前言
服务间调用,作为客户端的一方,必须防止服务不可用,而造成客户端服务崩溃,引发雪崩。
调用方必须对每一个不可靠的服务调用,做到【熔断】机制。
- 熔断不只是用来做微服务保障的。就算不是微服务架构,也要接入熔断。
- 熔断机制,允许幻入。
- 熔断机制的场景有两种,在网关层熔断, 在调用位置熔断。
- 网关层熔断。这要求服务间调用必须都经过网关,不适合对调用第三方服务进行熔断,不适合对服务间直接不通过网关调用熔断。网关层熔断适合gateway + http/grpc/rpc 架构。网关层熔断,是调用方熔断的超集。
- 可以做在调用方,存在简单的代码侵入。本文也是基于调用方的熔断,进行实现。
【熔断】: 当某一个请求单位时间内,失败次数达到阈值时,该类请求进入熔断状态。熔断状态下,后续请求将直接返回错误,而不会真的去请求等待超时。熔断状态存在持续时间。
【熔断的作用对象】: grpc服务调用的客户端角色, http服务调用的客户端角色, tcp服务调用的客户端角色。
分析
熔断流程:
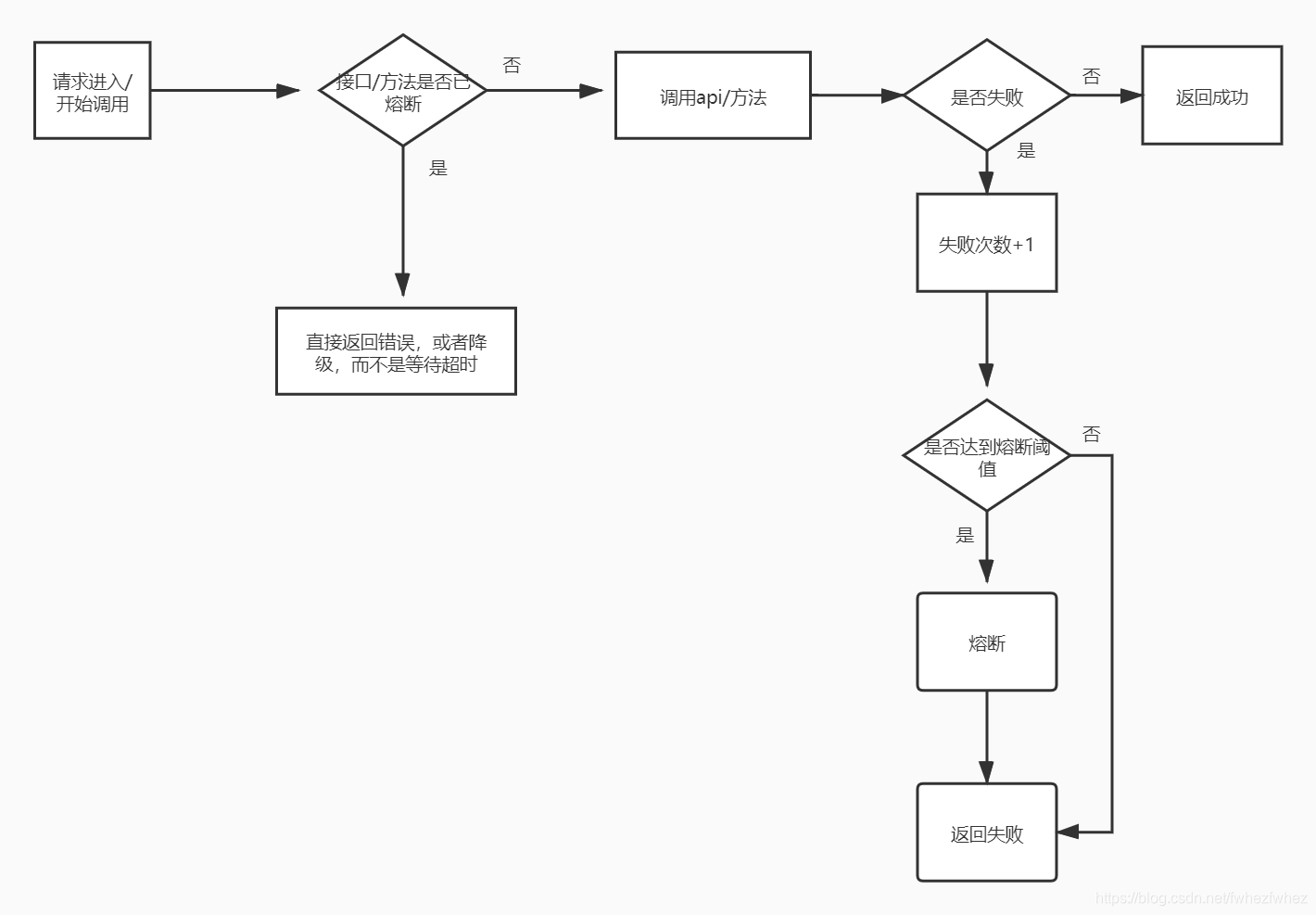
- 可以基于redis实现分布式熔断器。
- 可以基于单点实现熔断器。
熔断操作必须有以下4个属性:
- 【key】: 是针对什么操作进行熔断,不能因为一个路由挂了,而将整个服务不可用。
- 【fuseTimes】: 熔断阈值。达到多少失败次数触发熔断。
- 【last】: 熔断后,该熔断周期持续多久。
- 【perns】: 多少秒内,失败次数达到熔断阈值,进入熔断
示例:
对获取用户信息请求,10秒内,失败了50次,则将获取用户信息请求熔断,持续20秒。
{
"key":"/user/get-user-info/",
"fuseTimes": 50,
"last": 20,
"perns": 10
}
实现
1. 基于redis实现分布式熔断器
package redistool
import (
"fmt"
"github.com/garyburd/redigo/redis"
)
// 利用redis,来实现熔断
// 以下,是以http请求熔断示例:
/*
var fuseScheme = NewFuse(20, 30,10) // 10秒内,有20次失败,则会触发熔断,熔断最短持续30秒
func HTTPUtil(url string, ...) error{
key := url
if !fuseScheme.FuseOk(conn, key) {
return errorx.New
}
...
resp, e:= c.Do(req)
if e!=nil {
fuseScheme.Fail(conn, key)
return
}
if resp.StatusCode() == 404 || resp.StatusCode() ==500 {
fuseScheme.Fail(conn, key)
return
}
}
*/
type Fuse struct {
fuseTimes int // fail times trigger fuse. Fuse times is not strictly consistent,because fuse.FuseOK() might read dirty.
last int // fuse lasting seconds
perns int // fail times reach <fuseTimes> per <perns> seconds will trigger fuse opt.
}
func NewFuse(fuseTimes int, last int, perns int) Fuse {
return Fuse{
fuseTimes: fuseTimes,
last: last,
perns: perns,
}
}
// true, 未熔断,放行
// false, 熔断态,禁止通行
func (f Fuse) FuseOk(conn redis.Conn, key string) bool {
rs, e := redis.String(conn.Do("get", fmt.Sprintf("is_fused:%s", key)))
if e != nil && e == redis.ErrNil {
fmt.Printf("get '%s' 未熔断 \n", fmt.Sprintf("is_fused:%s", key))
return true
}
if rs == "fused" {
fmt.Printf("get '%s' 已熔断 \n", fmt.Sprintf("is_fused:%s", key))
return false
}
return false
}
// 某一次请求失败了,则需要调用Fail()
// 当fail次数达到阈值时,将会使得f.FuseOK(conn ,key) 返回false,调用方借此来熔断操作
func (f Fuse) Fail(conn redis.Conn, key string) {
ok := MaxPerNSecond(conn, key, f.fuseTimes, int64(f.perns))
// 未达到配置的熔断阈值,fail无操作
if ok {
return
}
// 达到了熔断点
fmt.Printf("set '%s' 熔断\n", fmt.Sprintf("is_fused:%s", key))
conn.Do("setex", fmt.Sprintf("is_fused:%s", key), f.last, "fused")
}
缺陷
- 失败次数存在窗口期,实际失败阈值,是a~2a次。a表示熔断阈值。
- 存在服务间调用开销。
鉴于熔断不需要保证强一致,以上缺陷问题不大。
2. 基于单点实现熔断器
单点熔断器,有三种思路:
- 使用有锁map来实现熔断器
- 使用 map 无锁来实现熔断器
- 使用hash+有锁map 来实现熔断器
第一种,所有熔断key都会进入race态,存在竞争场景。
第二种,需要程序运行init期,就将需要接入熔断的key,注册进map。在熔断过程中对map保持只读,但是通过atomic包,来直接修改value的值。
第三种,通过hash,降低了不同key的race场景,需要良好的设计基础。
这里呢,我们知道,不同的业务路由,显然,不应该具备race态,并且需要简化团队开发的维护粒度,至此,直接基于第三种实现。
package fuse
import (
"fmt"
"github.com/fwhezfwhez/cmap"
"time"
)
type Fuse struct {
m *cmap.MapV2
fuseTimes int
last int // second
perns int // second
}
func NewFuse(fuseTimes int, last int, perns int, slotNum int) Fuse {
return Fuse{
m: cmap.NewMapV2(nil, slotNum, 30*time.Minute),
fuseTimes: fuseTimes,
last: last,
perns: perns,
}
}
func (f *Fuse) FuseTimes() int {
return f.fuseTimes
}
func (f *Fuse) Last() int {
return f.last
}
func (f *Fuse) Perns() int {
return f.perns
}
// true, 未熔断,放行
// false, 熔断态,禁止通行
func (f *Fuse) FuseOk(key string) bool {
fuseKey := fmt.Sprintf("is_fused:%s", key)
v, exist := f.m.Get(fuseKey)
if !exist {
return true
}
vs, ok := v.(string)
if exist && ok && vs == "fused" {
return false
}
return false
}
// 某一次请求失败了,则需要调用Fail()
// 当fail次数达到阈值时,将会使得f.FuseOK(conn ,key) 返回false,调用方借此来熔断操作
func (f *Fuse) Fail(key string) {
multi := time.Now().Unix() / int64(f.perns)
timeskey := fmt.Sprintf("%s:%d", key, multi)
rs := f.m.IncrByEx(timeskey, 1, f.perns)
var ok bool
ok = rs <= int64(f.fuseTimes)
// 未达到配置的熔断阈值,fail无操作
if ok {
return
}
// 达到了熔断点
fuseKey := fmt.Sprintf("is_fused:%s", key)
f.m.SetEx(fuseKey, "fused", f.last)
}
业务里,要如何接入熔断,这里以http举例。
给所有http的api接入熔断机制
- 接入方是服务提供方,也可以是网关服务,当服务方/网关服务本身挂掉时,该熔断机制也会无效。
- 熔断仅会熔断某一条路由,不会熔断整个服务
- 接入熔断,要求所有的业务status必须为200。(之所以代码里写410,是因为307,400和403有大部分业务人员喜欢用,这三个码分别是重定向,参数异常,鉴权错误,这三个码容易产生,不能成为熔断指标)
package middleware
import (
"fmt"
"github.com/fwhezfwhez/fuse"
"github.com/gin-gonic/gin"
)
var fm = fuse.NewFuse(20, 10, 5, 128)
func ResetFm(fuseTimes int, last int, pern int, slotNum int) {
fm = fuse.NewFuse(fuseTimes, last, pern, slotNum)
}
func GinHTTPFuse(c *gin.Context) {
if ok := fm.FuseOk(c.FullPath()); !ok {
c.AbortWithStatusJSON(400, gin.H{
"tip": fmt.Sprintf("http api '%s' has be fused for setting {%d times/%ds} and will lasting for %d second to retry", c.FullPath(), fm.FuseTimes(), fm.Perns(), fm.Last()),
})
return
}
c.Next()
if c.Writer.Status() > 410 {
fm.Fail(c.FullPath())
return
}
}
测试用例:
package middleware
import (
"fmt"
"github.com/gin-gonic/gin"
"io/ioutil"
"net/http"
"sync"
"testing"
"time"
)
func TestGinFuse(t *testing.T) {
go func() {
r := gin.Default()
// 加入熔断保障
r.Use(GinHTTPFuse)
r.GET("/", func(c *gin.Context) {
c.JSON(500, gin.H{
"message": "pretend hung up"})
})
r.Run(":8080")
}()
time.Sleep(3 * time.Second)
wg := sync.WaitGroup{
}
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
time.Sleep(time.Duration(time.Now().UnixNano()%20) * time.Millisecond)
defer wg.Done()
rsp, e := http.Get("http://localhost:8080/")
if e != nil {
panic(e)
}
bdb, e := ioutil.ReadAll(rsp.Body)
if e != nil {
panic(e)
}
fmt.Println(rsp.StatusCode, string(bdb))
}()
}
// after 10s, will recover recv 500
time.Sleep(15 * time.Second)
rsp, e := http.Get("http://localhost:8080/")
if e != nil {
panic(e)
}
bdb, e := ioutil.ReadAll(rsp.Body)
if e != nil {
panic(e)
}
fmt.Println(rsp.StatusCode, string(bdb))
wg.Wait()
}
测试结果:
// 阈值前,会返回错误
...
500 {
"message":"pretend hung up"}
500 {
"message":"pretend hung up"}
...
// 达到阈值后,会直接熔断
...
400 {
"tip":"http api '/' has be fused for setting {20 times/5s} and will lasting for 10 second to retry"}
400 {
"tip":"http api '/' has be fused for setting {20 times/5s} and will lasting for 10 second to retry"}
400 {
"tip":"http api '/' has be fused for setting {20 times/5s} and will lasting for 10 second to retry"}
// 睡眠等到熔断时效失效,再次返回错误。无限循环,直到服务恢复
500 {
"message":"pretend hung up"}
结语
- 生产中,要如何去订制熔断器? 谨遵守:
- 每条失败,都应该具备报警机制。报警阈值必须小于熔断阈值。(确保熔断前可以收到报警)
- 熔断阈值【fuseTimes】/【pern】可以合理放高一点,熔断时效【last】合理放低。
- 为什么不考虑接入开源熔断组件?
- 熔断器实现起来并不复杂。
- 熔断组件只管具备中心网关的自相关服务调用,即,除非你保证该服务仅仅被网关服务调用,不能被外部调用,也不能被子服务直连。否则熔断效果不会生效。
- 历史原因,存在大量不走网关的直连服务调用关系。
- 你可能需要调用第三方服务时,需要仅对某一个请求,设置熔断。
- 熔断机制适不适合做成分布式的?
- 不适合,单点熔断和分布式熔断,没有明显差异,不需要共享次数,甚至,如果作成了分布式的,假设某一台机器和B服务网络不通,但是其他机器通,这台机器就会将熔断次数打满,造成其他正常的服务也跟随熔断。
- 熔断的恢复机制,是选择通了一次,清理掉历史积累的失败次数,还是选择不清理,等待key值自然失效。
- 适合自然失效(指代【last】)。首先失效key本身就不长,10-15秒适合,不会有严重后果。其次,如果发生了熔断场景,往往无法快速恢复不在乎这10-15秒。
- 熔断次数清零存在隐患。卡机的服务器,可能因为cpu/mem 飚高,服务时好时坏。每次清零时,都意味着阈值内的请求,可能依旧会失败。熔断存在幻入,失败的次数,可能比阈值会高很多。所以,对于出现过失败次数的路由,不清理熔断次数,当存在故障时,增加它的熔断可能性,以让其他正常的节点提供服务才是最好的。