伪·BiliLocal播放器全弹幕发射教程
相关记录
一、前言
BiliLocal 播放器是一款可以播放弹幕的播放器。
这个教程指在表现出全弹幕发射的样子,但是不是真真意义上的全弹幕发射。
本身它也是有这个功能,现在好像有点失效了。所以,在这里,博主准备模拟一下所谓的全弹幕装填的效果。让我们开始吧。
二、软件回顾
-
在线加载弹幕

-
只有 1000 条,太少了

-
实际播放效果
多少还是有点单薄的,所以咱准备疯狂一把。

-
修改后的弹幕量

-
实际效果
弹幕量果然爆炸,确实有点全弹幕装填的意味了。(图片鬼畜的原因是,限制 5 M)

三、具体操作
-
先讲讲原理
实际上,原理很简单,因为有一个获取历史弹幕的接口,只要获取不同天数的弹幕池弹幕,最后拼接在一起就可以了。
接口如下所示:
https://api.bilibili.com/x/v2/dm/history?type=1&date=2020-08-25&oid=76113255
date 与 oid需要我们填写,一个是日期,另一个是 cid 号 -
关于 XML 文件
这个涉及到 DOM 操作,说白就是怎么快速的生成一个这样的文件结构。

-
具体代码实现思路可以这样
① 获取很多弹幕池弹幕
② 新建一个空 XML 文件
③ 把弹幕以 DOM 形式添加进 XML 文件中
④ 保存下来 -
也可以复制粘贴
都是文本,但是可能太累了
四、Python 代码
本人写的渣代码,功能是可以实现的。(去掉了一些不需要的功能,稍微精简一点)
#! Python3
# 调整 XML 弹幕文件
from xml.dom.minidom import parse
import xml.dom.minidom
import requests
from fake_useragent import UserAgent
import datetime
import time
class XMLDownloader:
def __init__(self, cid, cookie):
self.cid = cid
self.cookie = cookie
self.chatserver='chat.bilibili.com'
self.chatid=cid
self.mission='0'
self.maxlimit=''
self.state='0'
self.real_name='0'
self.source='e-r'
## print(self.chatserver, self.chatid, self.mission, self.maxlimit, self.state, self.real_name, self.source)
self.current_danmaku_url = "https://comment.bilibili.com/{}.xml"
self.history_danmaku_url = "https://api.bilibili.com/x/v2/dm/history?type=1&date={}&oid={}"
self.headers = {
'User-Agent': UserAgent(path='fake_useragent.json').random}
# print(self.headers)
def getCurrentDanmakuXML(self):
# 下载目前的弹幕池弹幕,并得到核心弹幕内容列表
data = requests.get(url=self.current_danmaku_url.format(self.cid),
headers=self.headers).content
with open("temp.xml", 'wb') as f:
f.write(data)
currentDanmakuList = self.getDanmakuList("temp.xml")
return currentDanmakuList
def getHistoryDanmakuXML(self, date):
# 下载历史的弹幕池弹幕,并得到核心弹幕内容列表
self.headers['Cookie'] = self.cookie
data = requests.get(url=self.history_danmaku_url.format(date, self.cid),
headers=self.headers).content
with open("temp.xml", 'wb') as f:
f.write(data)
historyDanmakuList = self.getDanmakuList("temp.xml")
return historyDanmakuList
def getDanmakuList(self, filename):
# 得到核心弹幕内容列表
DOMTree = xml.dom.minidom.parse(filename)
i = DOMTree.documentElement
ds = i.getElementsByTagName("d")
dDataList = []
for d in ds:
if d.hasAttribute('p'):
dAttribute = d.getAttribute('p')
dText = d.childNodes[0].data
dDataList.append([dAttribute, dText])
return dDataList
def getDateList(self, startDate, days):
# 得到日期列表,用于历史弹幕接口的拼接
dateList = []
start_datetime = datetime.datetime.strptime(startDate, "%Y-%m-%d")
for day in range(days):
delta = datetime.timedelta(days=day)
temp_datetime= start_datetime + delta
dateList.append(temp_datetime.strftime("%Y-%m-%d"))
return dateList
def extendDataList(self, dataList):
# 列表扩展,用于得到总弹幕池
extendList = []
for i in dataList:
extendList.extend(i)
return extendList
def save(self, dataList, filename='temp.xml'):
# 储存为 xml 文件
dom = xml.dom.minidom.Document()
i_node = dom.createElement('i')
dom.appendChild(i_node)
chatserver_node = dom.createElement('chatserver')
i_node.appendChild(chatserver_node)
chatserver_text = dom.createTextNode(self.chatserver)
chatserver_node.appendChild(chatserver_text)
chatid_node = dom.createElement('chatid')
i_node.appendChild(chatid_node)
chatid_text = dom.createTextNode(self.chatid)
chatid_node.appendChild(chatid_text)
mission_node = dom.createElement('mission')
i_node.appendChild(mission_node)
mission_text = dom.createTextNode(self.mission)
mission_node.appendChild(mission_text)
maxlimit_node = dom.createElement('maxlimit')
i_node.appendChild(maxlimit_node)
maxlimit_text = dom.createTextNode(str(len(dataList)))
maxlimit_node.appendChild(maxlimit_text)
state_node = dom.createElement('state')
i_node.appendChild(state_node)
state_text = dom.createTextNode(self.state)
state_node.appendChild(state_text)
real_name_node = dom.createElement('real_name')
i_node.appendChild(real_name_node)
real_name_text = dom.createTextNode(self.real_name)
real_name_node.appendChild(real_name_text)
source_node = dom.createElement('source')
i_node.appendChild(source_node)
source_text = dom.createTextNode(self.source)
source_node.appendChild(source_text)
for item in dataList:
d_node = dom.createElement('d')
i_node.appendChild(d_node)
d_node.setAttribute('p', item[0])
d_text = dom.createTextNode(item[1])
i_node.appendChild(d_text)
try:
with open(filename, 'w', encoding='utf-8') as f:
dom.writexml(f, indent='', addindent='\t', newl='\n', encoding='utf-8')
print('xml OK!')
except Exception as error:
print("error!: {}".format(error))
def download(self, startDate=None, days=0, isCurrent=True):
# 总函数入口
currentDanmakuList = None
if isCurrent:
currentDanmakuList = self.getCurrentDanmakuXML()
##print("data: {}".format(currentDanmakuList[0]))
if startDate == None:
startDate = datetime.datetime.now().strftime("%Y-%m-%d")
days = 0
dateList = self.getDateList(startDate, days)
danmakuLists = []
if not (currentDanmakuList == None):
danmakuLists.append(currentDanmakuList)
for date in dateList:
danmakuLists.append(self.getHistoryDanmakuXML(date))
time.sleep(0.5)
print("Danmaku: {}".format(len(danmakuLists)))
extendDanmakuList = self.extendDataList(danmakuLists)
print("弹幕池: {} 条".format(len(extendDanmakuList)))
self.save(extendDanmakuList)
if __name__ == '__main__':
# cid:视频的cid号
# cookie:用户的cookie值,以xml文件中为准
# startDate:起始日期 2019-02-14
# days:持续天数
cid = ''
cookie = ''
startDate = ''
days = 0
isCurrent = True # 是否以当前弹幕池为基准
xmlDownloader = XMLDownloader(cid, cookie)
xmlDownloader.download(startDate, days, isCurrent)
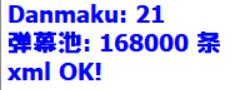
实际运行效果可以变得很夸张:
五、需要注意的地方
- 实际上虽然爬到很多弹幕,但是在播放器里就少了很多,这是为什么呢?
实际上,经过我的不断实验,可能的猜测是很多弹幕是重复的,所以直接覆盖掉了。因此,如果你要全弹幕形式的话,需要好好挑个时间和数量,或者好好编写自己的代码筛选,才能使得弹幕加载变得很多。 - 适当的时间指的是?
参照视频发布时间 - 数量的规定呢?
太多会卡,全装效果也是,影响观感。适用于弹幕比较薄的场景。
六、总结
写的也差不多,稍微总结一下。
这不是原来的全装弹幕功能,失效了已经。

但是,通过这样围魏救赵的方式,可以做到离线视频、离线弹幕、离线全装弹幕。有用?没用?谁知道呢。
那么,本篇博文到这就结束了,谢谢大家的支持!O(∩_∩)O~
点我回顶部 ☚
Fin.