前言
爬虫是一种从网站上抓取大量数据的自动化方法。即使是复制和粘贴你喜欢的网站上的引用或行,也是一种web抓取的形式。大多数网站不允许你保存他们网站上的数据供你使用。因此,唯一的选择是手动复制数据,这将消耗大量时间,甚至可能需要几天才能完成。
网站上的数据大多是非结构化的。Web抓取有助于将这些非结构化数据,并将其以自定义和结构化的形式存储到本地或数据库中。如果您是为了学习的目的而抓取web页面,那么您不太可能会遇到任何问题,在不违反服务条款的情况下,自己进行一些web抓取来增强您的技能是一个很好的实践。
爬虫步骤
为什么使用Python进行Web抓取?
Python速度快得令人难以置信,而且更容易进行web抓取。由于太容易编码,您可以使用简单的小代码来执行大型任务。
如何进行Web抓取?
我们需要运行web抓取的代码,以便将请求发送到我们想要抓取的网站的URL。服务器发送数据并允许我们读取HTML或XML页面作为响应。代码解析HTML或XML页面,查找数据并提取它们。
下面是使用Python使用Web抓取提取数据的步骤
- 寻找您想要抓取的URL
- 分析网站
- 找到要提取的数据
- 编写代码
- 运行代码并从网站中提取数据
- 将所需格式的数据存储在计算机中
用于Web抓取的库
- Requests
- Beautiful Soup
- Pandas
- Tqdm
Requests是一个允许使用Python发送HTTP请求的模块。HTTP请求用于返回一个包含所有响应数据(如编码、状态、内容等)的响应对象
BeautifulSoup是一个用于从HTML和XML文件中提取数据的Python库。这适用于您喜欢的解析器,以便提供导航、搜索和修改解析树的惯用方法。它是专门为快速和高可靠的数据提取而设计的。
pandas是一个开源库,它允许我们在Python web开发中执行数据操作。它构建在Numpy包上,其关键数据结构称为DataFrame。DataFrames允许我们在观察数据行和变量列中存储和操作表格数据。
Tqdm是另一个python库,它可以迅速地使您的循环显示一个智能进度计—您所要做的就是用Tqdm(iterable)包装任何可迭代的。
演示:抓取一个网站
Step 1. 寻找您想要抓取的URL
为了演示,我们将抓取网页来提取手机的详细信息。我使用了一个示例(www.example.com)来展示这个过程。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:721195303
Stpe 2. 分析网站
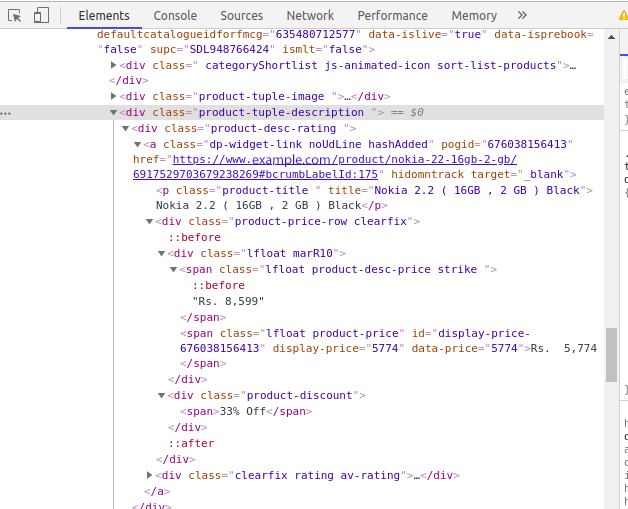
数据通常嵌套在标记中。分析和检查我们想要获取的数据被标记在其下的页面是嵌套的。要查看页面,只需右键单击元素,然后单击“inspect”。一个小的检查元件盒将被打开。您可以看到站点背后的原始代码。现在你可以找到你想要刮的细节标签了。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则特定产品区域的代码将在console选项卡中突出显示。
我们应该做的第一件事是回顾和理解HTML的结构,因为从网站上获取数据是非常重要的。网站页面上会有很多代码,我们需要包含我们数据的代码。学习HTML的基础知识将有助于熟悉HTML标记。
Step 3.找到要提取的数据
我们将提取手机数据,如产品名称、实际价格、折扣价格等。您可以提取任何类型的数据。为此,我们必须找到包含我们的数据的标记。
通过检查元素的区域来打开控制台。点击左上角的箭头,然后点击产品。您现在将能够看到我们点击的产品的特定代码。
Step 4. 编写代码
现在我们必须找出数据和链接的位置。让我们开始代码编写。
创建一个名为scrap.py的文件,并在您选择的任何编辑器中打开它。我们将使用pip安装上面提到的四个Python库。
第一个和主要的过程是访问站点数据。我们已经设置了该网站的URL,并访问了该网站。
url = 'https://www.example.com/products/mobiles-mobile-phones?sort=plrty'headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)Output: <Response [200]>
如果你看到上面的结果,那么你已经成功访问了这个网站。
Step 5. 运行代码并从网站中提取数据
现在,我们将使用Beautifulsoup解析HTML。
soup = BeautifulSoup(result.content, 'html.parser')如果我们打印soup,然后我们将能够看到整个网站页面的HTML内容。我们现在要做的就是过滤包含数据的部分。因此,我们将从soup中提取section标记。
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)结果如下:
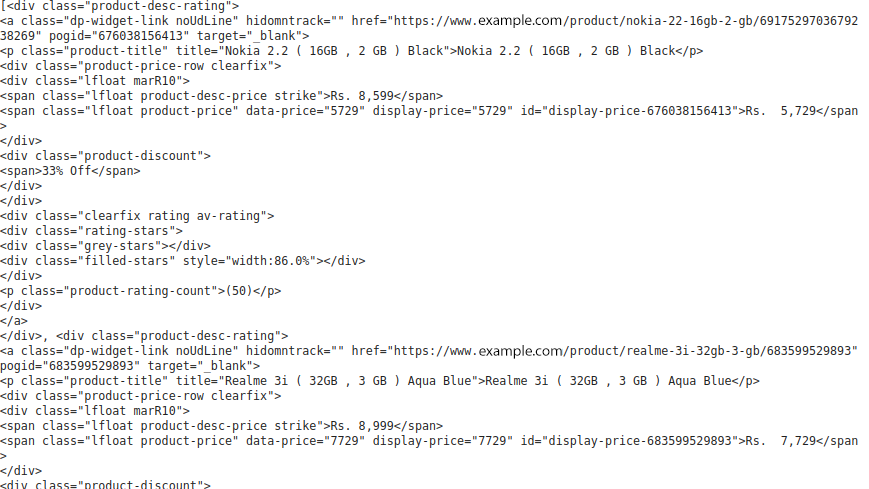
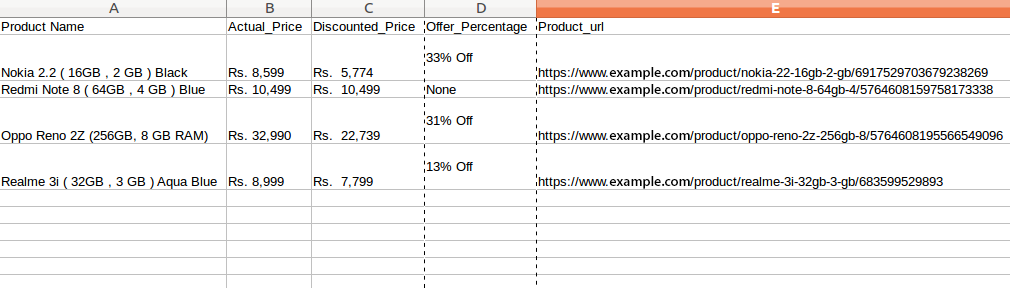
现在,我们可以在div的“product-desc-rating”类中提取移动电话的详细信息。我已经为移动电话的每个列细节创建了一个列表,并使用for循环将其附加到该列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []产品名称出现在HTML中的p标记(段落标记)之下,而product_url则出现在锚标记之下。
HTML锚标记定义了一个超链接,将一个页面链接到另一个页面。它可以创建到另一个web页面以及文件、位置或任何URL的超链接。“href”属性是HTML标记最重要的属性。以及指向目标页面或URL的链接。
然后我们将提取实际价格和折扣价格,它们都出现在span标签中。标签用于对内联元素进行分组。并且标签本身不提供任何视觉变化。最后,我们将从div标签中提取报价百分比。div标记是块级标记。它是一个通用的容器标签。它用于HTML的各种标记组,以便可以创建节并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)Step 6. 以所需的格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储到文件或数据库中。您可以按照所需的格式存储数据。这取决于你的要求。在这里,我们将以CSV(逗号分隔值)格式存储提取的数据。
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')