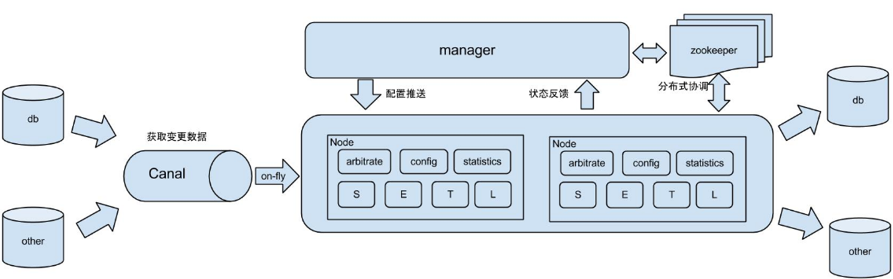
2 Canal
2.1 canal概念
数据采集:canal(阿里巴巴的)
什么是canal?应用场景:
-
通过canal同步两个数据库,同步数据。
-
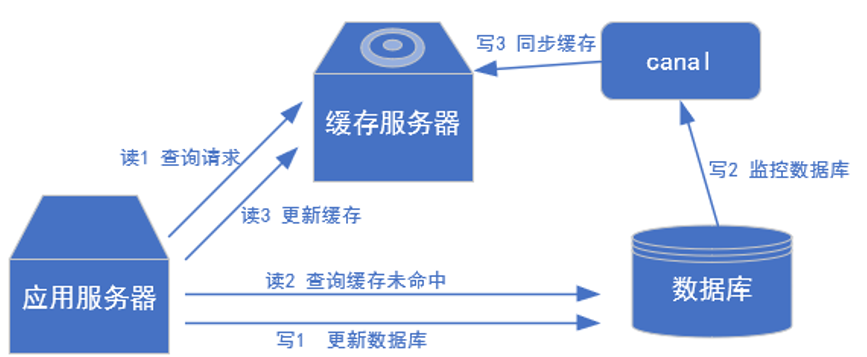
更新缓存,缓存服务器(canal监控数据库、同步缓存)
-
抓取业务表的新增变化数据,用于制作实时统计。(我们用的就是这种场景)
2.2 canal工作原理
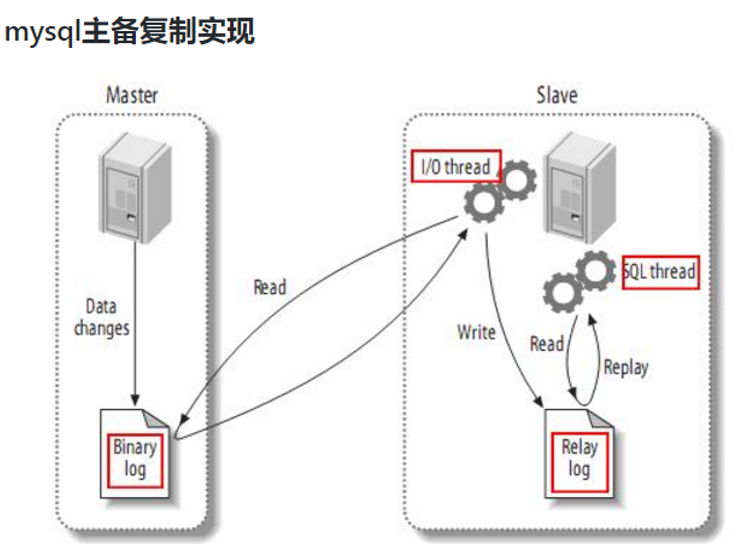
①MySQL主从复制过程:
-
Master主库记录改变,写到二进制(binary log)中
-
Slave从库向mysql master发送dump协议,将master主库的binary log events 拷贝到它的中继日志(relay log)
-
Slave从库读取并重做中级日志中的事件,将改变的数据同步到自己的数据库
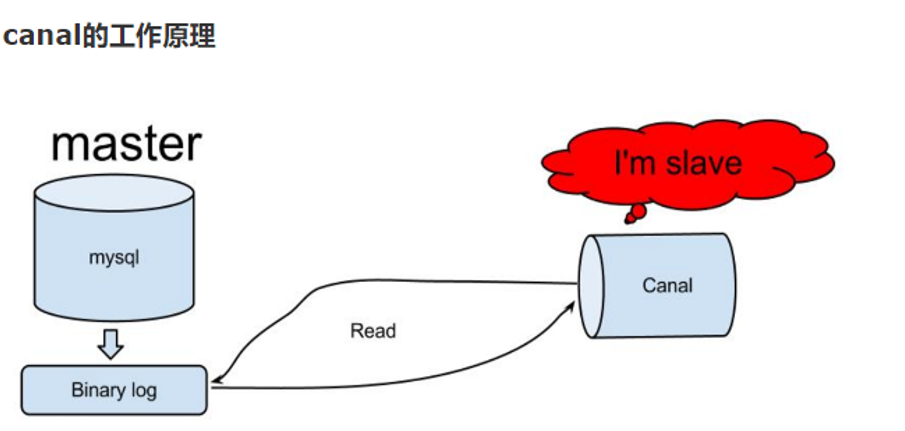
②canal工作原理:
就是把自己伪装成slave,假装从masyer复制数据
2.3 MySQL中的binlog
什么是binlog?
记录了所有的DDL和DML语句(处理查询语句),以事件形式记录,MySQL的二进制日志是事务安全型的。
默认是不开启的,会有1%的性能损耗。两个使用场景
- 一是数据恢复,通过mysqlbinlog工具恢复数据。
- 二是MySQL主从,master端开启binlog,slaves同步数据。(我们用这个)
二进制文件有两类文件:二进制日志索引文件(后缀为.index),记录所有的二进制文件,二进制日志文件(后缀为.00000*)记录数据库的DDL和DML(除查询语句)的事件
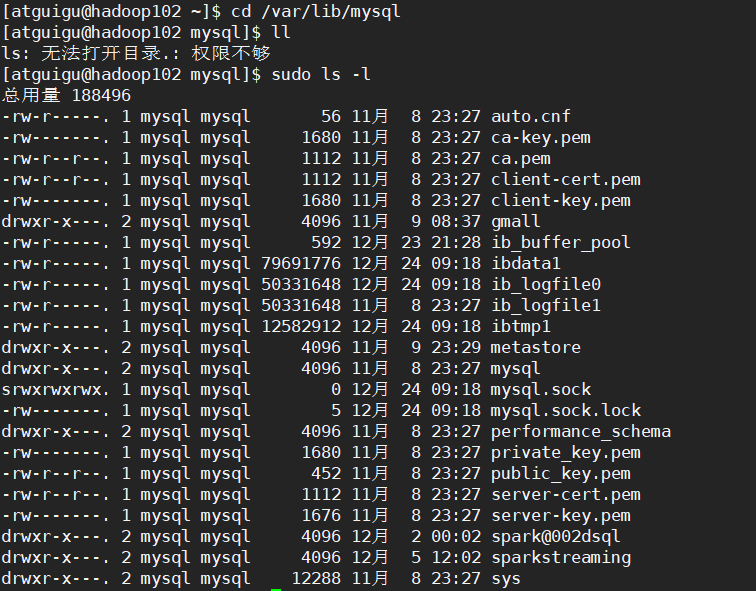
mysql数据存在哪呢?
/var/lib/mysql
mysql配置文件
在mysql的配置文件下,修改配置:开启binlog
log-bin=mysql-bin
其中mysql-bin是binlog日志的前缀。以后生成的日志文件就是mysql-bin.122334
每次mysql重启或者达到单个文件大小阈值时,会新生成一个文件,按顺序编号
2.4 binlog的分类设置:
配置文件中有三个选项:binlog_format=statement|mixed|row
statement:语句级,会记录主机每次执行语句,
在有些场景会有问题:update time < now()就有可能造成数据不一致
row:行级,binlog会记录每次操作后每行记录的变化。(用这种!)
主机上执行语句,哪一行改变了,那就记录每行的变化。
优点是:保持数据的绝对一致性,因为不管什么操作,只记录执行后的数据变化效果。
缺点是:占用较大空间,update改变了一百万行,那就要存100万
mixed:statement升级版,
优点是:节省空间,同时兼顾了一定的一致性。
缺点是:在有些极个别情况下还是会造成数据不一致问题。
2.5 MySQL数据准备
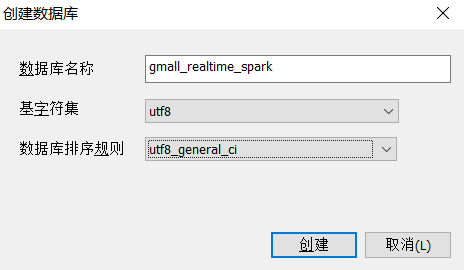
步骤1:创建数据库
步骤2:导入建表数据
2.6 开启binlog
步骤1:修改/etc/my.cnf文件
[atguigu@hadoop102 mysql]$ sudo vim /etc/my.cnf
这个文件在哪?怎么查到呢?
locate my.enflinux在:/etc/my.cnf
windows在:\my.ini
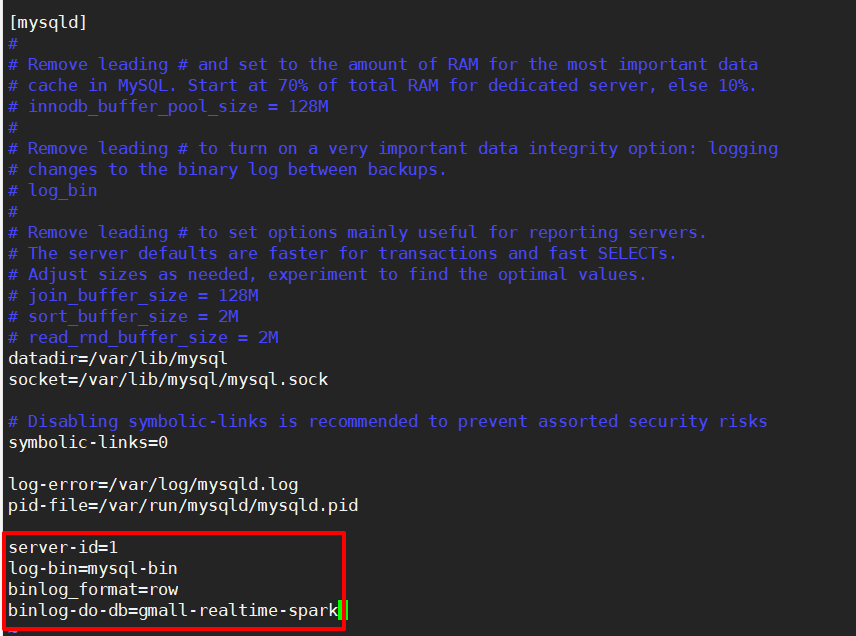
步骤2:修改内容
- server-id=1,集群的id
- log-bin=mysql-bin,生成的binlog文件的前缀
- binlog_format=row,binlog的配置方式
- binlog-do-db=gmall-realtime-spark,binlog用来监控哪一个数据库的变化。
这里有一个错误!导致第一次kafka消费不到数据!binlog-do-db=监控的数据库名!和我的数据库名不匹配!
步骤3:重启mysql服务
[atguigu@hadoop102 mysql]$ sudo systemctl restart mysqld
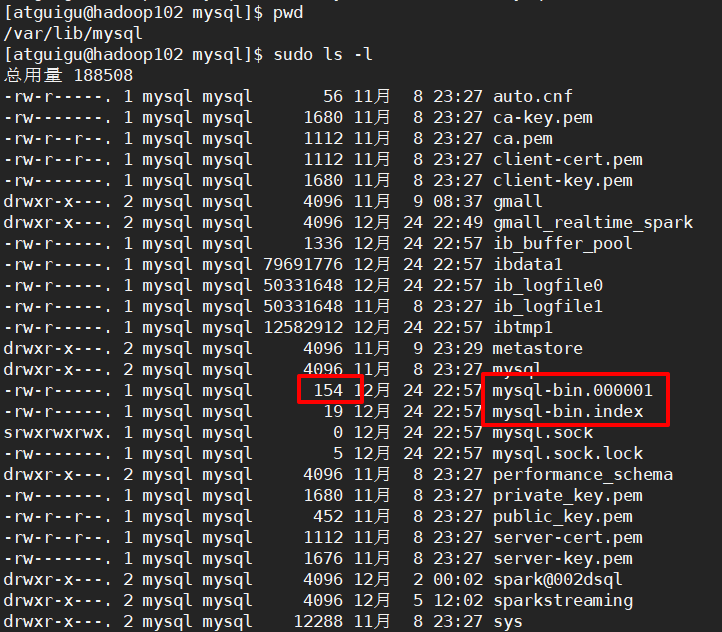
步骤4:到/val/lib/mysql目录下查看mysql-bin的初始文件:
mysql-bin.000080默认154字节
2.7 模拟生成数据
步骤1:上传业务数据生成的配置文件和jar包到/opt/modeul/applog-db
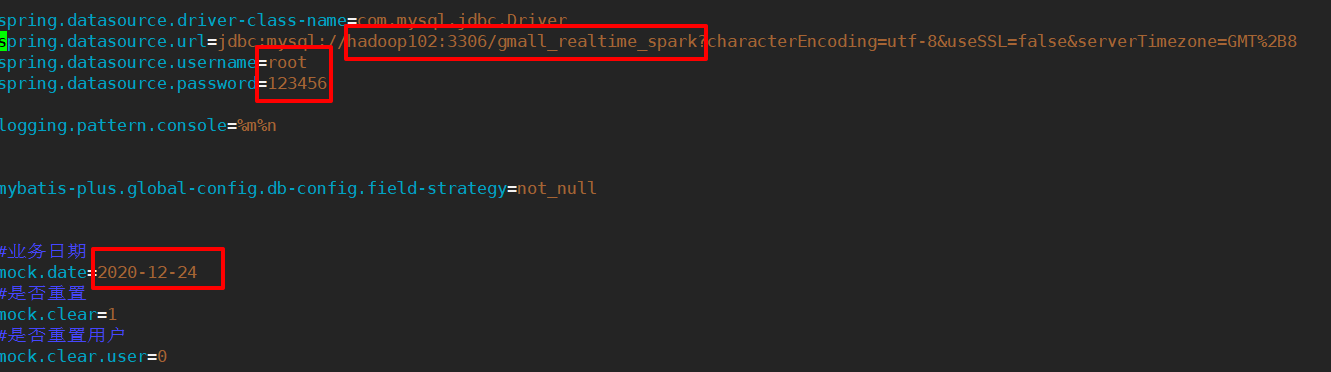
步骤2:修改application.properties配置文件
[atguigu@hadoop102 applog-db]$ vim application.properties
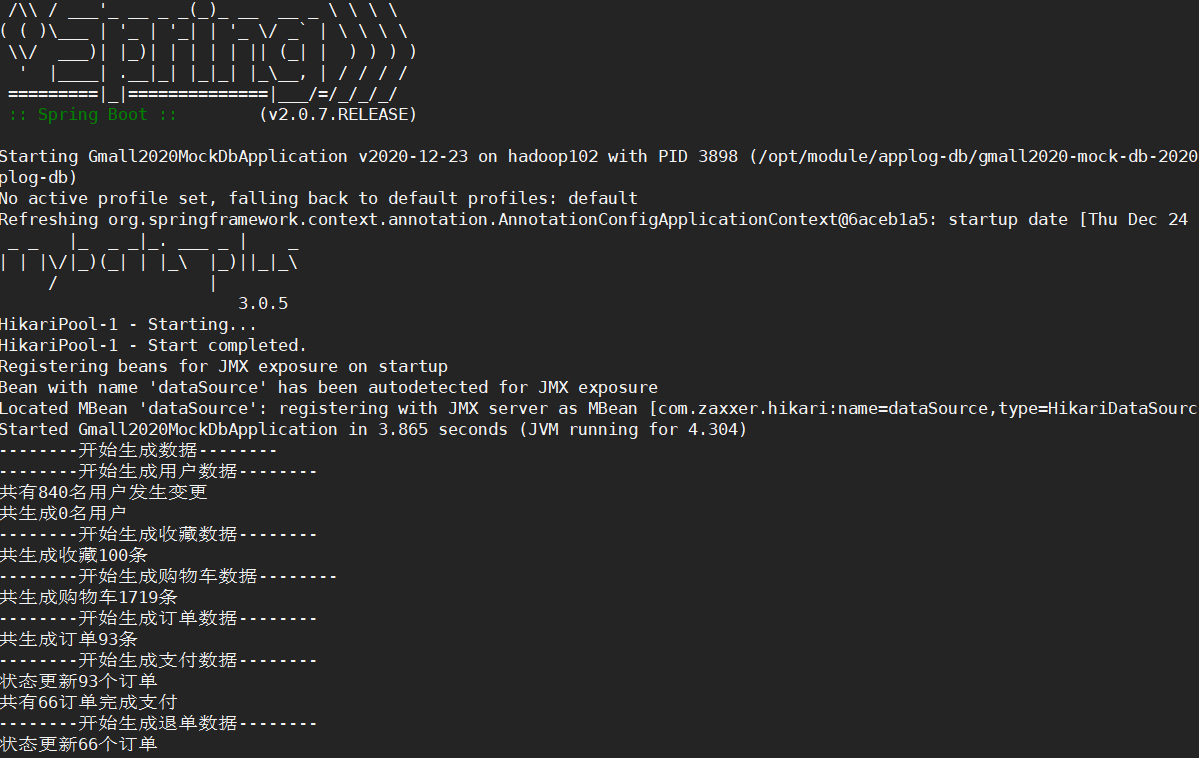
步骤3:执行生成数据的jar包
[atguigu@hadoop102 applog-db]$ java -jar gmall2020-mock-db-2020-12-23.jar
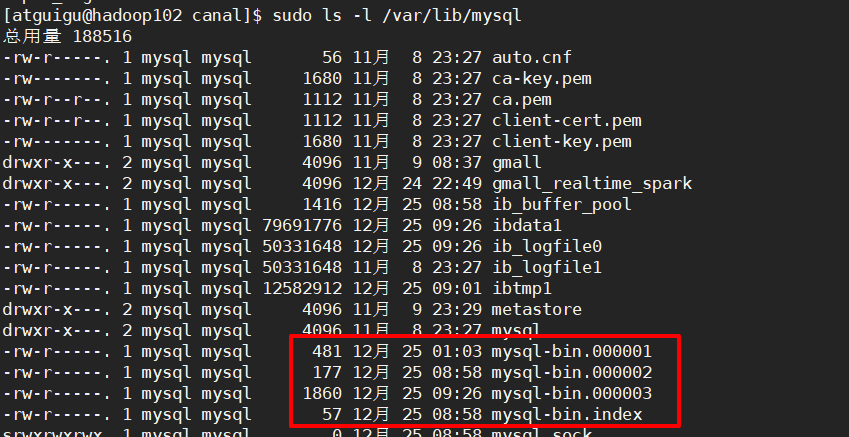
步骤4:查看mysql中的数据和/var/lib/mysql/中binlog文件的大小
2.8 给canal赋权限
步骤1:在MySQL中执行:
set global validate_password_length=4;
set global validate_password_policy=0;
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT:授予查询、主从复制、作为客户端;
ON * .*: 给当前库的所有表,
TO ‘canal’@’%’:哪个用户呢,‘canal’用户
IDENTIFIED BY ‘canal’ : 密码是‘canal’
3 canal架构及安装
3.1 canal单机版安装配置
https://github.com/alibaba/canal/releases
步骤1:canal解压后是散的,提前创建canal文件夹
[atguigu@hadoop102 applog-db]$ mkdir /opt/module/canal
步骤2:解压安装包到/opt/module/canal
[atguigu@hadoop102 module]$ tar -zxvf canal.deployer-1.1.4.tar.gz -C /opt/module/canal/
步骤3:修改conf/canal.properties配置文件
[atguigu@hadoop202 conf]$ pwd
/opt/module/canal/conf
[atguigu@hadoop202 conf]$ vim canal.properties
修改内容:
tcp就是输出到canal客户端,通过编写java代码处理。
# 这个文件是canal基本通用配置,默认端口号11111
canal.port = 11111
# 修改1 canal的输出model,默认是tcp,改为输出到kafka
canal.serverMode = kafka
# 修改2 修改kafka集群地址
##################################################
######### MQ #############
##################################################
canal.mq.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
# 修改3 (可配)
#################################################
######### destinations #############
#################################################
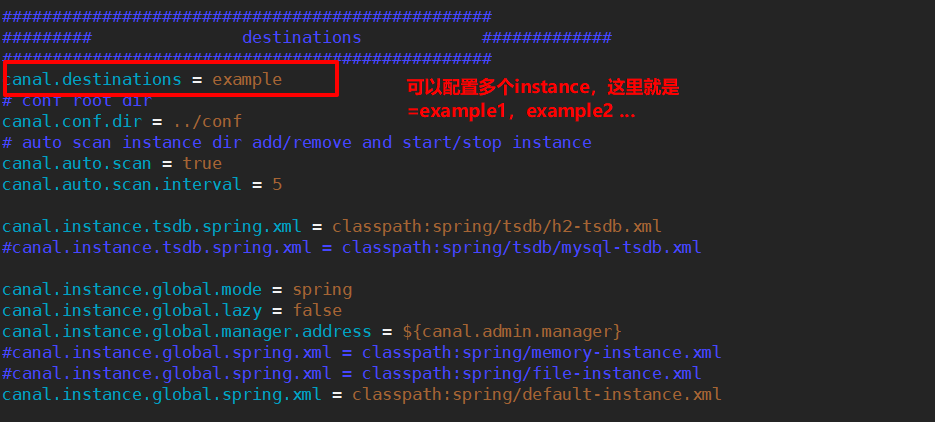
canal.destinations = example
步骤4:修改conf/example下的instance.properties文件
[atguigu@hadoop202 example]$ pwd
/opt/module/canal/conf/example
[atguigu@hadoop202 example]$ vim instance.properties
修改内容:
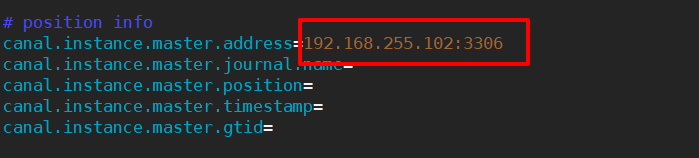
# 修改1 配置MySQL服务器地址
canal.instance.master.address=hadoop102:3306
# 修改2 配置MySQL的用户名和密码,默认是前面授权的canal
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
# 修改3 输出到Kafka的主题和分区数
canal.mq.topic=ODS_BASE_DB_C
canal.mq.partition=4
canal.mq.partitionHash=.*\\..*:$pk$
canal.mq.partitionHash表达式说明
注意:默认还是输出到指定Kafka主题的一个kafka分区,因为多个分区并行可能会打乱binlog的顺序。
如果要提高并行度,首先设置kafka的分区数>1,然后设置canal.mq.partitionHash属性,上图是以主键作为分区键。
# canal.mq.partitionHash=test.table:id^name,.*\\..* canal.mq.partitionHash=.*\\..*
注意:默认自动生成的kafka的topic分区数还是1,kafka的分区数是根据kafka中的server.properties配置的
[atguigu@hadoop102 config]$ vim server.properties

步骤5:启动canal
[atguigu@hadoop102 canal]$ bin/startup.sh
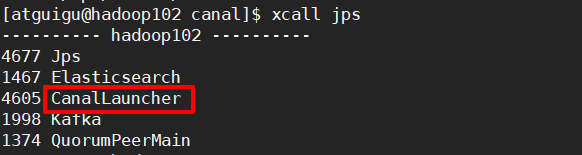
步骤6:查看kafka的topic
启动canal后,会同时创建一个配置文件中设置的主题:ODS_BASE_DB_C
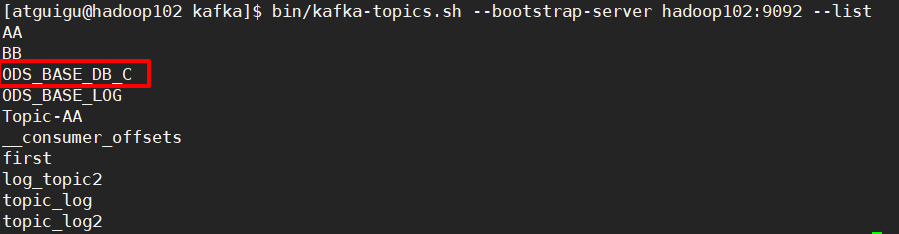
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic ODS_BASE_DB_C
# 分区数1?副本数1?
# 设置kafka中的server.properties中的默认partitions=4
步骤7:启动kafka消费者,查看消费情况
[atguigu@hadoop102 myredis]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic gmall_realtime_spark

3.2 canal高可用
这种zookeeper为观察者监控的模式,只能实现高可用,而不是负载均衡。也就是说集群中同一时刻只有一个canal-server节点能够监控某个数据源,这个节点就是active的;其他的节点的canal-server只能是standby。只有active的节点挂掉,其他的standby节点才能抢占。
所以开发环境一般不需要配置canal高可用。
步骤1:停止单机模式的canal
[atguigu@hadoop102 canal]$ bin/stop.sh

步骤2:在hadoop102上修改canal.properties
# 配置zookeeper
canal.zkServers = hadoop102:2181,hadoop103:2181,hadoop104:2181
# 避免发送重复数据(否在在切换active的时候会重复发送数据)
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml

步骤3:分发canal,到其他节点
[atguigu@hadoop102 module]$ xsync canal/
步骤4:在hadoop102上启动canal、再在hadoop103上启动canal
[atguigu@hadoop103 canal]$ bin/startup.sh

步骤5:启动kafka消费者
[atguigu@hadoop102 myredis]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic gmall_realtime_spark
步骤6:在MySQL中修改gmall_realtime_spark中一张表的一条信息,查看效果:

步骤7:把hadoop102的canal挂掉,再次查看kafka消费者的消费情况
[atguigu@hadoop102 canal]$ bin/stop.sh
3.3 canal监控多个MySQL
canal可以监控多个MySQL,每个MySQL就是一个实例。
一个canal服务中可以有多个instance。在conf/canal.properties中的下面配置可以配置多个实例example。
默认只有一个实例,如果要配置多个实例,需要设置上面的参数
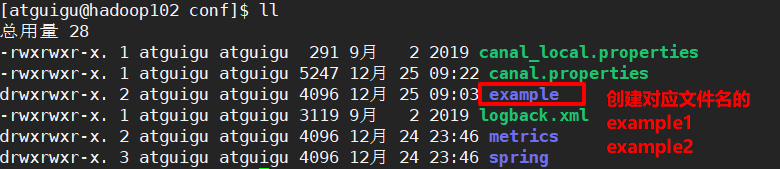
并且还要在拷贝多个example文件,修改里面的每个instance.properties
- 设置instance.properties文件中,监控的数据库,要发送的kafka的topic

4 canal版本的ODS层分流处理
4.1 数据格式:
canal接收到的数据格式:
{
"data":[{
"id":"3","name":"家用电器"}],"database":"gmall_realtime_spark","es":1608858266000,"id":2,"isDdl":false,"mysqlType":{
"id":"bigint(20)","name":"varchar(10)"},"old":[{
"name":"家用电器2"}],"pkNames":["id"],"sql":"","sqlType":{
"id":-5,"name":12},"table":"base_category1","ts":1608858266497,"type":"UPDATE"}

4.2 SparkStreaming对Topic分流
Canal会追踪整个数据库的变更,把所有数据变化都发到一个topic中了,但是为了后续方便,应该把这些表根据不同的表,分流到不同的主题中去。
①Kafka生产者发送数据工具类
/**
* 向Kafka发送数据(生产者)
*/
object MyKafkaSink {
private val properties: Properties = MyPropertiesUtil.load("config.properties")
private val broker_list: String = properties.getProperty("kafka.broker.list")
var kafkaProducer: KafkaProducer[String, String] = null
//创建Kafka的生产者
def createKafkaProducer() = {
//设置kafka生产者的参数
val properties = new Properties()
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, broker_list)
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true:java.lang.Boolean)
var producer: KafkaProducer[String, String] = null
try {
producer = new KafkaProducer[String, String](properties)
} catch {
case exception: Exception =>
exception.printStackTrace()
}
producer
}
//发送数据:指定topic和msg
def send(topic:String, msg:String):Unit = {
if (kafkaProducer == null)
createKafkaProducer()
kafkaProducer.send(new ProducerRecord[String, String](topic, msg))
}
//发送数据
def send(topic:String, key: String, msg:String):Unit = {
if (kafkaProducer == null)
createKafkaProducer()
kafkaProducer.send(new ProducerRecord[String, String](topic,key, msg))
}
}
开启生产者端生产数据的幂等性:
acks默认值是1,需要设置成all


②ODS_BaseDBCanalApp
步骤:
- 从Redis中获取偏移量
- 根据偏移量获取Kafka中的数据
- 获取当前批次对Kafka主题中分区消费的偏移量情况
- 对数据进行结构的转换ConsumerRecord ==> JSONObject
- 根据表名将数据发送到Kafka不同的Topic中
- 保存偏移量
/**
* 基于canal同步MySQL数据,从kafka中将数据读取出来,并且根据表名,将数据进行分流
* 发送到不同的主题中
*/
object BaseDBCanalApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("BaseDBCanalApp")
val ssc = new StreamingContext(conf, Duration(3000))
val topic = "gmall_realtime_spark_c"
val groupId = "base_db_canal_group"
//TODO 1 从Redis中获取偏移量
val offsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId)
//TODO 2 根据偏移量获取kafka中的数据
var InputDStream: InputDStream[ConsumerRecord[String, String]] = null
if (offsetMap != null && offsetMap.size > 0) {
InputDStream = MyKafkaUtil.getKafkaDStream(topic, ssc, offsetMap, groupId)
} else {
InputDStream = MyKafkaUtil.getKafkaDStream(topic, ssc, groupId)
}
//TODO 3 获取当前批次对Kafka主题中分区消费的偏移量情况
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val offsetDStream: DStream[ConsumerRecord[String, String]] = InputDStream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//TODO 4 对数据进行结构的转换ConsumerRecord ==> JSONObject
val jsonObjDStream: DStream[JSONObject] = offsetDStream.map {
record => {
//获取Json格式字符串
val jsonStr = record.value()
//将json格式字符串转换成json对象
val jsonObj = JSON.parseObject(jsonStr)
jsonObj
}
}
// jsonObjDStream.print(100)
//TODO 5 根据表名将数据发送到Kafka不同的Topic中
jsonObjDStream.foreachRDD{
rdd => {
rdd.foreach{
jsonObj => {
//获取类型
val opType = jsonObj.getString("type")
//对新增数据才执行操作
if ("INSERT".equals(opType)){
//获取表名
val tableName = jsonObj.getString("table")
//获取数据
val dataArr: JSONArray = jsonObj.getJSONArray("data")
//拼接要保存存的主题名
var sendTopic = "ods_" + tableName
//将json的数组转换成scala的数组
import scala.collection.JavaConverters._
for (data <- dataArr.asScala) {
val msg = data.toString
//发送数据到新的Topic
MyKafkaSink.send(sendTopic, msg)
}
}
}
}
//TODO 6 保存偏移量
OffsetManagerUtil.saveOffset(topic, groupId, offsetRanges)
}
}
ssc.start()
ssc.awaitTermination()
}
}