一、如何定义增量计算
有一家国外的网站这样定义了实时计算,增量计算,离线计算

我们以交通工具举个例子,来类比三种计算:
- 离线计算,就好比火车(绿皮车),每天发一次,每次能拉 1000 多人,延迟非常大,但每次能处理非常多的数据;
- 实时计算,就好比小汽车(私家车),每次拉的人不多,但满足时效性,想走就能走,但成本相对比较大;
- 增量计算,就好比是高铁(地铁或公交车),10 分钟来一趟,想来不一定能来,想走得去公交车站等车,但一趟车也能拉很多人。
二、增量计算的架构图

-
增量计算的增量体现在哪?
首先数据是要增量的入湖。 -
增量计算为什么要有消息队列的能力?
增量计算就是计算 5 分钟或者 10 分钟的数据,需要数据湖能从上次的地方继续开始消费。 -
增量计算为什么要支持 upsert 功能?
第一种场景:大屏显示,需要不断的修正数据,但 hdfs 做不到修正部分数据,要修正必须全量拿过来 merge,merge 完再覆盖,有 merge 就至少是 1 小时以上的延迟了。
第二种场景:延迟数据,比如现在要计算 1 分钟之内的数据,假设现在 1 分钟的数据计算完了,然后来了一条上个 1 分钟的数据,那么就要把上 1 分钟的数据再次计算一遍,再去修改。
所以,需要数据湖有 upsert 能力。
上图中,流计算和批计算的存储是统一的,但是计算引擎是不统一的,哪天 Flink 的功能更加完善了,就可以去掉 Spark,做到真正的计算和存储流批一体。
三、数据湖的核心原理(Iceberg)
官方对 Iceberg 的定义是一种 Open Table Format。
那什么是 table format?
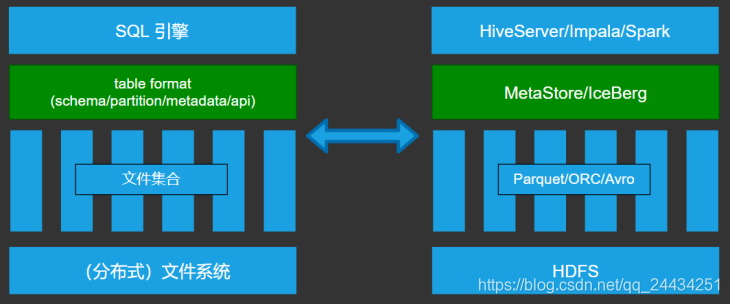
我们看下面的架构:
扫描二维码关注公众号,回复:
12683323 查看本文章

- 最下面是文件系统,负责存储
- 上面一层是文件集合,比如 parquet 文件集合,orc 集合
- 再上面一层就是 table format,由四个方面组成:
• schema
• partition(文件如何组织)
• metadata(元数据,描述文件的数据)
• api(如何访问这些表) - 再上面一层就是计算引擎
关注公众号:KK架构师,获取更多数据湖实战内容和资料
