前提
对于k8s的自主式的Pod出现问题的解决方案(单个Pod)
- Pod主进程发生故障,由kubelet根据重启策略进行操作恢复
- Pod程序发生故障,由存活性探测(liveness probe)进行故障通报,再进行重启策略
问题:
针对意外删除Pod或者节点故障导致的问题,Pod无法进行处理
K8s 控制器
通过绑定Pod进行监控其状态,实现满足用户预期的状态,通过控制器实现Pod生命周期中的各类自动管理行为,比如创建和删除(k8s的控制器存在很多种,针对资源类型不同)
k8s依据资源类型分为5种
- 工作负载:Pod是工作负载型资源的基础资源,负责运行容器(容器的持久化存储、配置、秘钥等等),而对于出现意外删除Pod或者节点故障导致的问题需要工作负载控制器完成
- 针对Pod程序就要分为无状态服务和有状态服务,那么控制器也存在针对这2种的实现
- 无状态:程序可以随时加入或者删除都不会影响到用户访问(比如web服务)
- 有状态:程序的中途退出或者加入都会导致数据的错误访问(比如数据库)
- 发现和负载均衡:属于service和ingress的功能实现
- 配置和存储:属于存储(pv、pvc)和configmap、secret的功能实现
- 集群资源:属于用户授权功能实现(RoleBinding、ClusterRoleBinding)
- 元数据:实现集群内部的其他资源配置其行为或者特性(LimitRange实现控制CPU和内存)
一个应用都是通过多个资源管理实现,下面的内容都是基于工作负载资源控制器
工作负载控制器分类
-
ReplicaSet:早期控制器的ReplicationController替代者,ReplicaSet用于管理Pod的对象副本数在任何时刻都能满足期望数
-
Deployment:基于ReplicaSet之上,对ReplicaSet和Pod的管理添加了高级特性(ReplicaSet属于低级资源,一般不单独使用)
- 事件和状态查看
- 保存更新版本记录,支持回滚到指定版本
- 可以实现多种自动更新方案
-
DaemonSet:实现全部节点上只运行一个Pod副本,节点删除后,Pod自动被回收
- 常用场景:集群守护进程(ceph)节点日志收集(logstash)节点监控代理(zabbix)等等
-
Job和CronJob
- Job:执行单次计划任务
- CronJob:周期性执行计划任务(类似linux的crontab)
StatefulSet控制器属于特殊的,针对有状态服务,暂时放一边
举例:(最简单结构)
创建Pod
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.19
创建replicaset
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
labels:
app: nginx
ver: new
spec:
replicas: 2
selector:
matchLabels:
app: nginx
ver: new
template:
metadata:
name: nginx
labels:
app: nginx
ver: new
spec:
containers:
- name: nginx
image: nginx:1.19
创建deploymnet
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
ver: new
spec:
replicas: 2
selector:
matchLabels:
app: nginx
ver: new
template:
metadata:
name: nginx
labels:
app: nginx
ver: new
spec:
containers:
- name: nginx
image: nginx:1.19
观察分析
控制器是嵌套关系,Pod是最小单位,叠加上控制器属性定义
- replicaset的template下面是跟Pod完全匹配的(省略了api和kind),代表的就是Pod
- spec到template之间定义是的replicaset功能属性,副本数和标签选择器
- 副本数:控制器最基本的需求
- 标签选择器:这个是非常重要的概念,控制器匹配控制Pod的一组标签,多标配是与的关系,一般都是跟Pod标签一样进行匹配
- 最上面的metadata定义就是控制器的元基本信息
Deployment和replicaset配置基本一样,差别就是kind控制器的类型,也就是说明了Deployment是调用replicaset实现功能,并支持了Deployment的高级特性
标签选择器举例(replicaset)
- 先创建Pod
- 再创建replicaset
kubectl apply -f nginx-pod.yaml
#yaml文件名自定义即可
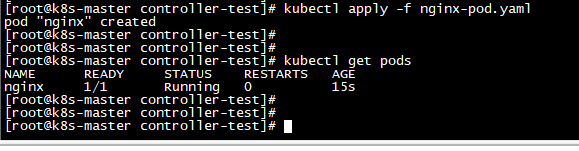
kubectl apply -f nginx-replicaset.yaml
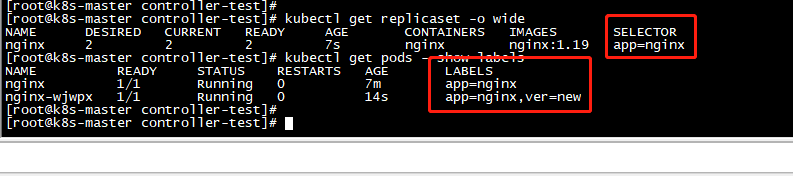
 看到selector和labels是匹配的,2个标签与的关系,一个是3个Pod
看到selector和labels是匹配的,2个标签与的关系,一个是3个Pod
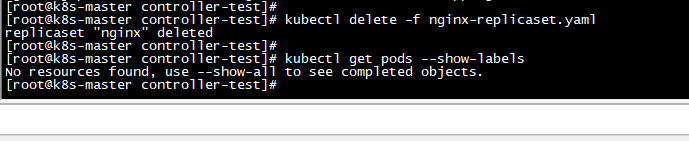
尝试把replicaset的matchLabels删除一个,看下效果
kubectl delete -f nginx-replicaset.yaml
kubectl apply -f nginx-replicaset.yaml
#先删除之前的,再创建
查看只有2个Pod,说明之前创建的Pod也归属到replicaset进行管理了,不再是自主的Pod了,通过删除可以明确
控制器通过标签来管理副本数,来满足用户期望值
标签选择器举例(deployment)
- 先创建Pod
- 再创建replicaset
- 最后创建deployment
查看会存在几个Pod(2个控制器副本数都是2)
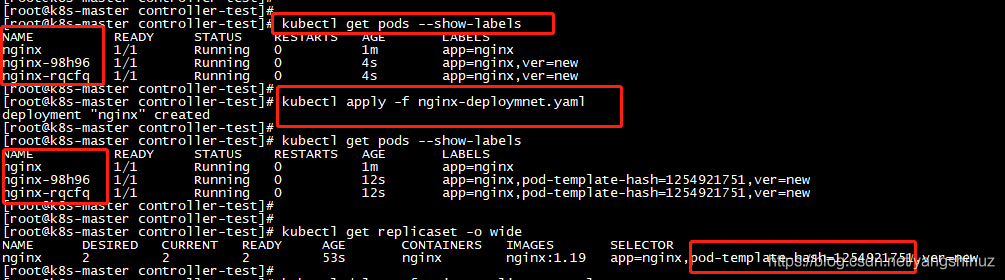 Pod为3个,并且replicaset也只有一个,按道理deployment也会创建一个replicaset,只是重叠了而已,因为配置是一样的,只是增加了pod-template-hash=1254921751,这个是deployment创建会自动添加的
Pod为3个,并且replicaset也只有一个,按道理deployment也会创建一个replicaset,只是重叠了而已,因为配置是一样的,只是增加了pod-template-hash=1254921751,这个是deployment创建会自动添加的
删除replicaset看下效果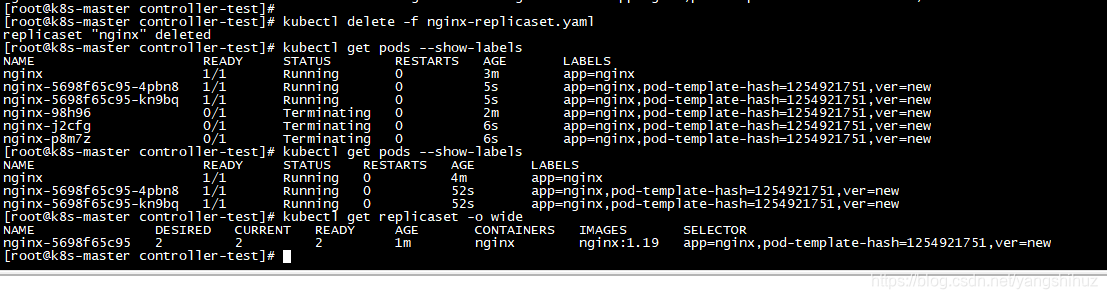 基于deployment的replicaset会重新新建出来,Pod也是,原有的会被删除
基于deployment的replicaset会重新新建出来,Pod也是,原有的会被删除
问题来了,replicaset如果标签重叠就会导致Pod会被其他的replicaset控制器影响
pod-template-hash
在deployment中为了避免自己管理的子replicaset出现这样的问题,deployment会对 ReplicaSet 的 PodTemplate 进行哈希处理
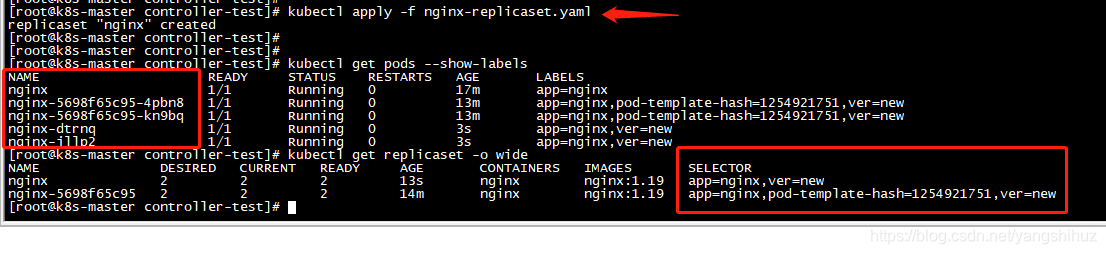 如果再次创建replicaset就会发现,不会被重叠了,并且Pod为5个
如果再次创建replicaset就会发现,不会被重叠了,并且Pod为5个
replicaset和deployment为了不重叠,所以即便是标签选择器匹配也是会单独创建,为了不影响Pod,所以同样标签选择器都匹配了,也只会影响属于自己的Pod(还有就是注意顺序,先deployment后replicaset才不会重叠),所以说replicaset一般不会单独使用
deployment和deployment标签选择器就要符合匹配规则了,如果2个deployment都选择了一个Pod标签,删除任意一个deployment都会影响到Pod(也会随着选择器匹配删除)
DaemonSet
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: zabbix-agent
spec:
selector:
matchLabels:
app: zabbix-agent
template:
metadata:
name: nginx
labels:
app: zabbix-agent
spec:
containers:
- name: zabbix-agent
image: zabbix/zabbix-agent
env:
- name: ZBX_SERVER_HOST
value: 192.168.1.1
 会根据节点多少,每个节点运行一个Pod
会根据节点多少,每个节点运行一个Pod
controller-revision-hash:通过 Pod 的 label 来标识这个 Pod 所属的版本,会随着 Pod 升级而变化
pod-template-generation:如下网上找到的解释

Job和CronJob
创建Job
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
template:
metadata:
name: myjob
spec:
containers:
- name: hello
image: busybox
command: [ echo ]
args: [ "hello world"]
restartPolicy: Never
查看是否成功
 DESIRED 和 SUCCESSFUL 都为 1,表示按照预期启动了一个 Pod,并且已经成功执行
DESIRED 和 SUCCESSFUL 都为 1,表示按照预期启动了一个 Pod,并且已经成功执行
查看Pod状态,默认不加-a,只显示Running
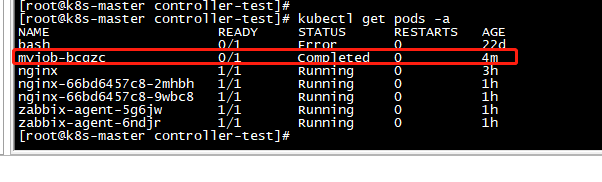
状态没有READY,执行完就结束了
Job失败会怎么样
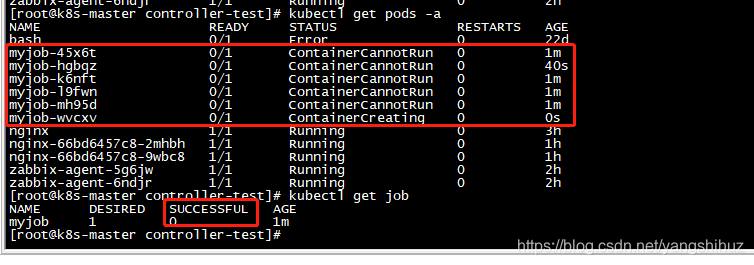
Job DESIRED 的 Pod 是 1,目前 SUCCESSFUL 为 0,不满足,而我的restartPolicy: Never,意思就是失败了,不会重启,那么不符合满足状态,所以 Job controller 会一直创建新的 Pod(数量受到bakcoffLimits限制,默认为6个)终止这个行为,只能删除Job
创建CronJob

Kubernetes 默认没有 enable CronJob 功能,需要在 kube-apiserver 中加入这个功能
kube-apiserver 的配置文件 :–runtime-config=batch/v2alpha1=true \ (重启服务)
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: mycronjob
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: [ echo ]
args: [ "hello world"]
restartPolicy: Never
查看是否成功
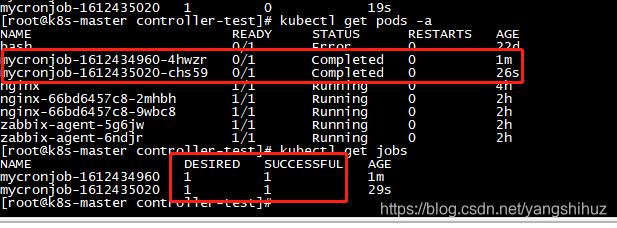
每一分钟启动一个Job运行( */1 * * * * )
参考:书籍:每天5分钟玩转 Kubernetes
参考:书籍:kubernetes进阶实战-马永亮
参考:https://kubernetes.io/zh/docs/concepts/workloads/controllers/