一个单生产者-多消费者模式,全局缓存就是生产者,而多个线程就是多个消费者了。
在前面的代码实践中已经写了一个单生产者-单消费者模式,当生产者生产了 Task 之后,就通过 notify 方法来唤醒消费者,从而将 Task 分配到消费者去执行。由于只有一个消费者,那唤醒的就是唯一的那个了。
那假若有多个消费者,唤醒的又是哪一个呢?答案是随机的。调用 notify_one 方法会随机唤醒一个线程,调用 notify_all 则会唤醒全部线程。
但是唤醒并不代表线程就会消费 Task,一个 Task 对应多个线程,线程唤醒之后会去全局缓存抢夺 Task 任务,一旦得手就执行,而其他没有抢到的线程则继续挂起,等待下一次的唤醒。
线程池中线程的运行状态如下图所示:
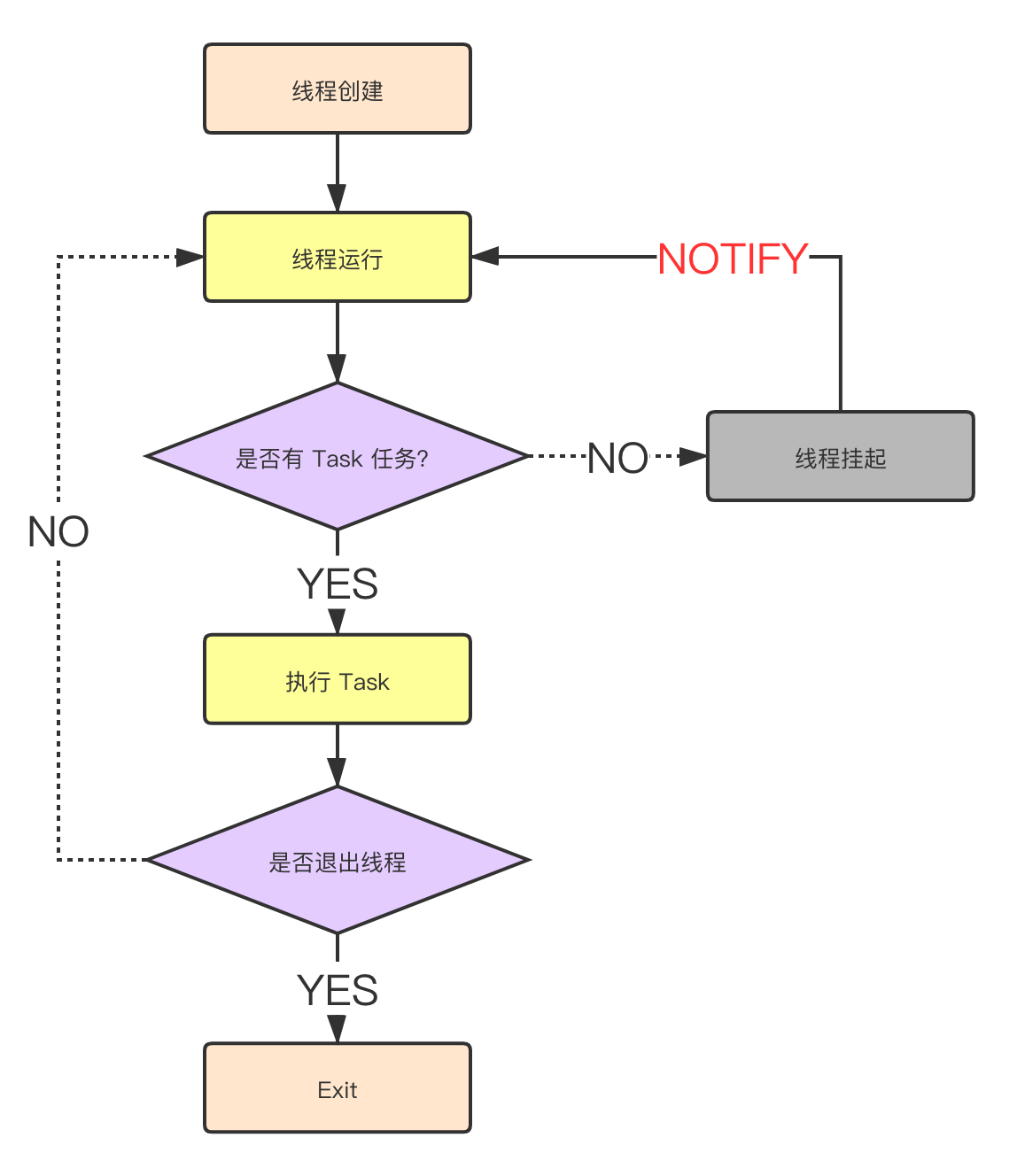
本质上,线程池还是通过 notify 方法来唤醒线程,从而实现任务分发和调度的。
这种方式具有一定的随机性,不能确保到底唤醒了哪个线程,可以根据业务需要定制相关的调度逻辑,比如只唤醒某些具有共同属性的线程,或者根据 Task 任务的要求来唤醒指定线程,更可以不通过 notify 的方式,直接把任务派发给对应的线程去执行。
根据上述流程图就可以给出工作线程运行的代码了:
class WorkerThread {
private:
int m_id;
ThreadPool *m_pool;
public:
WorkerThread(ThreadPool *pool, int id) : m_pool(pool), m_id(id) {
}
void operator()() {
task func;
bool dequeued;
while (!m_pool->m_shutdown) {
std::unique_lock<std::mutex> lock(m_pool->m_mutex);
if (m_pool->m_queue.empty()){
m_pool->m_condition_variable.wait(lock);
}
dequeued = m_pool->m_queue.dequeue(func);
if (dequeued) {
func();
}
}
}
};下面就是一个简单的线程池代码实践:
#ifndef THREAD_POOL_THREADPOOL_H
#define THREAD_POOL_THREADPOOL_H
#include <functional>
#include <future>
#include <mutex>
#include <condition_variable>
#include <thread>
#include <queue>
#include "SafeQueue.h"
using task = std::function<void()>;
class ThreadPool {
public:
ThreadPool(size_t thread_num = std::thread::hardware_concurrency()) : m_threads(
std::vector<std::thread>(thread_num)), m_shutdown(false) {
}
void init() {
for (int i = 0; i < m_threads.size(); ++i) {
m_threads[i] = std::thread(WorkerThread(this, i));
}
}
void shutdown() {
m_shutdown = true;
m_condition_variable.notify_all();
for (int i = 0; i < m_threads.size(); ++i) {
if (m_threads[i].joinable()) {
m_threads[i].join();
}
}
}
std::future<void> submit(task t){
auto p_task = std::make_shared<std::packaged_task<void()>>(t);
task wrapper_task = [p_task](){
(*p_task)();
};
m_queue.enqueue(wrapper_task);
m_condition_variable.notify_one();
return p_task->get_future();
}
private:
class WorkerThread {
private:
int m_id;
ThreadPool *m_pool;
public:
WorkerThread(ThreadPool *pool, int id) : m_pool(pool), m_id(id) {
}
void operator()() {
task func;
bool dequeued;
while (!m_pool->m_shutdown) {
std::unique_lock<std::mutex> lock(m_pool->m_mutex);
if (m_pool->m_queue.empty()){
m_pool->m_condition_variable.wait(lock);
}
dequeued = m_pool->m_queue.dequeue(func);
if (dequeued) {
func();
}
}
}
};
bool m_shutdown;
SafeQueue<task> m_queue;
std::vector<std::thread> m_threads;
std::mutex m_mutex;
std::condition_variable m_condition_variable;
};
#endif //THREAD_POOL_THREADPOOL_H通过 submit 方法提交任务到全局缓存队列中,然后唤醒线程去消费任务执行。
小结
关于 C++ 多线程的使用还有很多知识点,以上只是介绍了部分内容,还有很多不足之处,后续再补充了。