Snort
我在上一篇博客已经讲述,如何进行windows xp下的Snort+mysql配置,其余的windows系统也大差不差。
本章节主要内容是Snort规则的学习与编写,这样我们就能通过Snort检测到许多木马了。
Snort概述
Snort是一个翻译,
他自己不会说英文(抓包),只会把听到的英文(从libpcap抓到的包)翻译成中国话说出来(分析后,展示给我们)。
Snort2.9以上的版本能把更多语言翻译成中国话(支持更多抓包的框架)。
Snort规则学习
能翻译了,比如 one对应一,handsome boy对应大瑞大(优美的中国话 ),就要按照一定的规则把中国话说出来。
Snort就按照一定的规则,把解析后的包展示出来。
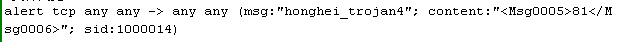 比如msg:信息等等。
比如msg:信息等等。
一些规则如下
| 名字 | 内容 |
|---|---|
| msg | 展示的信息 |
| reference | 该条规则的参考网站 |
| sid | 该条规则编号(是keyword) |
| rev | 规则版本 |
| content | 内容 |
| offset | content起始偏移 |
| depth | content终止偏移 |
| distance | 下一个content的起始偏移 |
| nocase | 大小写不敏感 |
| raw_bytes | 对数据包未解析好的数据,进一步解析 |
| isdataat | 在某个偏移是否有数据(有的话应该就是payload) |
| flow | 数据流会干什么(会干tcp之类的) |
| 竖线0A竖线 | 代表0A的转义字符 |
不再详细列举啦,具体的规则内容可以参考官方文档
Snort规则编写
学习规则处理,我们就可以编写了,写一个规则康康:
alert udp any any -> any any (msg:"lvguang_trojan1"; content:"retkey"; sid:1000001)
这个意思是:
报警:是个udp包,包的内容包含retkey,是因为遇到了绿光木马。
就是这个泛着绿光的木马。
流量特征处理
那么,我们知道了Snort的流量检测,该如何消除这些特征:
消除流量特征
1、对数据包做编码(加密),在Web木马里面先解码数据包(解密),再执行。
2、web木马先访问正常网站,获取正常数据,正常数据被解释为远程执行命令。(也是加密)
3、等等等…笔者能力有限,欢迎补充。
检测特征是否消除
截取流量保存为pcap包,再用Snort检测pcap包是否会报警。
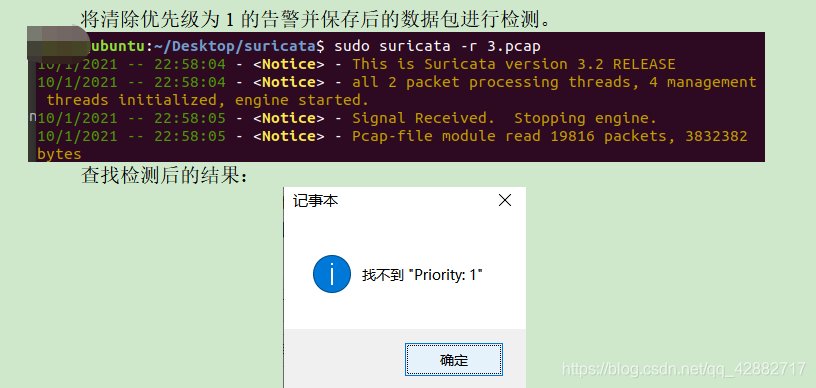
实战
这里就不放木马绕过检测的实战了,有兴趣的可以找我讨论,经常在线