有朋友说让讲讲SQL的调优,其实这类文章全网都是。想说点自己的理解,又怕写的又臭又长。所以先把提纲列前面,没有帮助的同学可以直接关掉了。
SQL优化,总共可以分为三层:数据库系统、数据库设计、程序设计。我按照先易后难的顺序,又分为表设计优化、查询优化、索引优化、架构优化、业务优化5方面:
目录

通常来说SQL优化指的都是查询优化,但是最坑的是我们的对手 遇不安套路出牌,很多挑战通常不能用SQL技巧解决。
①影响性能的原因
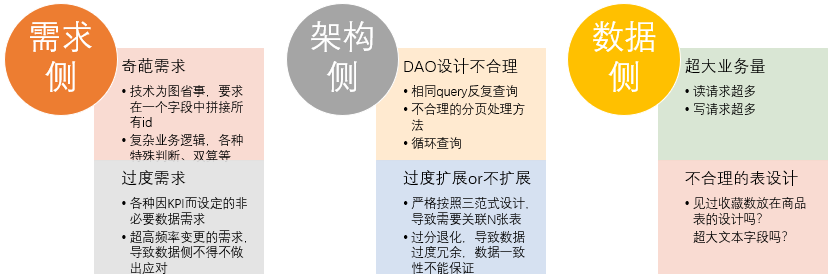
影响SQL性能的原因有很多,最令人头疼的是需求侧。业务方不关心你的sql怎么写,他们只要结果,甚至有些时候技术端也会出一些奇葩的要求。
架构侧导致的问题也挺多的,典型的问题是分页、过度退化(业务 宽表)等。

其实数据侧的问题是比较容易达成共识,并解决的。
所有的SQL性能低的原因中,SQL本身的原因是最容易解决的。
②表设计优化
编码规则设计:
开发设计的树形结构设计一般只增加一个父ID,其实我们还可以增加业务code和层级标识。业务code一般会有编码规则,以中国行政地区代码为例,每2位代表一层,随便拿一个code,通过字段截取,就能直接查到任意父节点对应的内容。
数仓建设的时候,抽离三级地区维度也非常容易,限定layer层即可。
扩展信息表
将核心信息放在主表中,将写频繁、新增的字段放在扩展信息表中,进行部分业务的解耦。设计是一个平衡的过程,跨表则多一次关联,都放一起则造成臃肿。
字段选择
tips:大文本、图片建议存文件,数据库中存路径即可。
③查询优化
基本思路:
1、有大炮,就别用手枪。查询要走索引
2、溺水三千只取一瓢,不要select *
3、数据库是用来存的,不是用来算的,查就查,不要算
1
工具(以MySQL为例):
1、用Explain查看 SQL 执行计划:
可以发现主要拖慢效率的内容,比如某个表数据量大,资源消耗多。
2、通过 Profile 查阅每一步的资源消耗:
可以发现每一步的资源消耗,涉及多少数据,消耗多少时间等。
3、通过 Optimizer Trace 表查看 SQL 优化器生成执行计划的过程,逐步优化时好用。
基本上用explain和profile就能掌握sql执行的所有消耗,然后根据以下原则,进行优化,顺便开启Optimizer Trace看看自己优化的是否对路:
2
1、禁止使用“%”前导的查询
2、所有表都加别名,需要加在所有字段前面match
3、用union代替or
4、null 值判断、!=或<>操作符会导致全表扫描
5、用between、exists代替in,用not exists 代替not in
6、禁止使用select *
7、小结果集join大结果集
8、使用limit
9、减少where中对字段的计算操作
④索引优化
上面的SQL优化技巧中,禁止的原因基本是使索引失效。索引太重要了,因此单列一章详细讲讲。
3
索引的设计:
1、单张表中索引数量不超过5个;
2、单个索引字段数不超过5个;
3、频繁修改的字段上不建议建索引;
4、区分度越大,索引效果越好;性别字段建索引,等于没建;
5、索引字段尽量短,尽量选择数字字段
6、在查询、排序、分组、where判定频繁的字段上建索引
7、经常删数据的表,定期清理
8、用join代替子查询
4
索引的使用:
禁止在索引列进行数学运算;
使用联合索引时,按顺序查询(索引的最左原则);
尽量在索引同时满足查询和排序;
字符串索引使用前缀索引,前缀长度不超过10个字符;
索引join时,使用的字段类型要一样;
⑤架构优化
架构层面轻易不动,一动就是大工程,其核心是分开:
1、主从+读写分离
2、分库分表
数据库事务主要就是读和写,这俩分开之后读操作可以占有服务器的所有资源,自然就快了。
分库是垂直切分,按照业务领域,将关系比较紧密的表分到同一个库中,原本一个数据库垂直切分为N个业务库,每个库的压力就小了,效率就高了。
分表是水平切分,对某个表按规则横向切分成N个小表,单表数据量就变小了,查询效率也就变高了。