最近几年,“二手经济”逐渐火热,二手车市场也在快速扩大。
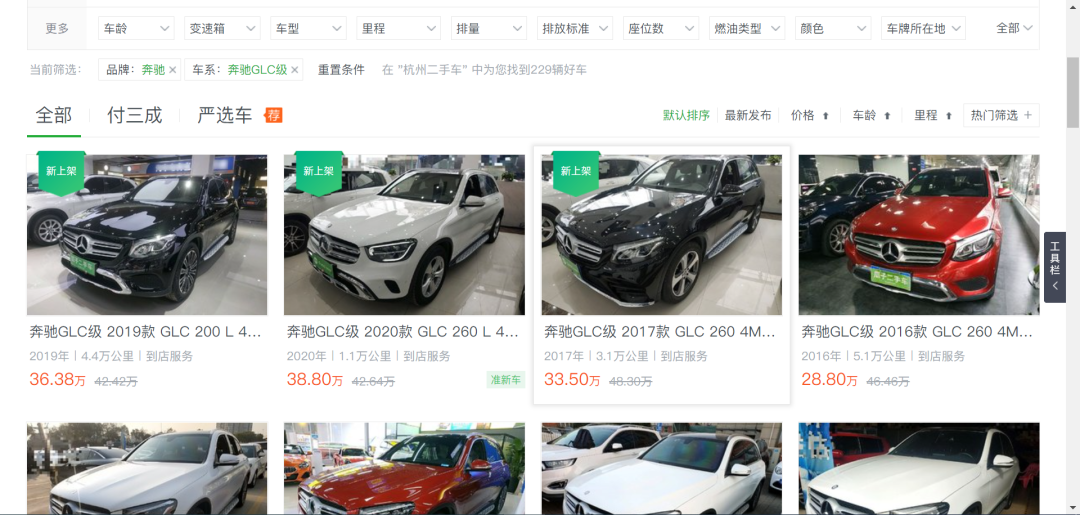
相同的车型,二手车比新车要实惠许多,比如下图中的奔驰GLC级,二手车能比新车便宜5-20万不等。因此有越来越多的人在购置车辆时将二手车纳入了考量。
但众所周知,二手市场的水也比较深,一不小心就容易缴“智商税”,所以在购买二手车前,对市场有一定的了解是必不可少的。
今天我给大家带来了一个某二手车网站的实战项目,用Python来分析二手车市场行情。

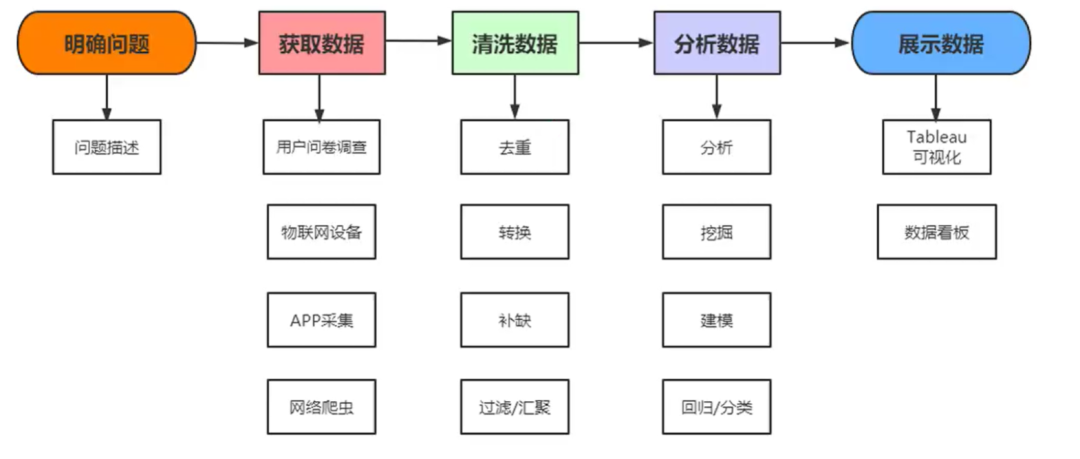
一、明确需求
1、爬取某二手车网站奔驰GLC级轿车的信息(标题、购车年份、里程数、价格)
2、利用年限和行驶里程,分析二手车保价率信息
二、爬取数据
在动手爬取数据前,我们先确定要用的工具,也就是库。目前用Python写爬虫主要有以下几个做法:
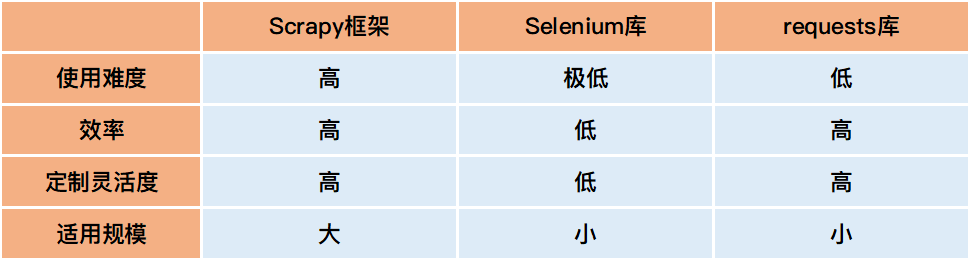
根据需求选好工具后,就可以开始爬取数据了。
首先,爬虫会根据我们的指令下载网页的数据,接着,利用xpath表达式从网页数据中提取出我们需要的内容。也就是每辆二手车的标题、年份、里程数、价格等信息。(记得根据页面的二手车信息数量写一个循环哦!)

三、数据清洗
什么是数据清洗?数据清洗是一个对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
就像我们这个例子,爬取的title里存在空格,副标题里存在“|”,我们需要将不同的数据分割,同时删除年份里的“年”字、里程数后的“万公里”这些字眼。只有纯粹的数据计算机才能计算。
最后,利用Pandas库输出为csv文件。

这样的数据是不是赏心悦目多了?
四、数据可视化
得到了csv格式的规范数据后,我们就可以通过直观的方式对数据进行分析,从中发现数据的趋势、特征。

如图,左图的点阵图可以很明显地看到,购买年份越早的车,价格会聚集在更低的区间;而右图我们可以看到,里程数与价格呈负相关。
五、总结流程