[标题]
《Macro Discourse Relation Recognition via Discourse Argument Pair Graph》
[代码地址]
无
[知识储备]
目录
一、背景与概览
1.1 相关研究
无
1.2 贡献点
- 首次使用gnn于中文篇章关系识别
- 性能好
1.3 相关工作
无
二、模型
2.0 概括
概括描述建图和模型。
- argument-word: the keyword information TF-IDF,先验的注意力信息
- word-word: the global information PMI,句子之间的主题连贯性
巴拉巴拉。
2.1 建图
2.1.0 节点表示
在整个语料上建图,图中包含所有的argument节点和word节点。
词向量使用word2vec,可以缓解冷开始问题,也带来更加精确的单词语义信息。
argument使用词向量的平均。
2.1.1 连边
单词-单词:使用PMI指标,正的PMI值代表了单词之间较高的语义联系。

单词-句子:TF是单词在句子中出现的频率,IDF是对数归一化后反向的文档的频率(? IDF is the
frequency of the inverse document after log normalization)。
自环:不仅学习新的,也能保留旧的。
2.1.2 图的构建

2.2 模型
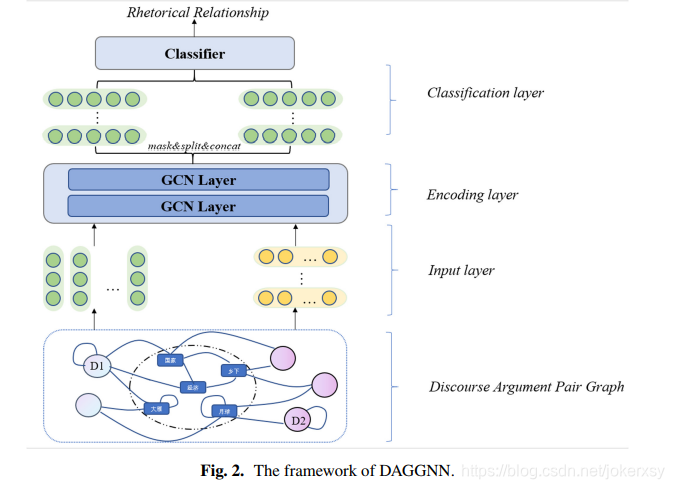
2.0 输入层
A and H 0 H^0 H0
2.1 编码层
经过第一层卷积网络,句子聚合了与它相连的单词;单词聚合了与它相连的单词。
经过第二层卷积网络,句子聚合了由“与它相连的单词”所带来的全局语义信息。
2.2 分类层
原来一个argument是一个段落,有多个句子,先各自concat得到 H a r g 1 H_{arg1} Harg1和 H a r g 2 H_{arg2} Harg2,再concat得到 H H H,再进行分类。
交叉熵:

三、实验与评估
基准模型:
- LSTM
- MSRM:利用了全局信息,但是忽略了句子中重要单词的不一致性。
- STGSN:序列模型不能很好的捕捉长文本的句内依赖;对于长文本attention也不好使;忽略了全局信息。
四、消融实验
去除 w-w边:不用PMI—>1?
去除 w-o边:不用TFIDF—>每一个argument对于它的每一个单词的权重=1/length
五、结论与个人总结
得到的句子向量表示可能迁移到其它任务
未来的工作是如何更好地建模