1.抽象类和接口的异同
相同:都不能被实例化;都可以定义抽象方法,子类必须实现这些抽象方法
不同:
1.抽象类只能被单继承,接口可以多继承
2.抽象类里面可以声明成员变量,接口只能是public static final的静态常量
3.抽象类中可以包含普通方法,接口只能是public abstract修饰抽象方法
4.抽象类可以由构造方法,接口中不能有构造方法
抽象类:既想约束子类具有共同的行为(但不再乎其如何实现),又想拥有缺省的方法,又能拥有实例变量
接口:需要该类实现这些方法,但是不在乎其如何实现;实现该接口的类,可能无关联
2.泛型擦除
泛型擦除指的是泛型在编译期间,所有的泛型信息就被擦除,JVM 看到的只是 List,而由泛型附加的类型信息对 JVM 来说是不可见的。
通过反射可以无视泛型(也可以无视方法修饰符 public,private等)但是这样没有必要(写了泛型了,虽然从程序上这样是没问题的,但是逻辑上是错误的)
3.java异常体系
Throwable 是 Java 语言中所有错误或异常的超类。Throwable 包括Error和Exception,Exception里包括编译时异常和运行时异常,Error就是一些系统内部错误
Error是一个经常会被忘掉的类
4.ThreadLocal
ThreadLocal类:可以指定该线程自己的专属本地变量
一个线程上可以有多个ThreadLocal对象,所以其实ThreadLocal内部是有一个map在维护整个变量,这个 Map 不是直接使用的 HashMap ,而是 ThreadLocal 实现的一个叫做 ThreadLocalMap 的静态内部类。最终的变量是放在了当前线程的 ThreadLocalMap 中,并不是存在 ThreadLocal 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值
5.ThreadLocal内存泄漏的场景
(弱引用强引用是JVM的东西,详见https://www.cnblogs.com/gudi/p/6403953.html)
实际上 ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,⽽ value 是强引⽤。弱引用的特点是,如果这个对象持有弱引用,那么在下一次垃圾回收的时候必然会被清理掉。
所以如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候会被清理掉的,这样一来 ThreadLocalMap中使用这个 ThreadLocal 的 key 也会被清理掉。但是,value 是强引用,不会被清理,这样一来就会出现 key 为 null 的 value。 假如我们不做任何措施的话,value 永远⽆法被GC 回收,这个时候就可能会产⽣内存泄露。
ThreadLocalMap实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。如果说会出现内存泄漏,那只有在出现了 key 为 null 的记录后,没有手动调用 remove() 方法,并且之后也不再调用 get()、set()、remove() 方法的情况下。
因此使⽤完ThreadLocal ⽅法后,最好⼿动调⽤ remove() ⽅法。
6 static关键字和final关键字
static:
static可以修饰属性和方法,static修饰时的属性所有该类对象共用一份,**修改时,所有的类全部跟着一起修改,**随着类的加载而加载(只加载一次),先于对象的创建
static修饰方法就很常见了,不需要多解释了,在static方法中,只能调用静态的成员
final:
final关键字可以修饰变量、⽅法、类
final修饰变量:对于final对象,如果是基本数据类型,在初始化之后值不能变更,如果是引用类型的变量,在初始化之后不能再让其指向第二个对象
final修饰方法:将方法锁定,避免任何继承类重写该方法,private方法隐式的指定为final
final修饰类:则该类无法被继承,类中所有方法都被隐式的指定为final
7.序列化 反序列化 serialVersionUID
关于序列化的相关知识在IO流的笔记中
序列化:对象转二进制流
反序列化:二进制流转对象
如果一个实现了序列化接口的对象未声明serialVersionUID,那么会在内存中自动生成一份,如果该对象类进行了修改,那么自动生成的serialVersionUID会改变,导致之前序列化的对象,无法再反序列化,因为serialVersionUID不一样了。
ArrayList ,LinkedList
ArrayList底层是一个数组,默认初始大小为10,当数组容量不够时,会触发扩容机制(扩大到当前的1.5倍),需要将原来数组的数据复制到新的数组中;数组操作元素的时候会出现的问题,它都会出现,所以它适合随机查找和遍历,不适合插入和删除。
LinkedList底层是一个双向链表,适合数据的动态插入和删除;内部提供了 List 接口中没有定义的方法,用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
ArrayList和linkedList都是线程不安全的
那么如果需要线程安全的ArrayList和LinkedList怎么办?
1.使用Vector:底层使用了synchronized保证线程安全,效率较差
2.使用Collections.synchronizedList(List list)函数,通过传一个需要创建的List对象,生成一个线程安全的对象
3.CopyOnWriteArrayList,这是一个新的类,看了下源码的set和get方法,在使用这两个写方法的时候这个类会加锁,以保证线程安全,还有CopyOnWriteArraySet、CopyOnWriteHashMap也有相应实现
List遍历
1.for循环
for (int i=0;i<list.size();i++){
System.out.println(list.get(i));
}
2.Iterator
Iterator it = list.listIterator();
while (it.hasNext()){
System.out.println(it.next());
}
3.增强for循环
for (Object o: list) {
System.out.println(o);
}
java集合的fail-fast和fail-safe机制
(只有ArrayList,hashmap等会出现这种情况,像LinkedList没这种事)
快速失败机制:https://blog.csdn.net/zymx14/article/details/78394464
出现场景:在使用iterator遍历特定集合的时候错误的调用remove,add,clear等修改集合元素的方法,会出现ConcurrentModificationException异常
例:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
for (int i = 0 ; i < 10 ; i++ ) {
list.add(i + "");
}
Iterator<String> iterator = list.iterator();
int i = 0 ;
while(iterator.hasNext()) {
if (i == 3) {
list.remove(3);
}
System.out.println(iterator.next());
i ++;
}
}
看每个类的iterator源码的时候,在实现iterator的时候有一个变量expectedModCount,代表是遍历时期待的修改次数,一旦这个正在被遍历的类,发生了修改,比如add(),remove()等,外部List类的ModCount会发生改变,而内部的expectedModCount不会改变,而在iterator的next函数中,每次调用都会在开头检查expectedModCount和ModCount是否相等,如果不相等直接抛ConcurrentModificationException异常,所以这个就是fail-fast机制。
如何避免ConcurrentModificationException异常?
1.单线程情况下:使用构造器定义的remove方法
2.多线程情况下:
使用线程安全的类:CopyOnWriterArrayList,ConcurrentHashMap
fail-safe机制
在遍历CopyOnWriterArrayList,ConcurrentHashMap时,在遍历的时候如果有修改,这个修改会先复制原数组,然后对这个数组进行修改,最后将原数组引用指向新数组,因此即使有修改,遍历也是遍历完的原数组,修改对遍历不生效,这个机制就是fail-safe机制
HashMap详解:
参考;https://www.jianshu.com/p/9fe4cb316c05 这老哥写的也太长了……强
红黑树:平衡的二叉查找树(有平衡树的特点:节点高度差不大于1,;有查找树的特点:左节点<中节点<右节点)
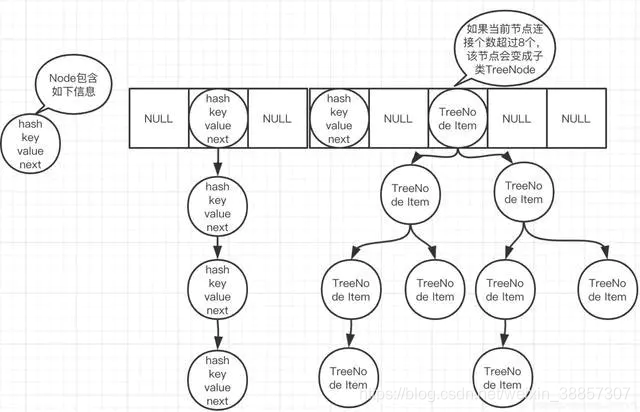
HashMap的组成部分:数组+链表+红黑树
图片出自参考文章,hashmap最基本的结构是node数组
也就是说对于hash冲突,hashmap是采用将哈希值相同的节点元素通过链表的形式保存下来,node
数组中保存一个元素以及下一个元素的地址,如果;链表节点数超过8个,会转化为红黑树结构保存
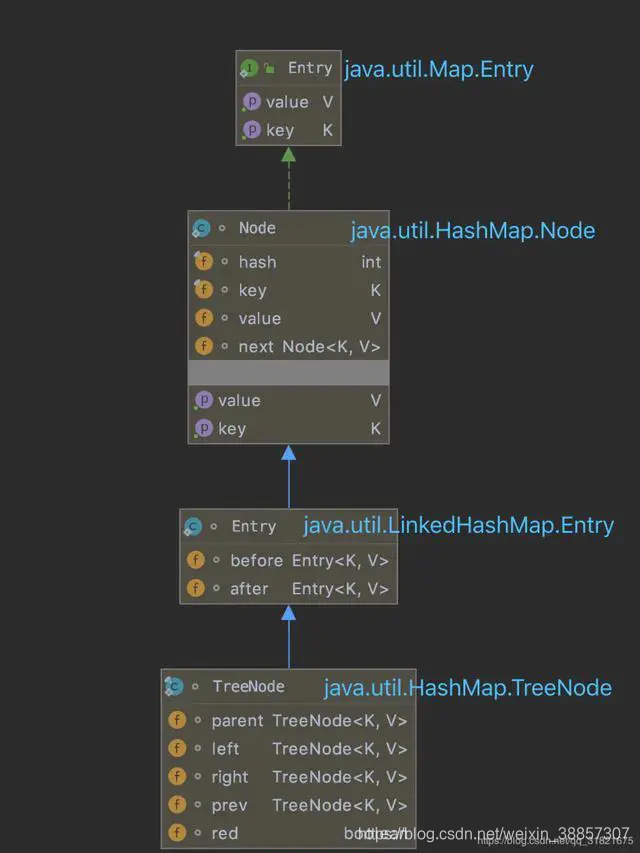
hashmap中的一些内部类的继承关系如下,图片出自参考文章
HashMap的一些重要特性:存取无序性(不是你先存了哪个,遍历的时候就会先出来哪个);KV均允许为NULL;懒汉式;还有好多红黑树相关特性……
重要参数:
静态参数:这些基本都是hashmap的设置,比如负载因子,默认容量等,这个尽量能不动就不动
动态参数:
1.transient Node<K,V>[] table 这个就是链表数组Node,该数组长度必定为2的倍数
2.transient Set<Map.Entry<K,V>> entrySet这个实际上算是对外暴露的参数?遍历的时候都是用它
3.size map KV个数
4.modcount 详见刚才的fail-fast
构造方法:
1.无参
2.给出初始容量大小
3.给出初始容量大小和负载因子
4.传入一个map,将这个map中的元素取出来,然后构建一个hashmap,把这些元素放进去。
hash值
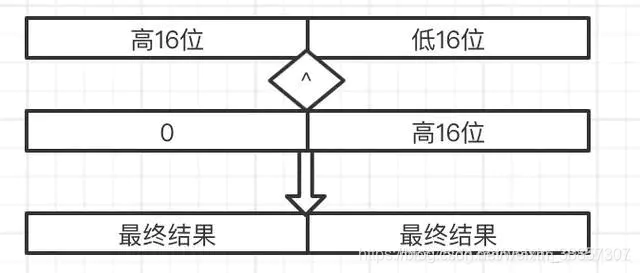
如何获取一个key所对应在hashmap中的hash值
1.首先获取key对应的hash值,2.进行扰动,以尽量实现均匀分布
扰动操作如下,图片出自参考文章
因此get方法的原理如下:
1.获得key的hash然后根据hash和key按照插入时候的思路去查找get
2.如果数组节点位置为null,则返回空
3.如果数组节点位置不为空,查看节点的key是否与需要的key相同
4.如果不同,数组有next参数,那么按照链表方式,向下查找,直到找到key为止
5.如果没有next参数,那么按照红黑树方式向下查找,直到找到key为止
put方法原理如下
1.对数据进行Hash值计算。
2.先查看当前node数组状态,如果未初始化,初始化
3.对key进行运算,判断当前位置情况
4.如果位置为null,则放置在这,如果key相同,替换value
5.如果当前位置为红黑树,则调用红黑树的加入结点方法
6.否则,就当做链表处理,加入链表尾部,并判断是否要转为红黑树
7.数组添加完之后modCount++,并判断整体是否需要扩容
resize方法原理如下
1.获取老table,如果老table不能在扩容了,那么调节阈值
2.如果可以扩容,则容器大小和阈值都增大
3.如果是带参数构造函数则需要将阈值复制给容器容量,否则认为该容器初始化时未传参,需初始化。
4.设置新容器
5.老table数据转移到新table中,如果node是null,是唯一,是链表,都好说,然后红黑树使用split处理
remove原理
查看table[i]是否存在,然后,找到数据,是在节点上,在链表中还是在红黑树上,然后移除即可
这后面可能会涉及一个红黑树变链表的操作
jdk7与jdk8hashmap区别:
1.jdk7是数组加链表,jdk8是数组+链表+红黑树
2.jdk7节点插入是头插法,8节点插入是尾插法