微信公众号图片爬取
朋友问我能不能爬取“隔壁有狗”公众号的图片,他想要所有的历史文章的图片。我虽然没爬过公众号,不过在略微的分析一下后我觉得还是可以满足朋友的需求的。废话不多说,动手干活!
一、准备工作:
打开 “电脑版微信”,找到公众号
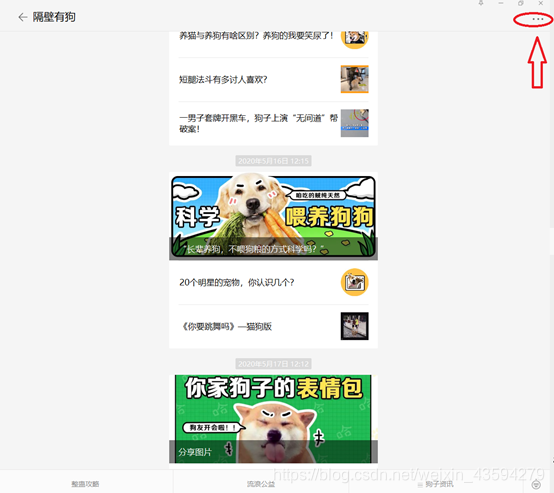
点击右上角,然后点击 “查看历史消息”选项,当然不止这一种方法,不过我们需要的效果就是出现以下的页面:
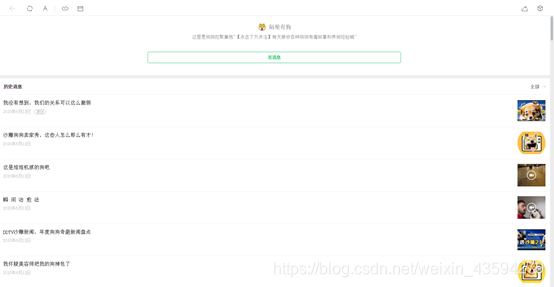
然后右键空白的地方,你就会发现有个“查看源代码”的选项,点击它以后会自动跳出一个txt形式的文本,里面放的就是这个页面下的源代码。你可以在当前页面随便复制一段历史文章的标题,然后在txt文件中查找,发现是可以找到的,而且还会发现这些文章的链接竟然也在源码中。
不过呢,这里其实有个陷阱,就是在这里查看到的源代码并不是全部历史文章的,它只有最开始你看到的那些历史文章。不假思索地,我把这个页面的滚轮拉到了最底,也就是这个公众号发布的第一篇文章的位置。

然后我们在最下方空白处右键“查看源代码”,你又会惊奇地发现这次打开的txt的内容明显比上一次要多很多,在txt查找框中输入第一个和最后一个文章标题并成功匹配后,自信满满地把源代码拷贝一份到本地,我们的准备工作就完成了。
PS:不要随便点击这个页面里的文章,否则又要重新拖动滚轮一次。
二、分析源代码:
以第一篇历史文章为例,点击“复制链接地址”和“用默认浏览器打开”获得的链接地址是一致的,可是呢在源代码中却又找不到。那只有一种可能,那就是能看到这篇文章的链接地址不止一个。
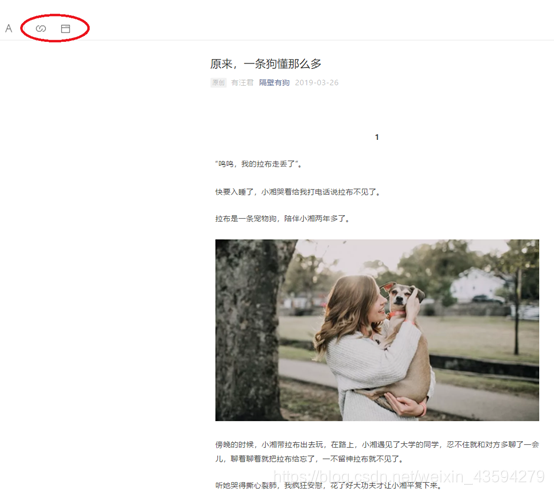
干脆还是按文章名寻找链接,既然名字都在源码里,链接不在里面就有点说不过去了吧。在源代码中查找文章名,结果如图,明显hrefs里就是我们需要的链接,打开看看后发现是可以的,看得出框架还是很清晰的嘛。
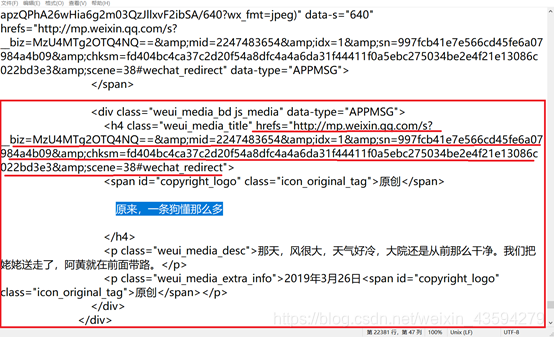
接下来就是网页的分析了,通过F12、右键审查元素,查看网页源代码,一整子的查找搜索后,发现图片的链接就在网页源代码中,这样我们就无需抓包操作,直接解析网页源代码即可。
三、爬虫编写:
我个人的习惯是建立两个py文件,其中一个取名为test.py,用来测试写到正式爬虫中的代码的正确性,写爬虫的过程总体是迂回探索的,模块化的编程让人有种搭积木的乐趣。直接上代码吧!
import requests #请求网页
import os #用于创建文件夹
from lxml import etree #使用其中的xpath
def start():
#第一层,获取公众号全部文章的链接
filename=’source.txt’#之前存在本地的公众号源代码
with open(filename,'r',encoding='utf-8')as f:
source=f.read() #读取内容
html_ele=etree.HTML(source) #xpath常规操作
hrefs=html_ele.xpath('//div[contains(@data-type,"APPMSG")]/h4/@hrefs') #锁定元素位置
num=0
for i in hrefs:
num+=1
try:
apply_one(i)
except:
continue
print('第%d篇爬取完毕'%num)
#第二层,解析单篇文章
def apply_one(url):
headers={
#可以用自己浏览器的User-Agent,也可以用fake-useragent库函数生成
}
#ps:fake-useragent举例
#pip install fake-useragent
#from fake_useragent import UserAgent
#ua = UserAgent()
#print(ua.random)
response=requests.get(url,headers=headers)
elements=etree.HTML(response.text)
data_src=elements.xpath('//section[contains(@style,"text-align")]/section/img/@data-src')
#print(len(data_src))
data_src=data_src[2:-1]
#print(len(data_src))
for src in data_src:
try:
download(src) #下载图片
except:
continue
#第三层下载层
def download(src):
headers={
'User-Agent': #自行添加}
response=requests.get(src,headers=headers)
name=src.split('/')[-2] #截取文件名
#print(name)
dtype=src.split('=')[-1] #截取图片类型
name+='.'+dtype #重构图片名
os.makedirs('doge',exist_ok=True) #当前目录生成doge文件夹
with open('doge/'+name,'wb')as f:
f.write(response.content)
if __name__=='__main__':
start()
四、总结:
很多类似的爬虫的编写都是一个从点到面的过程,首先突破一点,然后迭代等方法推广及面,由表及里,由浅入深。爬虫的学习是需要投入大量时间和精力的,想放弃的时候再咬咬牙,凭借那一丝执着和秉性,相信自己能突破难关;学习的过程也不是封闭的,可以和优秀的人多交流,不过还是提倡自己解决问题,实在没办法了再求救,因为你会发现只有自己才能真正救得了自己。希望大家从中有所收获,写得不好的地方还请大家多多包涵!