参考链接:
论文原文:
Baird L. The swirlds hashgraph consensus algorithm: Fair, fast, byzantine fault tolerance[J]. Swirlds, Inc. Technical Report SWIRLDS-TR-2016, 2016, 1.
学习文章来源: https://zhuanlan.zhihu.com/p/35640075 作者:BlockGeeks
外网资料:
https://www.slideshare.net/anupriti/hashgraph-an-over-view-with-example
https://www.slideshare.net/calvinchengx/hashgraph-as-code-83446758
Swirlds的JDK下载:
https://www.swirlds.com/download/
其他Demo:
https://github.com/GovTechSG/hashgraph_experiments
https://github.com/calvinchengx/SwirldsProject
https://github.com/dappcoder/hello-swirld
参考请注明出处!
一、背景介绍
1.1 Hashgraph
Hashgraph狭义上来说是图论领域的一种数据结构,广义上来说是一种新型的共识算法。Hashgraph是一种DAG图,它不同于区块链的链式结构,而是一种以Hash算法为支撑的有向无环图。严格地说Hashgraph也不单单是一种共识协议,Hashgraph更像是一个底层的出块层而非一个完整的系统。Hashgraph的SDK中包含一个数字货币的Demo,但那仅仅用于演示证明Hashgraph可以用于构建数字货币。Hashgraph能为分布式APP提供高效、公平、安全的基础设施。高吞吐量和异步拜占庭容错(ABFT)的特点,使得Hashgraph在公链和私有链领域都有潜在的使用价值,并且,在保证去中心化的同时不需要繁重的工作量证明。
1.2 区块链与去中心化网络
2008年,Nakamoto发表了《Bitcoin: a peer-to-peer electronic cash system》报告,该文献中提出了一种去中心化、按时间顺序排序的数据,数据由所有节点维护、可编程和密码学上安全可信的分布式账本技术构成,用于解决比特币(BTC, bitcoin)在去中心化网络中的信任问题。
其核心区块链技术,从狭义角度来讲是一种按照时间顺序将数据区块以顺序相连的方式进行组合的一种链式数据结构,并以密码学方式保证数据不可篡改和不可伪造的分布式账本。从广义角度来讲,区块链技术是利用块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新账本数据、利用密码学方式保证数据传输和访问安全、利用智能合约来编程和操作数据的一种全新的分布式基础架构与计算范式。
区块链网络是一种分布式网络,分布式的网络不一定去中心化,但是去中心化的网络一定是分布式的。去中心化顾名思义就是指在网络中没有中心化的节点,去中心化网络的优点包括: 可构建在不信任网络下、P2P模式、安全性/容灾性高等,但是其也面临一系列挑战,例如单点故障、节点基数大并且数量不确定(递增)、恶意节点发布错误信息、篡改信息、不合作等。
1.3 共识协议
在分布式系统中,多个主机通过异步通信方式组成网络集群。在这样的一个异步系统中,需要主机之间进行状态复制,以保证每个主机达成一致的状态共识。然而,异步系统中,可能出现无法通信的故障主机,而主机的性能可能下降,网络可能拥塞,这些可能导致错误信息在系统内传播。因此需要在默认不可靠的异步网络中定义容错协议,以确保各主机达成安全可靠的状态共识。
中心化的系统达成共识非常的简单,因为一切数据都由中心化管理,而对于去中心化的区块链系统来说,共识则很难达成,一切都要商量这来。不同的共识算法就是不同的商量规则,通过设置不同的一组条件筛选出最具有代表性的节点来达成共识。
二、研究现状
2.1 图论研究历程
图论〔Graph Theory〕是数学的一个分支。它以图为研究对象。图论中的图是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。
人们常称1 736 年是图论历史元年,因为在这一年瑞士数学家欧拉发表了图论的首篇论文《哥尼斯堡七桥问题无解》,所以人们普遍认为欧拉是图论的创始人。从19世纪中叶到20 世纪中叶,图论问题大量出现,如哈密顿图问题、四色猜想等。这些问题的出现进一步促进了图论的发展。1847 年,克希霍夫用图论分析电网络,成为图论最早应用千工程科学的一个例子。在很长一段时期内,图论被当成是数学家的智力游戏。一些著名的难题,如迷宫问题、棋盘上马的路线问题、四色问题和哈密顿环球旅行问题、任务分配问题和地图着色问题等, 吸引了众多的学者。图论中许多的概念和定理的建立都与这些问题的解决有关。近几十年来,随着计算机科学的发展,图论以更加惊人的速度向前发展。
2.2 区块链共识算法
目前区块链的共识算法大致可以分为四类:①工作量证明类的共识算法②Po凭证类的共识算法③拜占庭容错类共识算法④结合可执行环境的共识算法。
工作量证明类的共识算法最为代表性的就是比特币使用的PoW算法,PoW算法是以每台计算机的算力即CPU的计算能力作为共识竞选的筹码,每台计算机需要解决一个数学难题,谁先解出这个数学计算上的难题就拥有了打包交易的权利,也就是记账权。Pow算法最为被诟病的是对资源的浪费问题。所以,后面出现了使用凭证类的PoS和DPoS等Po凭证类的共识算法。PoS不采用“挖矿”计算来选择交易的打包者,而是通过哦持有数字货币的量以及时间来权衡出块者的选择,整个过程类似于股票制。权益证明必须采用某种方法定义任意区块链中的下一个合法区块,依据账户结余来选择将导致中心化。此后,又提出了DPoS的委任权益证明共识算法,其通过权益投票选择出一系列超级节点或者说代表节点去专门生成区块,大大提高了出块速度,但是其去中心化的程度上仍不及PoW,是一种多中心化的方案。
拜占庭类的共识算法在联盟链中大行其道。拜占庭将军问题最先在Leslie Lamport描述分布式系统一致性问题中的论文中提出,拜占庭容错能力是描述当前网络系统能够容纳错误节点和恶意节点并能够达到正确的一致性共识的能力,拜占庭容错系统是一个拥有n台几点的系统,整个系统对于每一个请求,满足以下两个条件:1.所有非拜占庭节点使用相同的输入信息,产生相同的结果;2.如果输入的信息正确,那么所有非拜占庭节点必须接受这个信息,并计算相应的结果。目前实用拜占庭容错算法PBFT是各大联盟链的主流共识算法,PBFT要求共同维护一个状态,所有节点采取的行动一致,因此需要运行三类基本协议,包括一致性协议,检查点协议和视图更换协议,这里不在详细展开。
工作量证明共识算法是最终一致性的共识算法,属于概率上的实现了拜占庭容错,概率的大小取决于网络中诚实节点的个数,而PBFT则是强一致性的共识算法。此外两者的引用场景也不同,前者一般应用于公链,而拜占庭协议则一般应用于联盟链。在出块时间来看PoW需要平均大约10分钟,而PBFT出块时间非常迅速。
目前各类共识算法层出不穷,不同的算法都有不同的适用场景。总体上来看,目前的方向大多是在保证一定去中心化程度的条件下提高区块链系统吞吐量,以此来满足实际的业务需求。
三、Swirlds共识算法的研究
Hashgraph是Swirds公司抱有专利的一种分布式账本共识,也没有区块概念,交易跟交易直接组成DAG。hashgraph通过gossip of gossip协议,让每个节点都维护着所有节点跟其他节点的通信历史,每个节点在完成拜占庭协议时,居然不需要经过网络多轮通讯,节点本地环境就可以直接模拟拜占庭决议。
3.1 Hashgraph数据结构
3.1.1 event事件数据结构
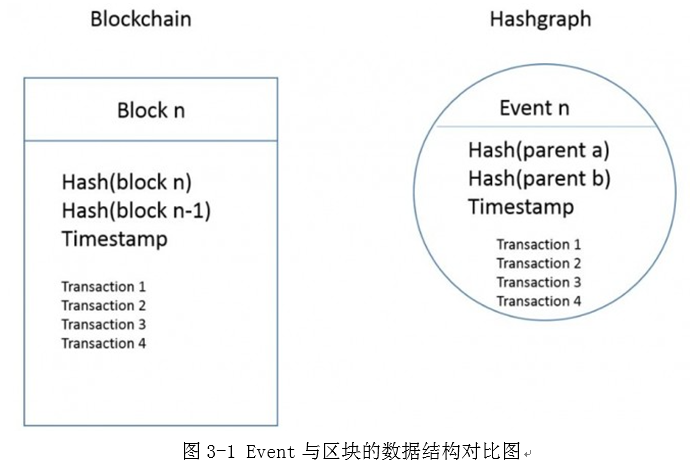
Hashgraph协议中没有区块链中区块的概念,而是产生了与之非常类似的Event(事件)的数据结构,图3-1右图展示了该数据结构的内容,其中包含了两个Hash值,前一个Hash指针指向上一次最新的事件,后一个Hash指针指向其他节点传递的最新事件。结构的下方存储了当前节点记录的各个交易,最后对整个事件加上时间戳并且签名,这样就构成了整个事件的结构。
3.1.2 Hashgraph图数据结构
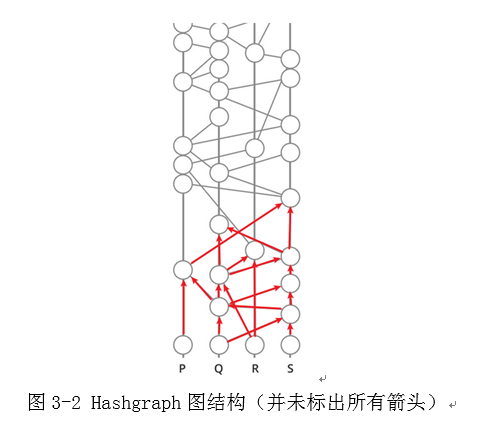
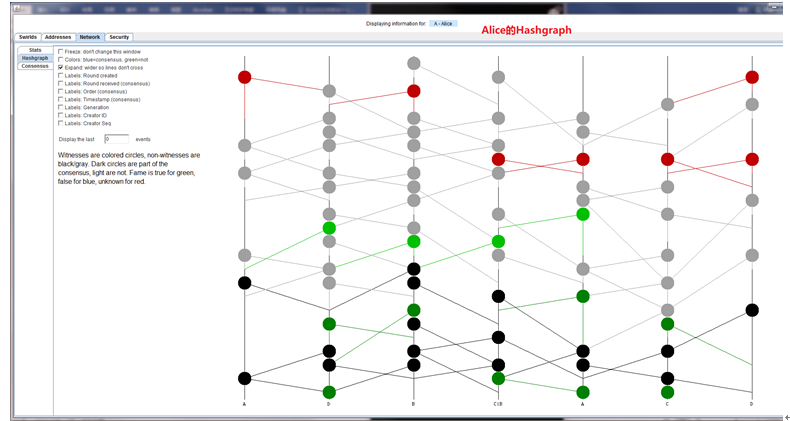
Hashgraph是一种有向无环图,图3-2展示了P、Q、R、S四个网络工作节点在执行算法过程中构造出的Hashgraph结构,其中纵轴代表着时间,由底向上是时间的顺序,纵向四条主轴线上的每个原点就代表着单个Event,图中的箭头就代表着Hash指针的方向。从图中可以看出,除了初始的Event,每一个Event的入度都为2,从时间轴来看这些入度都是由下指向上方,每一个Event的出度大小都是不确定的,这由Gossip协议与网络的随机性决定。由于这样特殊的数据结构也就构成了Hashgraph有向无环的特性。
3.2 基础概念
3.2.1 Gossip协议
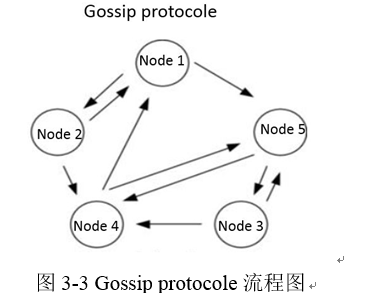
Gossip protocol也叫 Epidemic Protocol(流行病协议),实际上它还有很多别名,比如:“谣言算法”、“疫情传播算法”等。Gossip protocol 最早是在 1987 年发表在 ACM 上的论文 《Epidemic Algorithms for Replicated Database Maintenance》中被提出。主要用在分布式数据库系统中各个副本节点同步数据之用,这种场景的一个最大特点就是组成的网络的节点都是对等节点,是非结构化网络。
他的工作原理非常的简单,类似于办公室谈论八卦,当一个节点知道一项新消息,而其他节点却不知道时,就向其他节点分享自己知道的信息,收到新消息的节点再向外发送信息,这样一步一步的传递下去,直到这个消息在整个网络收敛。
3.2.2 绝对多数(supermajority)
对于一个需要达成共识的网络来说,当一个新的提案提出时,需要绝对多数的人同意才可通过,这个绝对多数的量化就是指网络中同意的节点数要超过2/3以上的数量,DPoS、RAFT共识算法中也用到了这个概念。
3.2.3 可见(see)与强可见(strongly seeing)
每一个Event都有两个Hash指针,分别计算自自己的上次最新事件与接收到他人的最新事件,那么通过这两个Hash指针的Hash值就可以溯源到上两次子事件,这个方向是与取Hash的方向相反的。举例来说,设有两个事件A与B,当事件B可以沿着哈希指针找到事件A,那么事件B就可见(see)事件A。当事件B能找到事件A的所有路径中跨越了绝对多数(2/3)的节点,那么事件B强可见(strongly seeing)事件A。在Hashgraph的白皮书中提到经过数学论证可以保证两个强可见的节点在虚拟投票时能获得一致的结果
3.2.4 见证人(witness)与知名见证人(famous witness)
这两个概念都是对Hashgraph中事件身份的表示,每个节点在每个轮次(round)中创建的第一个事件就是见证人事件,即该轮次的祖先事件,节点可能在某个轮次中没有见证人事件。如果R轮的见证人能被绝对多数(2/3)的R+1轮见证人可见,则它就是知名见证人。具体的计算方法详见后文。如果既不是见证人事件也不是知名见证人事件,那么其就是一个普通事件。
3.2.5 创建轮次(round created)与接收轮次(round received)
一个事件的创建轮次是R或者R+1,其中R是该事件父节点的最大轮次。当且仅当事件能强可见绝对多数的R轮见证人,则该事件的创建轮次为R+1。如果R轮(创建轮次)中的所有知名见证人可见某一普通事件,则该事件的接受轮次就是R轮,如果某普通事件没有被R轮所有知名见证人可见,则它的接受轮次一定晚于R轮。
3.3 算法核心
3.3.2 谣言的谣言(Gossip about Gossip)
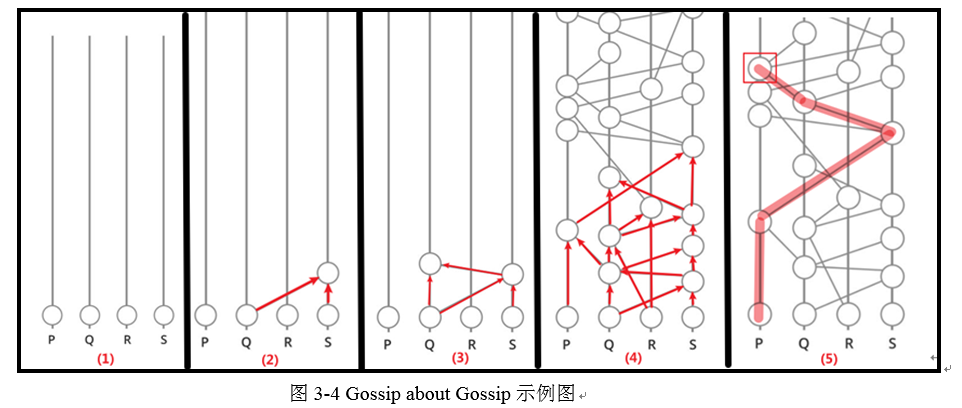
以举例的方式描述算法的流程。目前假设网络中共有四个节点,分别为P、Q、R、S,并且他们都有了自己的初始事件,如图3-4(1)。
下一步,Q节点需要分享自己事件以此来让其他节点知道,此时随机选择一个节点传播,选择了S节点传播消息,Q节点发送所有他自己知道而S不知道的信息给S,S确认消息后创建一个新事件,其中的Hash指针同时指向S和Q的最新事件,如图3-4(2)。
同样的,谣言算法会使节点间继续传播消息,从而生成新的事件,如图3-4(3)
现在,Q节点收到了包含三个事件的消息,其中包含了Q的初始消息、S的初始消息、以及上一步的S最新消息,随着消息在节点间不断传播,整个Hashgraph结构就慢慢显现出来,因为是依靠Hash指针来连接每一个事件并且构成了一个图,所以称之为Hashgraph,如图3-4(4)。
对于每一个节点的最新事件来说,其通过Gossip about Gossip协议和Hash指针摘要了整个网络历史事件。图3-4(5)单独画出了P的最新事件的由来,图中可以看出当前最新事件涵盖了网络的事件历史,个人理解于在图中构建了类似区块链的事件链结构。这个过程为后续的虚拟投票打下了基础。
3.3.3 虚拟投票(visual voting)
通过上面的Gossip about Gossip 算法解决了Hashgraph在节点之间通信,但这仅仅只是通信步骤,节点之间达成共识还需要虚拟投票机制,虚拟投票是因为通过执行谣言算法后所有节点都是全节点,都存储了完整的网络历史,在需要对某一提案达成共识时并不需要大规模的消息通信,每个节点独立执行投票算法,并且所有节点一定会得出相同的共识结果。
同样的,通过描述示例来阐述整个流程。对于网络中的A、B、C、D四个节点,如图3-5(1)所示,对于已经划分好轮次的一个Hashgraph来说(具体划分依据会在后面阐述),下面计算每个节点的创建轮次。
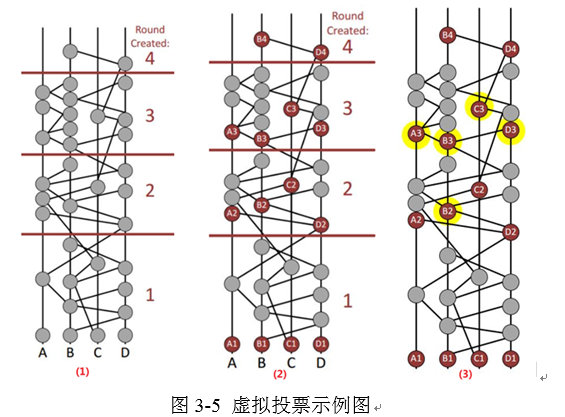
根据见证人的概念即每一轮的第一个事件就可以标记为见证人事件,将图中的见证人事件标记出来,如图3-5(2)所示。
下面判断是否为每个见证人是否为知名见证人,下面以判断B2是否为知名见证人为例,整个过程可以划分为两个部分:①投票②统计票数。根据知名见证人的定义,其上一轮次的A3、B3、C3、D3中必须绝大多数可见B2,这样B2才会成为知名见证人。这个过程很类似于投票选举,所以叫做虚拟投票。如图3-5(3)所示。
当上一轮次的节点能够可见B2时,就代表投票YES反之NO,那么投票的结果应该如下:(注意,寻找是否可见的路径时,必须是从上往下找,因为Hash指针的链状结构是不可以正向遍历的)

经过投票后所有见证人都投YES,因此我们判断B2事件将是知名见证人,但是此时的虚拟投票过程并没有结束,计票必须由下一轮见证人完成,因此B4和D4将进行计票,虽然图中没有A4和C4,但是随着时间推移它们一定会出现并且也将参与计票。
在计票阶段,R+2轮(这里就是第四轮)见证人会从自己强可见的R+1(这里就是第三轮)见证人处收集投票结果,一旦某个投票结果的计票数量超过绝对多数即认为该结果有效,也就是达成共识。根据数学理论证明,任何一个R+2轮见证人如果对投票结果做出了决定,那么这个结果就是全网的结论,如果R+2这轮见证人无法做出决定,就由下一轮R+3见证人计票决定,直到得出确切结论,这个过程就是最终一致性特点的体现。具体来看个例子,B4到A3有三条可见路径且跨越了3个节点,因此B4强可见A3事件,即B4从A3处收集到的投票结果是YES,同样的B4强可见B3、C3、D3,所以都从他们那里收集到了YES的票据。最后,终于得出了结论:B2是一个知名见证人,如图3-7(1)所示。
需要提出的是,什么时候计票会推迟到R+3轮(第五轮)或者更靠后呢?可能是以下这种情况,当B4计票时得到的结果是2:2,那么其就无法判断B2是否为一个知名见证人了,这轮计票就延期。白皮书中提到,如果我们在每个十轮中增加一个随机的轮次(coin round),那么计票就以1的概率收敛,也就是几乎必然收敛,所以可以认为是会必然结束。在随机轮中,收集到绝对多数结果的见证人仅投票而不做决定,而其他见证人则根据数字签名的中间位进行随机投票。
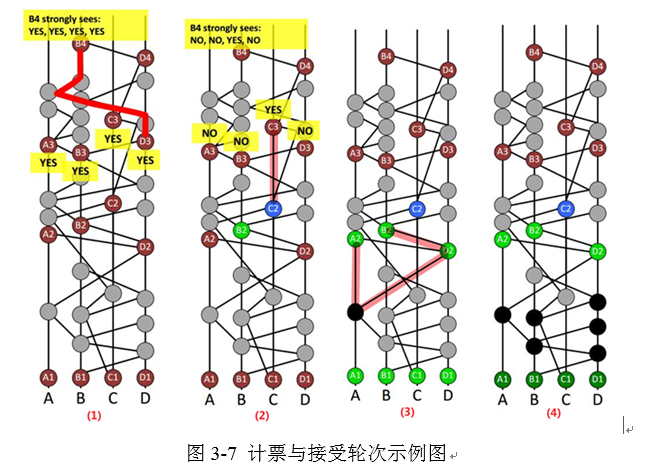
同样的,下面对C2进行知名见证人投票,投票的结果如下,因为A3、B3、D3均没有路径可以到达C2,所以都不可见C2,投票结果为NO。所以,再经过计票可以知道C2不是一个知名见证人,如图3-7(2)所示。
最终对第二轮的见证人判断结果如下:知名见证人A2、B2、D2,普通见证人:C2。当某个轮次的所有事件都被确定了是否为知名见证人后,就可以为这一轮次中的其他普通事件确定接受轮次和共识时间戳(consensus timestamp),根据接受轮次的定义,必须这一轮次中的所有知名见证人可见,如图3-7(3)所示,黑色标记的普通事件可以被第二轮的所有的知名见证人可见,那么其接收轮次就是2。
下面开始计算黑色事件的共识时间戳,确定时间戳的作用就是为后续确定共识顺序。对于当前普通事件,寻找其共识成员,范围是其接受轮次的所有知名见证人的节点,对于本例中的黑色事件就是A节点、B节点、D节点(C节点上的C2不是知名见证人,所以排除),条件是对于当前X节点寻找其最早的事件Y,它既是Y事件的祖先也是当前普通事件(本例中黑色事件)的儿子。这些节点选择出来后,将他们的时间戳依次排序,其中位数就作为当前普通事件(黑色事件)的时间戳。简单的来说就是寻找时间戳范围在当前普通节点时间与知名见证人时间之内的所有节点,然后确定其共识时间戳。(当找不到该怎么办?这个事件只限定于当前节点时间轴上吗?)同样的方法求出所有的普通事件以及其共识时间戳,图3-7(4)展示了所有的普通事件。
现在我们确定了10个接受轮次为2的事件(图中黑色事件以及A1~D1),我们将为其排序得到全网公认的顺序,即共识顺序。我们按照以下优先级进行排序:
- 接受轮次
- 共识时间戳
- 按事件签名和某随机数异或的结果排序,这个随机数通过该轮所有知名见证人的数字签名进行异或运算得到
这样整个共识算法的过程就结束了,得到了某个轮次或者说状态机的某个状态下的以时间序列的一系列共识结果。
3.4 结论
Hashgraph是“互联网和分散技术的未来”,被设计成一种可替代区块链的高级一致性机制/数据结构。他的特点是①交易非常快速,根据官网的测试数据,可以达到惊人的 250000 TPS,②公平,用数学通过一致的时间节点确保公平运用数学理论通过一致性时间戳证明得到的公平意味着任何人都不能操纵交易的秩序。③安全,银行级安全(异步拜占庭容错,Asynchronous Byzantine Fault Tolerant),排除了不良行为,防止其达成共识。④独特性:Hashgraph使用虚拟投票和小道消息而非POW或POS来达成分布式一致性,这是非常独特的想法。Hashgraph的共识过程相比于其他算法有很大的创新,有相当的安全理论证明,并且验证简单,同时其高并发低延迟的特性目前正在进行测试中。
Hashgraph实现了异步的BFT,因为在极小概率下共识算法可能会无限执行,但是这一概率几乎为0,具体来说就是在计票过程中出现延期,但是也有相应的机制去保证避免无线延期(随机轮)。Hashgraph的共识算法是非确定性的,但是能保证最终确定性,也就是说我虽然无法保证在某个时间点下所有节点状态保持一致,但能保证在最终某个时刻下所有节点对某个时间点之前的网络历史达成一致,这与PoW是相似的。同时因为所有节点都是对等节点,避免了潜在的DDOS攻击风险,这些都是这个算法优点。
其次,Hashgraph也不是没有缺点,Hashrgaph目前并没有开源,整个共识系统由一家商业软件公司所有(Swirlds)。通过上文的分析,不过谣言算法真的适用于大规模公链环境依然值得商榷,因为一旦大规模的节点加入与退出这个Hashgraph的遍历时间以及安全性是否还有保障难以确定,而在私有链场景,Hashgraph已经成功应用于不少2B系统中。其次,在Hashgraph协议中所有节点必须保存全网数据,不知如何解决数据压缩问题。
四、核心算法
4.1 Swirlds算法核心
4.1.1 核心算法
每个成员重复调用随机选择的其他成员,并与它们同步。与传出同步并行,每个成员接收传入同步。当A节点同步到B节点时,她发送她知道B不知道的所有事件。B将这些事件添加到Hashgraph中,只接受具有有效签名且包含他所拥有的父事件的有效哈希值的事件。然后,所有已知的事件都被分成若干轮。然后每个回合中每个成员(“目击者”)的第一个事件,通过纯粹的本地拜占庭协议和虚拟投票来决定是否出名即是否是知名见证人。然后在那些有足够信息的事件上找到总顺序。如果两名成员分别为某一事件分配历史上的一个位置,即使有更多的信息进来,他们保证分配相同的位置,并且保证永远不会改变。此外,每个事件最终都被分配了这样一个位置,概率为1。
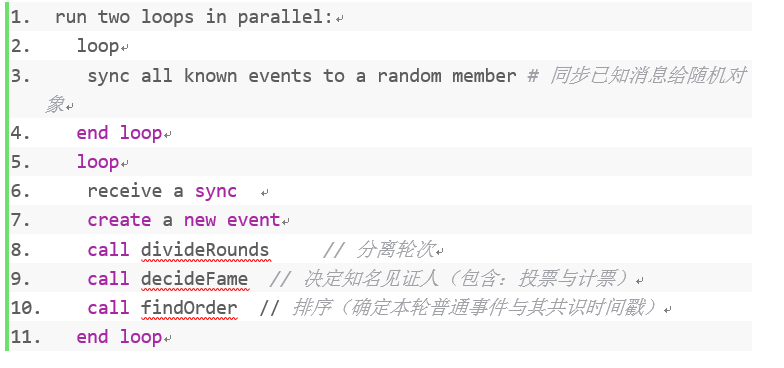
算法的核心架构是分为两个循环,这两个循环不是顺序执行的,而是同步执行的。第一个循环是实现Gossip算法,将新的事件在网络中分享。第二个循环就是执行打包生成新事件以及虚拟投票算法。
4.1.2 DivideRounds分离轮次算法

循环遍历事件,一旦知道事件X,就给它分配一个整数X.round,并计算布尔值X.witness,指示它是否是一个“witness”(见证人),即成员在该轮中创建的第一个事件。算法对于每一个事件(接收到的同步事件),首先设置当前R为事件X的最大/新轮次,然后判定当前事件X是否强可见R轮次的绝大多数见证者,如果是的话就将其归为第R+1轮(产生新的一轮),如果不是的话就将其还是归为当前的R轮。最后,设置其是否为见证人,这要满足以下两种条件之一就可以认为其为见证人:①当前事件X并没有自己的父事件即当前事件X为当前节点的首个事件及初始事件②当前事件的轮次比它父事件轮次大即当前事件是当前轮次的首个事件。
4.1.3 DecideFame知名见证人算法

对于每个见证事件(例如,一个事件X,其中X.witness为真),决定它是否著名(例如,给X.famous赋一个布尔值)。这个决定是通过一个基于虚拟投票的拜占庭协议协议来完成的。每个成员在自己的Hashgraph副本上本地运行它,不需要额外的通信。它将Hashgraph中的事件视为向彼此发送投票,尽管计算只在成员的计算机上进行。在几轮投票中,成员将选票分配给每一轮的证人,直到超过2/3的人同意。要找到x的名气,请在不断增长的Hashgraph上重复运行此操作,直到X.famous接收到一个值。
首先将这些见证人事件是否为知名见证人即famous值都为不确定。然后再遍历每一个轮次比事件X大的事件Y,D记录两者轮数之差,是为后续的收敛做准备。S是Y轮次-1中强可见的见证人事件集合(S就是投票人,T就是计票人),S进行投票, V保存着大多数人的投票结果(TRUE OR FALSE),投票的依据就是与当前事件X是否有连线(向下是否可达),T统计了S事件集合中与大多数投票结果(即V)相同的事件个数。如果D为1,那么就代表着这是第一轮选举(被投票事件、投票事件、计票事件相邻轮次),如果Y能够可见X,那么Y就计票为TRUE。当D在常数C(之前举例是10)轮次内(D mod C > 0),那么这就是一般轮次,在一般轮次中,如果T为绝大多数那么就可以做出决定了,这时,X设置为知名见证人,Y的投票结果为TRUE,退出关于事件Y的循环。否则Y仅仅投票为V,而不对X做出决定。如果D到了常数C的轮次(D mod C== 0),那么就产生随机轮次,同样的如果T满足绝大多数,那么Y就投票,否则Y就采用随机取值的办法,类似于抛硬币,去Y签名的一个中间Bit作为结果,因为已经经过了太多轮次需要一个结果来使其收敛。
(疑惑:y.vote的作用是什么?)
4.1.4 FindOrder排序算法

一旦R轮中的所有证人都决定了他们的名声,找到那轮中的知名见证人集合,然后从集合中删除与该集合中任何其他证人拥有相同创造者/父事件的任何知名见证人。剩下的知名见证人就是唯一的知名见证人(唯一是指一个节点一个,而不是总数一个)。他们充当裁判,分配较早的事件的接收伦次和一致的时间戳。一个事件被称为“收到”在第一轮,所有唯一的知名见证人都收到了它,如果所有之前的轮次都有所有证人的名声决定。它的时间戳是每个成员首次收到它的那些事件的时间戳的中值。一旦这些被计算出来,事件都按接收伦次排序。所有的联系都按照一致的时间戳进行排序。任何剩余的联系都是由加白的签名再排序。加白的签名就是回合中所有唯一的知名见证人的签名。
循环遍历事件,对于当前事件X,如果存在这样一个轮次R,其当前轮次没有事件Y或者之前轮次的Y事件只是见证人而不是知名见证人,并且X事件是R轮次每个唯一知名见证人的祖先,并且R轮次是最早的(这个过程其实就是找出普通事件),那么确定X的接收轮次为R,S集合保存了每个事件Z,使Z是轮次R的自祖先开始唯一见证人,X是Z的祖先,但不是Z的父事件(在X之前的都是祖先,在X上一代的是父事件)。最后,返回所有已有接收伦次但不著名的事件,按接收伦次排序,然后按共识时间戳排序,然后按白签名排序。
4.1.5 JavaDemo测试
区块链网络结构
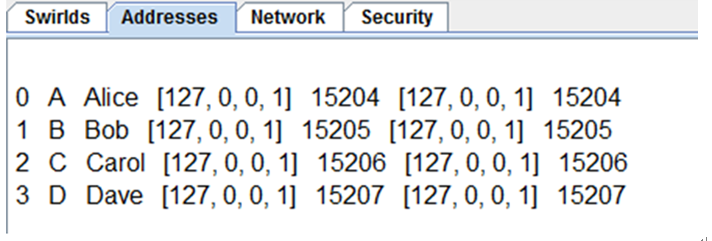
HelloDemo
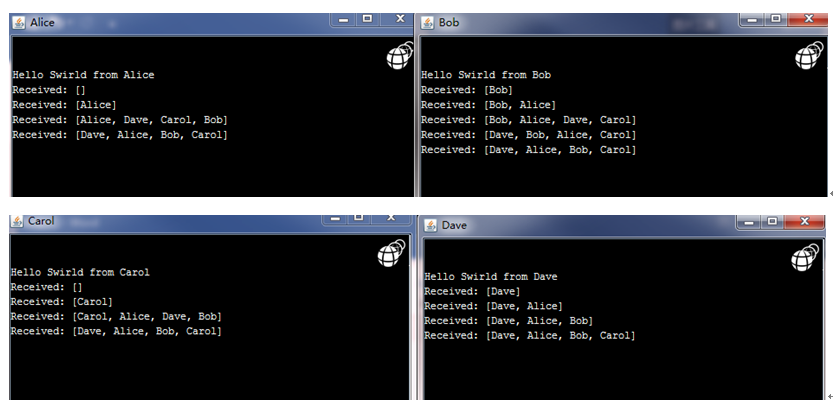
谣言算法
Hashgraph

GameDemo

HashgraphDemo

CryptocurrencyDemo