10.1 使用w查看系统负载

1、使用 w 查看系统负载

21:08:54 是系统时间, up 5 days 启动时间 ,TTY 这边,如果是网络登录的话,就会显示成 pts/0 或 pts/1
load average : 0.00,0.01,0.05 。这三个数值的含义跟CPU有关系,表示的意义是,单位时间段内CPU活动进程数。当然这个值越大就说明你的服务器压力越大。一般情况下这个值只要不超过服务器的cpu数量就没有关系,如果服务器cpu数量为8,那么这个值若小于8,就说明当前服务器没有压力,否则就要关注一下了。这些数值为0也不好,说明服务器空闲着,太浪费了。那么这些数值什么时候才是最理想的状态?这时候就要查看 CPU 数量,这边的CPU数量指的是逻辑CPU,而不是物理CPU,使用命令 cat /proc/cpuinfo见下图:
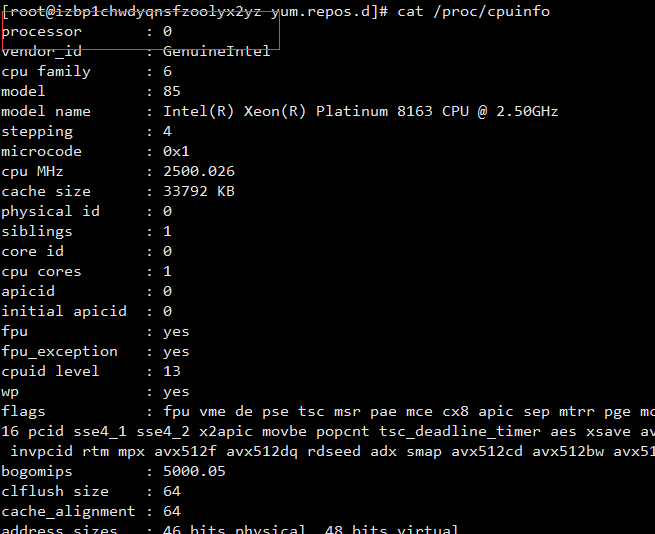
0 表示只有一个逻辑CPU。load average 这边的第一数值为 1 的时候,最为理想,既没有空着,也没有太多负载。其他两个数值同理,一般最为关注的是第一个数值。只要数值不超过CPU的数量,就没有太大问题。‘/proc/cpuinfo’ 这个文件记录了cpu的详细信息。目前市面上的服务器通常都是2颗4核cpu,在 Linux 看来,它就是8个cpu。查看这个文件时则会显示8段类似的信息,而最后一段信息中processor : 后面跟的是 ‘7’ 所以查看当前系统有几个cpu,我们可以使用这个命令: grep -c 'processor' /proc/cpuinfo ,而如何看几颗物理cpu呢,需要查看关键字 “physical id”, 由于我的虚拟机只有一个cpu所以并未显示关于 “physical id” 的信息。
还有一个命令 uptime ,见下图,

结果跟 w 命令的第一行一摸一样,所以一般都使用 w 命令来查看
10.2 vmstat 命令
上面讲的 w 查看的是系统整体上的负载,通过看这些数值可以知道当前系统有没有压力,但是具体是哪里(CPU, 内存,磁盘等)有压力就无法判断了。这时候就需要用到 vmstat 命令,可以知道具体是哪里有压力。vmstat命令打印的结果共分为6部分:procs, memory, swap, io, system, cpu,见下图,

1)procs 显示进程相关信息
r :表示运行和等待cpu时间片的进程数,如果长期大于服务器cpu的个数,则说明cpu不够用了;
b :表示等待资源的进程数,比如等待I/O, 内存等,这列的值如果长时间大于1,则需要关注一下了;
2)memory 内存相关信息
swpd :表示切换到交换分区中的内存数量 ;
free :当前空闲的内存数量;
buff :缓冲大小,(即将写入磁盘的);
cache :缓存大小,(从磁盘中读取的);
3)swap 内存交换情况
si :由交换区写入到内存的数据量;
so :由内存写入到交换区的数据量;
4)io 磁盘使用情况
bi :从块设备读取数据的量(读磁盘);
bo: 从块设备写入数据的量(写磁盘);
5)system 显示采集间隔内发生的中断次数
in :表示在某一时间间隔中观测到的每秒设备中断数;
cs :表示每秒产生的上下文切换次数;
6)CPU 显示cpu的使用状态
us :显示了用户下所花费 cpu 时间的百分比;
sy :显示系统花费cpu时间百分比;
id :表示cpu处于空闲状态的时间百分比;
wa :表示I/O等待所占用cpu时间百分比;
st :表示被偷走的cpu所占百分比(一般都为0,不用关注);
以上所介绍的各个参数中,我们经常会关注r列,b列,和wa列,三列代表的含义在上边说得已经很清楚。IO部分的bi以及bo也是要经常参考的对象。如果磁盘io压力很大时,这两列的数值会比较高。另外当si, so两列的数值比较高,并且在不断变化时,说明内存不够了,内存中的数据频繁交换到交换分区中,这往往对系统性能影响极大。
我们使用 vmstat 查看系统状态的时候,通常都是使用下图的形式来看的:

mstat 1 显示的是,每隔1秒打印一次状态,一直打印,直到我们按 Ctrl + c 结束。还有另外一种方式,见下图

vmstat 1 5 表示每隔一秒钟打印一次状态,共打印5次,然后命令自动结束。这边显示的结果 里面,我们一般只需关注这几列:r、b、swpd、si、so、bi、bo、us、wa。r(run)表示有多少个进程处于运行状态。b(block)表示进程被CPU以外的资源(比如硬盘、网络)给阻断了,处于一个等待的状态。swpd 交换分区,当内存不够的时候,系统会把内存里的一部分数据释放一些出来,临时放到 swpd 空间里面,当这一列的数据没有变化的时候,说明没有什么问题,如果这一列的数据一直在跳动的话,就说明内存不够。si 和 so 这两列数据和 swpd 是有关系的,他们的单位都是KB,si 是由swpd写入到内存的数据量,so 是由内存写入到swpd的数据量,i 是in,o 是out。bi 和 bo 这两列数据和磁盘是有关系的,bi 是从块设备读取数据的量(读磁盘),bo 是从块设备写入数据的量(写磁盘),这两个数据很大的话,说明磁盘在频繁的读和写。bi 和 bo 的数据很大,必然造成 b 列的数据增加。us 表示用户级别的,显示了用户下所花费 cpu 时间的百分比,这个数据是不会超过100的,如果这个数字长时间大于 50 ,也是说明资源不够。us + sy(系统花费CPU百分比) + id(空闲百分比) = 100 。wa(wait 等待)与 b 类似,表示等待 CPU 的百分比,即由多少个进程在等待CPU,如果这个数很大,说明CPU不够用。
10.3 top命令
查看进程使用资源情况。这个命令用于动态监控进程所占系统资源,每隔3秒变一次。它的特点是把占用系统资源(CPU,内存,磁盘IO等)最高的进程放到最前面。top命令打印出了很多信息,包括系统负载(loadaverage)、进程数(Tasks)、cpu使用情况、内存使用情况以及交换分区使用情况。其实上面这些内容可以通过其他命令来查看,所以用top重点查看的还是下面的进程使用系统资源详细状况。这部分东西反映的东西还是比较多的,不过需要你关注的也就是几项:%CPU, %MEM, COMMAND 。RES 这一项为进程所占内存大小,而 %MEM 为使用内存百分比。在 top 状态下,按 “shift + m”, 可以按照内存使用大小排序。按数字 ‘1’ 可以列出各颗cpu的使用状态。
输入 top ,回车,见下图,

默认是按CPU百分比(%CPU)排序,%CPU数值大的排在前面。%MEM为使用内存百分比,RES是物理内存大小,单位是K。假如我现在想让排序按%MEM来排序,要怎么操作呢?按下shift + m ,也就是大写的M,见下图,
现在就是按%MEN的大小来排序,排在第一位的是system。现在想要换回默认的%CPU排序,直接按下 shift+ p,即大写的 P .
还有一个选项,数字 1 ,按数字 ‘1’ 可以列出各颗cpu的使用状态,见下图,

%CPU0是单核,所以只有一行。再按一次 1 ,就恢复到默认状态,默认情况下查看的是平均值。
按字母 q ,就可以退出 top 查看的状态。
还有一种用法是 top -c,输入 top -c ,回车,见下图,
我们可以看到具体的命令的进程,看到的是全部的路径名称。单纯使用命令 top 的 话,只能查看最后面进程的名字。
还有一种用法,输入命令 top -bn1 ,回车,见下图,
上图把所有的进程,全部一次性列出,呈静态显示。此命令适合在写shell脚本的时候应用。
这边想要终止一个进程,使用命令 kill+PID号,回车,即可。
10.4 sar命令
sar 命令很强大,它可以监控系统所有资源状态,比如平均负载、网卡流量、磁盘状态、内存使用等等。它不同于其他系统状态监控工具的地方在于,它可以打印历史信息,可以显示当天从零点开始到当前时刻的系统状态信息。如果你系统没有安装这个命令,请使用 yum install -y sysstat 命令安装。初次使用sar命令会报错,那是因为sar工具还没有生成相应的数据库文件(时时监控就不会了,因为不用去查询那个库文件)。它的数据库文件在 “/var/log/sa/” 目录下,默认保存一个月。因为这个命令太过复杂,所以这边只介绍几个。
安装sar : yum install -y sysstat
刚刚安装了 sar 命令,所有执行命令 ls /var/log/sa ,没有结果,需要等十分钟才会生成文件,因为每隔十分钟会生成一个文件。所以需要给 sar 命令加上具体的选项和参数,见下图,

1 表示每隔 1秒,10 表示显示10次.第1列是时间,第2列是网卡的名字(IFACE)表示设备名称,第3列 rxpck/s 表示每秒进入收取的包的数量,第4列 txpck/s 表示每秒发送出去的包的数量,第5列 rxkb/s 表示每秒收取的数据量(单位Byte),第6列 txkb/s表示每秒发送的数据量。后面3列不需要关注,始终都是0.00。如果有一天你所管理的服务器丢包非常严重,那么你就应该看一看这个网卡流量是否异常了,如果rxpck/s 那一列的数值大于4000,或者rxkb/s那列大于5,000,000则很有可能是被攻击了,正常的服务器网卡流量不会高于这么多,除非是你自己在拷贝数据。
接着来查看 sar 命令,见下图,
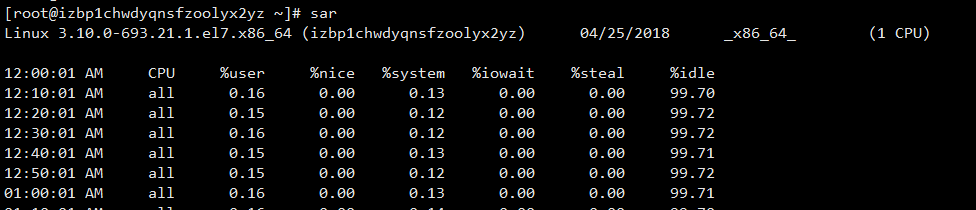
然后查看 ls /var/log/sa ,就有出现了文件 sa25,这个 sa 文件后面是以当天日期命名的,另外也可以查看某一天的网卡流量历史,使用-f选项,后面跟文件名
sar -n DEV -f /./var/log/sa/sa24
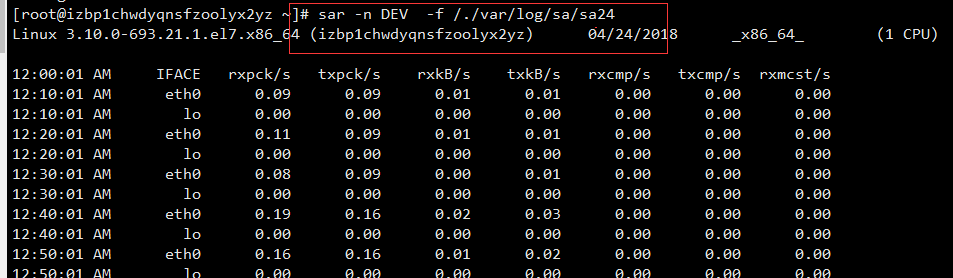
查看系统负载
sar -q 1 10

查看系统磁盘
sar -b
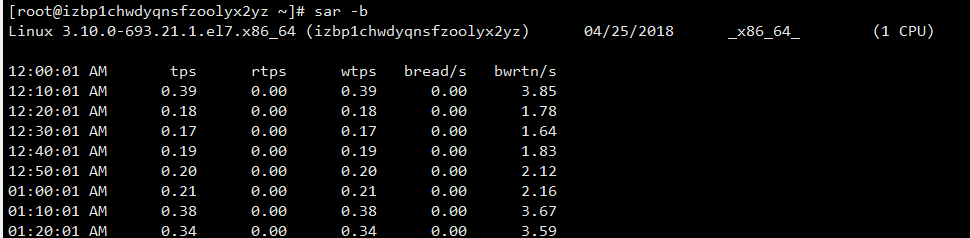
查看磁盘读写
sar -b 1 5

10.5 nload命令
监控网卡流量,这个命令默认是没有安装的,安装 nload 之前,需要先安装 epel-release ,安装完毕之后,接着往下操作,直接输入命令 nload ,回车,进入下图,
yum install epel-release
yum install nload

上图显示的信息是动态的,这只是其中一个网卡 ens33 ,按向右的方向键 → ,即可查看另一个网卡 lo 的信息,见下图,

按向左的方向键 ← ,又可以回到上一个网卡 ens33 ,可以来回切换。按字母 q 就可以退出这个界面
总结:
w 查看系统负载
date 查看当前的日期和时间
vmstat n 每隔n秒打印一次状态
vmstat n m 每隔n秒打印一次状态,一共打印m次
top 查看进程使用情况
大写的M %MEN内存排序
大写的P %CPU排序。
数字 1 查看指定每个CPU的使用状态
字母 q 退出 top 查看状态
top -c 查看具体的命令的进程
top -bn1 静态的显示全部进程,适合在写shell脚本的时候应用
sar -n DEV 查看网卡流量历史的
sar -q 查看系统负载
sar -b 查看系统磁盘
nload 监控网卡流量