黑马头条推荐系统项目课程定位、目标
定位
- 课程是机器学习(包含推荐算法)算法原理在推荐系统的实践
- 深入推荐系统的业务流场景、工具使用
- 作为人工智能的数据挖掘(推荐系统)方向应用项目
目标
- 熟练掌握推荐系统的实时推荐业务流
- 熟练掌握推荐系统lambda分布式计算工具、存储工具使用
- 熟练掌握黑马推荐离线计算、在线实时计算解决方案
黑马头条推荐架构介绍
1.1 黑马头条推荐业务架构介绍
学习目标
- 目标
- 无
- 应用
- 无
1.1.1业务
- 简介
黑马头条推荐系统建立在头条APP海量用户与海量文章之上,使用lambda大数据实时和离线计算整体架构,利用黑马头条用户在APP上的点击行为、浏览行为、收藏行为等建立用户与文章之间的画像关系,通过机器学习推荐算法进行智能推荐。增加热门文章和新文章的推荐占比,达到千人千面的用户推荐效果。
- 主要推荐场景
- 首页频道推荐
- 文章相似结果

1.1.2 架构与业务流


- 基础数据层:
- 包括业务数据和用户行为日志数据。
- 业务数据主要包含用户数据和文章数据,用户数据即黑马头条注册用户的基础数据,文章数据在自媒体平台上传的文章的基本信息。
- 用户行为日志数据来源于前端埋点
- 业务批量存储在HDFS上以用作离线分析
- 日志数据实时流向Kafka以用作实时计算
- 包括业务数据和用户行为日志数据。
- 数据处理层:
- 基础计算:基于离线和实时数据,对各类基础数据计算成用户画像、文章画像
- 召回与排序
- 召回环节使用各种算法逻辑从海量的文章中筛选出用户感兴趣的文章候选集合,集合大小:上千级别。排序即对候选集合中的文章进行用户相对的模型结果排序,生成一个排序列表。
- 召回
- 排序
- 点击率预估模型
- 特征处理、模型评价
- 推荐业务层:通过对外提供rpc接口来实现推荐业务的接入
- Feed流推荐:今日推荐场景,用户可以在这些页面中不断下拉刷新
1.3 开发环境介绍
学习目标
- 目标
- 了解黑马头条推荐系统基本环境
- 应用
- 无
1.3.1 设备
三台虚拟机,分别已配置好装有大数据计算环境
- hadoop-master: 192.168.19.137
- hadoop-slave1:192.168.19.138
- hadoop-slave2:192.168.19.139
VM虚拟机设置NAT模式,VM虚拟网卡固定好IP不变
- windows通过虚拟网卡编辑
- Mac参考https://kb.vmware.com/s/article/1026510
1.3.2 分布式环境
- hadoop-master
已经开启hadoop、hbase、spark、hive
20160 Jps
18786 Master
4131 RunJar # hive
17395 ResourceManager
19219 Worker
16757 NameNode
17206 SecondaryNameNode
18683 HRegionServer
8637 ThriftServer # happybase使用
18253 HMaster
18159 HQuorumPeer
- hadoop-slave1、hadoop-slave2
开启hadoop、hbase、spark
3857 NodeManager
4290 Worker
4680 Jps
3740 DataNode
3980 HQuorumPeer
4093 HRegionServers
1.3.3 python环境
装有anaconda系列虚拟环境即可,在这里先创建一个用于后面项目使用的虚拟环境,centos已提供miniconda2环境
以下环境:都在三台centos中安装
conda create -n reco_sys python=3.6.7
pip install -r requirements.txt --ignore-installed
开发配置
pycharm关联连接本地项目与centos项目目录开发,配置如下,添加远程机器的IP和用户名,往后密码以及python环境位置,本地关联远程工程目录

本地项目选定远程环境开发:
离线计算更新Item画像
2.2 数据库迁移
学习目标
- 目标
- 了解头条数据库迁移需求
- 知道Sqoop导入工具的测试
- 记忆Sqoop数据导入的增量导入形式
- 应用
- 应用Sqoop完成头条业务数据到HIVE的导入
2.2.1 数据库迁移需求
业务mysql数据库中的数据,会同步到我们的hadoop的hive数据仓库中。
- 为了避免直接连接、操作业务数据
- 同步一份数据在集群中方便进行数据分析操作
hive> show databases;
OK
default
profile
toutiao
Time taken: 0.017 seconds, Fetched: 3 row(s)
hive>
- 创建hive业务数据库toutiao
create database if not exists toutiao comment "user,news information of 136 mysql" location '/user/hive/warehouse/toutiao.db/';
2.2.2 sqoop迁移Mysql业务数据
2.2.2.1 Mysql业务数据
这里我们默认mysql业务数据库就在本地ymysql中(真实生产肯定在头条Web业务所在服务器)。
MariaDB [toutiao]> show tables;
+------------------------------+
| Tables_in_toutiao |
+------------------------------+
| global_announcement |
| mis_administrator |
| mis_administrator_group |
| mis_group_permission |
| mis_operation_log |
| mis_permission |
| news_article_basic |
| news_article_content |
| news_article_statistic |
| news_attitude |
| news_channel |
| news_collection |
| news_comment |
| news_comment_liking |
| news_read |
| news_report |
| news_user_channel |
| recommend_sensitive_word |
| statistics_basic |
| statistics_read_source_total |
| statistics_sales_total |
| statistics_search |
| statistics_search_total |
| user_basic |
| user_blacklist |
| user_legalize_log |
| user_material |
| user_profile |
| user_qualification |
| user_relation |
| user_search |
+------------------------------+
这些数据库并不是所有都需要,我们会同步其中后面业务中会用到的5张表(文章推荐用到,如果其他分析场景可能会需要同步更多表)
增量更新业务数据库到当前hive中,获取用户的资料更新画像,更新文章
- 用户资料信息呢两张表:user_profile,user_basic
- 文章内容基本信息、频道三张表:news_article_basic,news_article_content,news_channel
用户的:
MariaDB [toutiao]> select * from user_profile limit 1;
+---------+--------+------------+-----------+---------------------+---------------------+---------------------+-----------+---------------+--------------+------------------+------+---------+--------+
| user_id | gender | birthday | real_name | create_time | update_time | register_media_time | id_number | id_card_front | id_card_back | id_card_handheld | area | company | career |
+---------+--------+------------+-----------+---------------------+---------------------+---------------------+-----------+---------------+--------------+------------------+------+---------+--------+
| 1 | 1 | 2019-04-10 | NULL | 2018-12-28 14:26:32 | 2019-04-10 20:02:56 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
+---------+--------+------------+-----------+---------------------+---------------------+---------------------+-----------+---------------+--------------+------------------+------+---------+--------+
MariaDB [toutiao]> select * from user_basic limit 1;
+---------+-------------+----------+-----------------+------------------------------+---------------------+----------+---------------+-----------------+------------+------------+------------+-----------------+-------------+-------------+---------+-------------+--------+
| user_id | mobile | password | user_name | profile_photo | last_login | is_media | article_count | following_count | fans_count | like_count | read_count | introduction | certificate | is_verified | account | email | status |
+---------+-------------+----------+-----------------+------------------------------+---------------------+----------+---------------+-----------------+------------+------------+------------+-----------------+-------------+-------------+---------+-------------+--------+
| 1 | 18516952650 | NULL | 黑马头条号 | Fob52h_THjiZ47sJAHu_-iu0TO24 | 2018-11-29 11:46:10 | 0 | 46150 | 5 | 1 | 0 | 631 | 测试头条号 | | 1 | NULL | [email protected] | 1 |
+---------+-------------+----------+-----------------+------------------------------+---------------------+----------+---------------+-----------------+------------+------------+------------+-----------------+-------------+-------------+---------+-------------+--------+
文章的:
MariaDB [toutiao]> select * from news_article_basic limit 1;
+------------+---------+------------+-------------------------------+-------------------------+----------------+---------------------+--------+-------------+-------------+-------------+---------------+---------------+---------------------+---------------+
| article_id | user_id | channel_id | title | cover | is_advertising | create_time | status | reviewer_id | review_time | delete_time | comment_count | allow_comment | update_time | reject_reason |
+------------+---------+------------+-------------------------------+-------------------------+----------------+---------------------+--------+-------------+-------------+-------------+---------------+---------------+---------------------+---------------+
| 1 | 1 | 17 | Vue props用法小结
原
荐 | {"type":0, "images":[]} | 0 | 2018-11-29 15:02:17 | 2 | NULL | NULL | NULL | 0 | 1 | 2019-02-18 11:08:16 | NULL |
+------------+---------+------------+-------------------------------+-------------------------+----------------+---------------------+--------+-------------+-------------+-------------+---------------+---------------+---------------------+---------------+
MariaDB [toutiao]> select * from news_channel limit 1;
+------------+--------------+---------------------+---------------------+----------+------------+------------+
| channel_id | channel_name | create_time | update_time | sequence | is_visible | is_default |
+------------+--------------+---------------------+---------------------+----------+------------+------------+
| 1 | html | 2018-11-29 13:58:53 | 2019-03-15 15:26:30 | 1 | 1 | 0 |
+------------+--------------+---------------------+---------------------+----------+------------+------------+
2.2.2.2 Sqoop 迁移
sqoop list-databases --connect jdbc:mysql://192.168.19.137:3306/ --username root -P
会显示连接到的数据库
information_schema
hive
mysql
performance_schema
sys
toutiao
-
两种导入形式,我们选择增量,定期导入新数据
- sqoop全量导入
#!/bin/bash array=(user_profile user_basic news_user_channel news_channel user_follow user_blacklist user_search news_collection news_article_basic news_article_content news_read news_article_statistic user_material) for table_name in ${array[@]}; do sqoop import \ --connect jdbc:mysql://192.168.19.137/toutiao \ --username root \ --password password \ --table $table_name \ --m 5 \ --hive-home /root/bigdata/hive \ --hive-import \ --create-hive-table \ --hive-drop-import-delims \ --warehouse-dir /user/hive/warehouse/toutiao.db \ --hive-table toutiao.$table_name done-
sqoop增量导入
-
append:即通过指定一个递增的列,如:--incremental append --check-column num_iid --last-value 0
-
incremental: 时间戳,比如:
--incremental lastmodified \ --check-column column \ --merge-key key \ --last-value '2012-02-01 11:0:00' -
就是只导入check-column的列比'2012-02-01 11:0:00'更大的数据,按照key合并
-
-
导入最终结果两种形式,选择后者
- 直接sqoop导入到hive(–incremental lastmodified模式不支持导入Hive )
- sqoop导入到hdfs,然后建立hive表关联
- --target-dir /user/hive/warehouse/toutiao.db/
2.2.2.3 Sqoop 迁移案例
- 避坑指南:
- 导入数据到hive中,需要在创建HIVE表加入 row format delimited fields terminated by ','
hadoop数据在hive中查询就全是NULL,原因: sqoop 导出的 hdfs 分片数据,都是使用逗号 , 分割的,由于 hive 默认的分隔符是 /u0001(Ctrl+A),为了平滑迁移,需要在创建表格时指定数据的分割符号。
8,false,null,null,2019-01-10 17:44:32.0,2019-01-10 17:44:32.0,null,null,null,null,null,null,null,null
9,false,null,null,2019-01-15 23:41:13.0,2019-01-15 23:41:13.0,null,null,null,null,null,null,null,null
hive中查询
NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL
NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL
NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL
- 1、user_profile表:
- 使用lastmodified模式
- mysql数据库中更新时候update_time会修改最近时间,按照user_id合并(增量导入进去会有新的重复的数据,需要合并)
- 指定last_time时间
- 2、user_basic表:
- 使用lastmodified模式
- last_login作为更新时间
- 指定last_time时间,按照user_id合并
Mysql导入对应hive类型:
MySQL(bigint) --> Hive(bigint)
MySQL(tinyint) --> Hive(tinyint)
MySQL(int) --> Hive(int)
MySQL(double) --> Hive(double)
MySQL(bit) --> Hive(boolean)
MySQL(varchar) --> Hive(string)
MySQL(decimal) --> Hive(double)
MySQL(date/timestamp) --> Hive(string)
create table user_profile(
user_id BIGINT comment "userID",
gender BOOLEAN comment "gender",
birthday STRING comment "birthday",
real_name STRING comment "real_name",
create_time STRING comment "create_time",
update_time STRING comment "update_time",
register_media_time STRING comment "register_media_time",
id_number STRING comment "id_number",
id_card_front STRING comment "id_card_front",
id_card_back STRING comment "id_card_back",
id_card_handheld STRING comment "id_card_handheld",
area STRING comment "area",
company STRING comment "company",
career STRING comment "career")
COMMENT "toutiao user profile"
row format delimited fields terminated by ','
LOCATION '/user/hive/warehouse/toutiao.db/user_profile';
create table user_basic(
user_id BIGINT comment "user_id",
mobile STRING comment "mobile",
password STRING comment "password",
profile_photo STRING comment "profile_photo",
last_login STRING comment "last_login",
is_media BOOLEAN comment "is_media",
article_count BIGINT comment "article_count",
following_count BIGINT comment "following_count",
fans_count BIGINT comment "fans_count",
like_count BIGINT comment "like_count",
read_count BIGINT comment "read_count",
introduction STRING comment "introduction",
certificate STRING comment "certificate",
is_verified BOOLEAN comment "is_verified")
COMMENT "toutiao user basic"
row format delimited fields terminated by ','
LOCATION '/user/hive/warehouse/toutiao.db/user_basic';
导入脚本,创建一个脚本文件执行import_incremental.sh脚本:
- -m:指定同时导入的线程数量
- 连接地址以及账号密码,表、目录
- 指定要导入的时间
time=`date +"%Y-%m-%d" -d "-1day"`
declare -A check
check=([user_profile]=update_time [user_basic]=last_login [news_channel]=update_time)
declare -A merge
merge=([user_profile]=user_id [user_basic]=user_id [news_channel]=channel_id)
for k in ${!check[@]}
do
sqoop import \
--connect jdbc:mysql://192.168.19.137/toutiao \
--username root \
--password password \
--table $k \
--m 4 \
--target-dir /user/hive/warehouse/toutiao.db/$k \
--incremental lastmodified \
--check-column ${check[$k]} \
--merge-key ${merge[$k]} \
--last-value ${time}
done
当我们运行脚本并成功时候:


- 避坑指南:
- 如果运行失败:请检查相关问题
- 1、连接JDBC的IP 地址 或者主机名是否错误
- 2、确认mysql数据库打开并且能够sqoop测试成功
运行一段时间完成之后,回到HIVE数据中查询,能查询到内容并且内容无误
hive> show tables;
OK
news_article_basic
news_channel
user_basic
user_profile
Time taken: 0.647 seconds, Fetched: 4 row(s)
hive> select * from user_profile limit 1;
OK
1 false null null 2018-12-28 14:26:32.0 2018-12-28 14:26:32.0 null null null null null null null null
Time taken: 3.516 seconds, Fetched: 1 row(s)
- 3、文章表导入news_article_basic,news_article_content、news_channel
- news_article_basic:
- 按照键review_time更新
- 合并按照article_id
- 指定时间
create table news_article_basic(
article_id BIGINT comment "article_id",
user_id BIGINT comment "user_id",
channel_id BIGINT comment "channel_id",
title STRING comment "title",
status BIGINT comment "status",
update_time STRING comment "update_time")
COMMENT "toutiao news_article_basic"
row format delimited fields terminated by ','
LOCATION '/user/hive/warehouse/toutiao.db/news_article_basic';
原mysql数据库中某些字段的值存在一些特定的字符,如","、"\t", "\n"这些字符都会导致导入到hadoop被hive读取失败,解析时会认为另一条数据或者多一个字段
- 解决方案:
- 在导入时,加入—query参数,从数据库中选中对应字段,过滤相应内容,使用REPLACE、CHAR(或者CHR)进行替换字符
- 并且mysql表中存在tinyibt必须在connet中加入: ?tinyInt1isBit=false
导入脚本:
# 方案:导入方式,过滤相关字符
sqoop import \
--connect jdbc:mysql://192.168.19.137/toutiao?tinyInt1isBit=false \
--username root \
--password password \
--m 4 \
--query 'select article_id, user_id, channel_id, REPLACE(REPLACE(REPLACE(title, CHAR(13),""),CHAR(10),""), ",", " ") title, status, update_time from news_article_basic WHERE $CONDITIONS' \
--split-by user_id \
--target-dir /user/hive/warehouse/toutiao.db/news_article_basic \
--incremental lastmodified \
--check-column update_time \
--merge-key article_id \
--last-value ${time}
- 4、news_channel
- 跟上面用户的表处理方式相同,按照update_time键更新
- 按照channel_id合并
- 更新时间
create table news_channel(
channel_id BIGINT comment "channel_id",
channel_name STRING comment "channel_name",
create_time STRING comment "create_time",
update_time STRING comment "update_time",
sequence BIGINT comment "sequence",
is_visible BOOLEAN comment "is_visible",
is_default BOOLEAN comment "is_default")
COMMENT "toutiao news_channel"
row format delimited fields terminated by ','
LOCATION '/user/hive/warehouse/toutiao.db/news_channel';
- 5、由于news_article_content文章内容表中含有过多特殊字符,选择直接全量导入
# 全量导入(表只是看结构,不需要在HIVE中创建,因为是直接导入HIVE,会自动创建news_article_content)
create table news_article_content(
article_id BIGINT comment "article_id",
content STRING comment "content")
COMMENT "toutiao news_article_content"
row format delimited fields terminated by ','
LOCATION '/user/hive/warehouse/toutiao.db/news_article_content';
直接导入到HIVE汇总,导入脚本为:
sqoop import \
--connect jdbc:mysql://192.168.19.137/toutiao \
--username root \
--password password \
--table news_article_content \
--m 4 \
--hive-home /root/bigdata/hive \
--hive-import \
--hive-drop-import-delims \
--hive-table toutiao.news_article_content \
--hive-overwrite
2.2.3 总结
- sqoop导入业务数据到hadoop操作
- 增量导入形式
2.3 用户行为收集到HIVE
学习目标
- 目标
- 知道收集用户日志形式、流程
- 知道flume收集相关配置、hive相关配置
- 知道supervisor开启flume收集进程管理
- 应用
- 应用supervisor管理flume实时收集点击日志
2.3.1 为什么要收集用户点击行为日志
用户行为对于黑马头条文章推荐来说,至关重要。用户的行为代表的每一次的喜好反馈,我们需要收集起来并且存到HIVE
- 便于了解分析用户的行为、喜好变化
- 为用户建立画像提供依据

2.3.2 用户日志如何收集
2.3.2.1 埋点开发测试流程
一般用户有很多日志,我们当前黑马头条推荐场景统一到行为日志中,还有其它业务场景如(下单日志、支付日志)
- 埋点参数
- 就是在应用中特定的流程收集一些信息,用来跟踪应用使用的状况,后续用来进一步优化产品或是提供运营的数据支撑
- 重要性:埋点数据是推荐系统的基石,模型训练和效果数据统计都基于埋点数据,需保证埋点数据的正确无误
- 流程:
- 1、PM(项目经理)、算法推荐工程师一起指定埋点需求文档
- 2、后端、客户端 APP集成
- 3、推荐人员基于文档埋点测试与梳理
2.3.2.2 黑马头条文章推荐埋点需求整理
文章行为特点:点击、浏览、收藏、分享等行为,基于这些我们制定需求
-
埋点场景
-
- 首页中的各频道推荐
-
埋点事件号
-
-
停留时间
-
- read
-
点击事件
-
- click
-
曝光事件(相当于刷新一次请求推荐新文章)
-
- exposure
-
收藏事件
-
- collect
-
分享事件
-
- share
-
-
埋点参数文件结构
# 曝光的参数,
{"actionTime":"2019-04-10 18:15:35","readTime":"","channelId":0,"param":{"action": "exposure", "userId": "2", "articleId": "[18577, 14299]", "algorithmCombine": "C2"}}
# 对文章发生行为的参数
{"actionTime":"2019-04-10 18:12:11","readTime":"2886","channelId":18,"param":{"action": "read", "userId": "2", "articleId": "18005", "algorithmCombine": "C2"}}
{"actionTime":"2019-04-10 18:15:32","readTime":"","channelId":18,"param":{"action": "click", "userId": "2", "articleId": "18005", "algorithmCombine": "C2"}}
{"actionTime":"2019-04-10 18:15:34","readTime":"1053","channelId":18,"param":{"action": "read", "userId": "2", "articleId": "18005", "algorithmCombine": "C2"}}
{"actionTime":"2019-04-10 18:15:36","readTime":"","channelId":18,"param":{"action": "click", "userId": "2", "articleId": "18577", "algorithmCombine": "C2"}}
{"actionTime":"2019-04-10 18:15:38","readTime":"1621","channelId":18,"param":{"action": "read", "userId": "2", "articleId": "18577", "algorithmCombine": "C2"}}
{"actionTime":"2019-04-10 18:15:39","readTime":"","channelId":18,"param":{"action": "click", "userId": "1", "articleId": "14299", "algorithmCombine": "C2"}}
{"actionTime":"2019-04-10 18:15:39","readTime":"","channelId":18,"param":{"action": "click", "userId": "2", "articleId": "14299", "algorithmCombine": "C2"}}
{"actionTime":"2019-04-10 18:15:41","readTime":"914","channelId":18,"param":{"action": "read", "userId": "2", "articleId": "14299", "algorithmCombine": "C2"}}
{"actionTime":"2019-04-10 18:15:47","readTime":"7256","channelId":18,"param":{"action": "read", "userId": "1", "articleId": "14299", "algorithmCombine": "C2"}}
我们将埋点参数设计成一个固定格式的json字符串,它包含了事件发生事件、算法推荐号、获取行为的频道号、帖子id列表、帖子id、用户id、事件号字段。
2.3.3 离线部分-用户日志收集
2.3.3.1目的:通过flume将业务数据服务器A的日志收集到hadoop服务器hdfs的hive中
注意:这里我们都在hadoop-master上操作
2.3.3.2 收集步骤
- 创建HIVE对应日志收集表
- 收集到新的数据库中
- flume收集日志配置
- 开启收集命令
2.3.3.3 实现
1、flume读取设置
- 进入flume/conf目录
创建一个collect_click.conf的文件,写入flume的配置
- sources:为实时查看文件末尾,interceptors解析json文件
- channels:指定内存存储,并且制定batchData的大小,PutList和TakeList的大小见参数,Channel总容量大小见参数
- 指定sink:形式直接到hdfs,以及路径,文件大小策略默认1024、event数量策略、文件闲置时间
a1.sources = s1
a1.sinks = k1
a1.channels = c1
a1.sources.s1.channels= c1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /root/logs/userClick.log
a1.sources.s1.interceptors=i1 i2
a1.sources.s1.interceptors.i1.type=regex_filter
a1.sources.s1.interceptors.i1.regex=\\{.*\\}
a1.sources.s1.interceptors.i2.type=timestamp
# channel1
a1.channels.c1.type=memory
a1.channels.c1.capacity=30000
a1.channels.c1.transactionCapacity=1000
# k1
a1.sinks.k1.type=hdfs
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.path=hdfs://192.168.19.137:9000/user/hive/warehouse/profile.db/user_action/%Y-%m-%d
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=60
2、HIVE设置
解决办法可以按照日期分区
- 修改表结构
- 修改flume
在这里我们创建一个新的数据库profile,表示用户相关数据,画像存储到这里
create database if not exists profile comment "use action" location '/user/hive/warehouse/profile.db/';
在profile数据库中创建user_action表,指定格式
create table user_action(
actionTime STRING comment "user actions time",
readTime STRING comment "user reading time",
channelId INT comment "article channel id",
param map comment "action parameter")
COMMENT "user primitive action"
PARTITIONED BY(dt STRING)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
LOCATION '/user/hive/warehouse/profile.db/user_action';
- ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe':添加一个json格式匹配
重要:这样就有HIVE的user_action表,并且hadoop有相应目录,flume会自动生成目录,但是如果想要通过spark sql 获取内容,每天每次还是要主动关联,后面知识点会提及)
# 如果flume自动生成目录后,需要手动关联分区
alter table user_action add partition (dt='2018-12-11') location "/user/hive/warehouse/profile.db/user_action/2018-12-11/"
3. 开启收集命令
/root/bigdata/flume/bin/flume-ng agent -c /root/bigdata/flume/conf -f /root/bigdata/flume/conf/collect_click.conf -Dflume.root.logger=INFO,console -name a1
如果运行成功:

同时我们可以通过向userClick.log数据进行测试
echo {\"actionTime\":\"2019-04-10 21:04:39\",\"readTime\":\"\",\"channelId\":18,\"param\":{\"action\": \"click\", \"userId\": \"2\", \"articleId\": \"14299\", \"algorithmCombine\": \"C2\"}} >> userClick.log
2.3.3 Supervisor进程管理
Supervisor作为进程管理工具,很方便的监听、启动、停止、重启一个或多个进程。用Supervisor管理的进程,当一个进程意外被杀死,supervisort监听到进程死后,会自动将它重新拉起,很方便的做到进程自动恢复的功能,不再需要自己写shell脚本来控制。
安装
sudo yum install python-pip # python2 pip apt-get
supervisor对python3支持不好,须使用python2环境
sudo pip install supervisor
配置
运行echo_supervisord_conf命令输出默认的配置项,可以如下操作将默认配置保存到文件中
echo_supervisord_conf > supervisord.conf
vim 打开编辑supervisord.conf文件,修改
[include]
files = relative/directory/*.ini
为
[include]
files = /etc/supervisor/*.conf
include选项指明包含的其他配置文件。
- 将编辑后的supervisord.conf文件复制到/etc/目录下
sudo cp supervisord.conf /etc/
- 然后我们在/etc目录下新建子目录supervisor(与配置文件里的选项相同),并在/etc/supervisor/中新建头条推荐管理的配置文件reco.conf
加入配置模板如下(模板):
[program:recogrpc]
command=/root/anaconda3/envs/reco_sys/bin/python /root/headlines_project/recommend_system/ABTest/routing.py
directory=/root/headlines_project/recommend_system/ABTest
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/reco.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true
[program:kafka]
command=/bin/bash /root/headlines_project/scripts/startKafka.sh
directory=/root/headlines_project/scripts
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/kafka.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true
启动
supervisord -c /etc/supervisord.conf
查看 supervisord 是否在运行:
ps aux | grep supervisord
supervisorctl
我们可以利用supervisorctl来管理supervisor。
supervisorctl
> status # 查看程序状态
> start apscheduler # 启动 apscheduler 单一程序
> stop toutiao:* # 关闭 toutiao组 程序
> start toutiao:* # 启动 toutiao组 程序
> restart toutiao:* # 重启 toutiao组 程序
> update # 重启配置文件修改过的程序
执行status命令时,显示如下信息说明程序运行正常:
supervisor> status
toutiao:toutiao-app RUNNING pid 32091, uptime 00:00:02
2.3.4 启动监听flume收集日志程序
目的: 启动监听flume收集日志
- 我们将启动flume的程序建立成collect_click.sh脚本
flume启动需要相关hadoop,java环境,可以在shell程序汇总添加
#!/usr/bin/env bash
export JAVA_HOME=/root/bigdata/jdk
export HADOOP_HOME=/root/bigdata/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
/root/bigdata/flume/bin/flume-ng agent -c /root/bigdata/flume/conf -f /root/bigdata/flume/conf/collect_click.conf -Dflume.root.logger=INFO,console -name a1
- 并在supervisor的reco.conf添加
[program:collect-click]
command=/bin/bash /root/toutiao_project/scripts/collect_click.sh
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/collect.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true
2.3.5 HIVE历史点击数据导入
收集今天的点击行为数据,并且也只能生成今天一个日志目录,后面为了更多的日志数据处理,需要进行历史数据导入,这里我拷贝了历史数据在本地
这样就有

-
步骤
- 之前的Hadoop收集的若干时间之前的数据拷贝到hadoop对应hive数据目录中
-
实现
我们选择全部覆盖了,测试数据不要了
hadoop dfs -put ./hadoopbak/profile.db/user_action/ /user/hive/warehouse/profile.db/
2.3.6 总结
- 用户行为日志收集的相关工作流程
- flume收集到hive配置
- supervisor进程管理工具使用
2.1 离线画像业务介绍
学习目标
- 目标
- 了解画像的构建
- 应用
- 无
2.1.2 离线画像流程
画像构建流程位置:

画像构建内容:
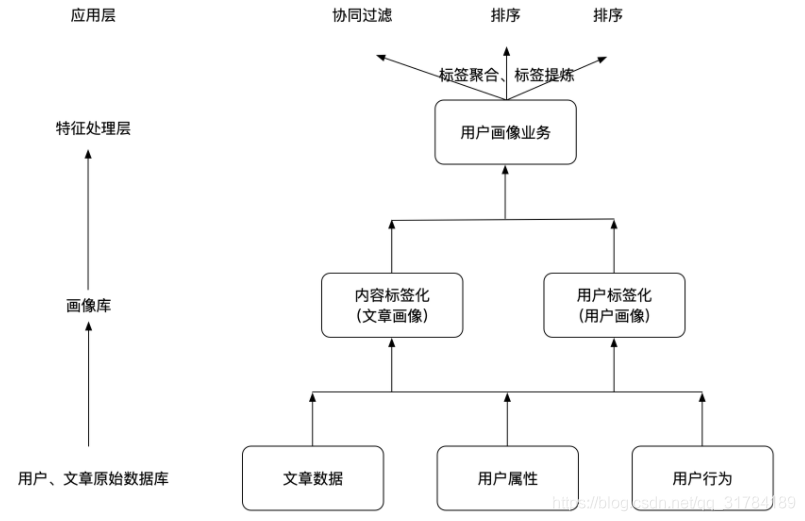
画像的构建作为推荐系统非常重要的环节,画像可以作为整个产品的推荐或者营销重要依据。需要通过各种方法来构建。
-
文章内容标签化:内容标签化,根据内容定性的制定一系列标签,这些标签可以是描述性标签。针对于文章就是文章相关的内容词语。
- 文章的关键词、主题词
-
用户标签化:这个过程就是需要研究用户对内容的喜好程度,用户喜欢的内容即当作用户喜好的标签。
- 在用户行为记录表中,我们所记下用户的行为在此时就发挥出重要的作用了。用户的浏览(时长/频率)、点击、分享/收藏/关注、其他商业化或关键信息均不同程度的代表的用户对这个内容的喜好程度。

2.4 离线文章画像计算
学习目标
- 目标
- 了解文章画像构成
- 知道spark tfidf以及TextRank计算工具使用
- 知道文章画像的计算和构建
- 应用
- 应用spark完成文章Tfidf值计算
- 应用spark完成文章TextRank值计算
- 应用spark完成文章画像结果值计算与存储
工程目录如下

离线文章画像组成需求
文章画像,就是给每篇文章定义一些词。
- 关键词:TEXTRANK + IDF共同的词
- 主题词:TEXTRANK + ITFDF共同的词
查看结果:
hive> desc article_profile;
OK
article_id int article_id
channel_id int channel_id
keywords map keywords
topics array topics
hive> select * from article_profile limit 1;
OK
26 17 {"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
步骤:
1、原始文章表数据合并
2、所有历史文章Tfidf计算
3、所有历史文章TextRank计算
2.4.1 原始文章数据的合并
为了方便与进行文章数据操作,将文章相关重要信息表合并在一起。通过spark sql 来进行操作
2.4.1.1 创建Spark初始化相关配置
在_init_文件中,创建一个经常用到的基类
- 定义好spark启动的类别,以及相关内存设置
SPARK_APP_NAME = None # APP的名字
SPARK_URL = "yarn" # 启动运行方式
SPARK_EXECUTOR_MEMORY = "2g" # 执行内存
SPARK_EXECUTOR_CORES = 2 # 每个EXECUTOR能够使用的CPU core的数量
SPARK_EXECUTOR_INSTANCES = 2 # 最多能够同时启动的EXECUTOR的实例个数
ENABLE_HIVE_SUPPORT = False
- 创建相关配置、包,建立基类
from pyspark import SparkConf
from pyspark.sql import SparkSession
import os
class SparkSessionBase(object):
SPARK_APP_NAME = None
SPARK_URL = "yarn"
SPARK_EXECUTOR_MEMORY = "2g"
SPARK_EXECUTOR_CORES = 2
SPARK_EXECUTOR_INSTANCES = 2
ENABLE_HIVE_SUPPORT = False
def _create_spark_session(self):
conf = SparkConf() # 创建spark config对象
config = (
("spark.app.name", self.SPARK_APP_NAME), # 设置启动的spark的app名称,没有提供,将随机产生一个名称
("spark.executor.memory", self.SPARK_EXECUTOR_MEMORY), # 设置该app启动时占用的内存用量,默认2g
("spark.master", self.SPARK_URL), # spark master的地址
("spark.executor.cores", self.SPARK_EXECUTOR_CORES), # 设置spark executor使用的CPU核心数,默认是1核心
("spark.executor.instances", self.SPARK_EXECUTOR_INSTANCES)
)
conf.setAll(config)
# 利用config对象,创建spark session
if self.ENABLE_HIVE_SUPPORT:
return SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
else:
return SparkSession.builder.config(conf=conf).getOrCreate()
新建一个目录,用于进行文章内容相关计算目录,创建reco_sys推荐系统相关计算主目录:下面建立离线offline以及full_cal
[root@hadoop-master reco_sys]#
[root@hadoop-master reco_sys]# tree
.
└── offline
├── full_cal
└── __init__.py
2.4.1.2 进行合并计算
由于每次调试运行spark时间较长,我们最终代码放在pycharm开发目录中,使用jupyter notebook进行开发
在项目目录开启
jupyter notebook --allow-root --ip=192.168.19.137
- 注意:本地内存不足的情况下,尽量不要同时运行多个Spark APP,否则比如查询HVIE操作会很慢,磁盘也保证足够

- 1、新建文章数据库,存储文章数据、中间计算结果以及文章画像结果
create database if not exists article comment "artcile information" location '/user/hive/warehouse/article.db/';
- 1、原始文章数据合并表结构,在article数据库中
- sentence:文章标题+内容+频道名字的合并结果
CREATE TABLE article_data(
article_id BIGINT comment "article_id",
channel_id INT comment "channel_id",
channel_name STRING comment "channel_name",
title STRING comment "title",
content STRING comment "content",
sentence STRING comment "sentence")
COMMENT "toutiao news_channel"
LOCATION '/user/hive/warehouse/article.db/article_data';
hive> select * from article_data limit 1;
OK
1 17 前端 Vue props用法小结原荐 <p><strong>Vue props用法详解</strong>组件接受的选项之一 props 是 Vue 中非常重要的一个选项。父子组件的关系可以总结为
- 3、新建merge_data.ipynb文件
- 初始化spark信息
import os
import sys
# 如果当前代码文件运行测试需要加入修改路径,避免出现后导包问题
BASE_DIR = os.path.dirname(os.path.dirname(os.getcwd()))
sys.path.insert(0, os.path.join(BASE_DIR))
PYSPARK_PYTHON = "/miniconda2/envs/reco_sys/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
from offline import SparkSessionBase
创建合并文章类,集成sparksessionbase
class OriginArticleData(SparkSessionBase):
SPARK_APP_NAME = "mergeArticle"
SPARK_URL = "yarn"
ENABLE_HIVE_SUPPORT = True
def __init__(self):
self.spark = self._create_spark_session()
- 读取文章进行处理合并
oa = OriginArticleData()
oa.spark.sql("use toutiao")
# 由于运行速度原因,选择部分数据进行测试
basic_content = oa.spark.sql(
"select a.article_id, a.channel_id, a.title, b.content from news_article_basic a inner join news_article_content b on a.article_id=b.article_id where a.article_id=116636")
合并数据
import pyspark.sql.functions as F
import gc
# 增加channel的名字,后面会使用
basic_content.registerTempTable("temparticle")
channel_basic_content = oa.spark.sql(
"select t.*, n.channel_name from temparticle t left join news_channel n on t.channel_id=n.channel_id")
# 利用concat_ws方法,将多列数据合并为一个长文本内容(频道,标题以及内容合并)
oa.spark.sql("use article")
sentence_df = channel_basic_content.select("article_id", "channel_id", "channel_name", "title", "content", \
F.concat_ws(
",",
channel_basic_content.channel_name,
channel_basic_content.title,
channel_basic_content.content
).alias("sentence")
)
del basic_content
del channel_basic_content
gc.collect()
# sentence_df.write.insertInto("article_data")
运行需要时间等待成功,如果还有其他程序运行,手动释放内存,避免不够
del basic_content
del channel_basic_content
gc.collect()
然后执行查询,看看是否写入选定的文章
hive> select * from article_data;
上传合并完成的所有历史数据
以上测试在少量数据上进行测试写入合并文章数据,最终我们拿之前合并的所有文章数据直接上传到hadoop上使用
hadoop dfs -put /root/hadoopbak/article.db/article_data/ /user/hive/warehouse/article.db/article_data/
2.4.2 Tfidf计算
2.4.2.1 目的
- 计算出每篇文章的词语的TFIDF结果用于抽取画像
2.4.2.2TFIDF模型的训练步骤
- 读取N篇文章数据
- 文章数据进行分词处理
- TFIDF模型训练保存,spark使用count与idf进行计算
- 利用模型计算N篇文章数据的TFIDF值
2.4.2.3 实现
想要用TFIDF进行计算,需要训练一个模型保存结果
- 新建一个compute_tfidf.ipynb的文件
import os
import sys
# 如果当前代码文件运行测试需要加入修改路径,避免出现后导包问题
BASE_DIR = os.path.dirname(os.path.dirname(os.getcwd()))
sys.path.insert(0, os.path.join(BASE_DIR))
PYSPARK_PYTHON = "/miniconda2/envs/reco_sys/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
from offline import SparkSessionBase
class KeywordsToTfidf(SparkSessionBase):
SPARK_APP_NAME = "keywordsByTFIDF"
SPARK_EXECUTOR_MEMORY = "7g"
ENABLE_HIVE_SUPPORT = True
def __init__(self):
self.spark = self._create_spark_session()
ktt = KeywordsToTfidf()
- 读取文章原始数据
ktt.spark.sql("use article")
article_dataframe = ktt.spark.sql("select * from article_data limit 20")
words_df = article_dataframe.rdd.mapPartitions(segmentation).toDF(["article_id", "channel_id", "words"])
- 文章数据处理函数
- 结巴词典,以及停用词(词典文件,三台Centos都需要上传一份,目录相同)
- ITKeywords.txt, stopwords.txt
scp -r ./words/ [email protected]:/root/words/
scp -r ./words/ [email protected]:/root/words/
分词部分代码:
# 分词
def segmentation(partition):
import os
import re
import jieba
import jieba.analyse
import jieba.posseg as pseg
import codecs
abspath = "/root/words"
# 结巴加载用户词典
userDict_path = os.path.join(abspath, "ITKeywords.txt")
jieba.load_userdict(userDict_path)
# 停用词文本
stopwords_path = os.path.join(abspath, "stopwords.txt")
def get_stopwords_list():
"""返回stopwords列表"""
stopwords_list = [i.strip()
for i in codecs.open(stopwords_path).readlines()]
return stopwords_list
# 所有的停用词列表
stopwords_list = get_stopwords_list()
# 分词
def cut_sentence(sentence):
"""对切割之后的词语进行过滤,去除停用词,保留名词,英文和自定义词库中的词,长度大于2的词"""
# print(sentence,"*"*100)
# eg:[pair('今天', 't'), pair('有', 'd'), pair('雾', 'n'), pair('霾', 'g')]
seg_list = pseg.lcut(sentence)
seg_list = [i for i in seg_list if i.flag not in stopwords_list]
filtered_words_list = []
for seg in seg_list:
# print(seg)
if len(seg.word) <= 1:
continue
elif seg.flag == "eng":
if len(seg.word) <= 2:
continue
else:
filtered_words_list.append(seg.word)
elif seg.flag.startswith("n"):
filtered_words_list.append(seg.word)
elif seg.flag in ["x", "eng"]: # 是自定一个词语或者是英文单词
filtered_words_list.append(seg.word)
return filtered_words_list
for row in partition:
sentence = re.sub("<.*?>", "", row.sentence) # 替换掉标签数据
words = cut_sentence(sentence)
yield row.article_id, row.channel_id, words
- 训练模型,得到每个文章词的频率Counts结果
# 词语与词频统计
from pyspark.ml.feature import CountVectorizer
# 总词汇的大小,文本中必须出现的次数
cv = CountVectorizer(inputCol="words", outputCol="countFeatures", vocabSize=200*10000, minDF=1.0)
# 训练词频统计模型
cv_model = cv.fit(words_df)
cv_model.write().overwrite().save("hdfs://hadoop-master:9000/headlines/models/CV.model")
- 训练idf模型,保存
# 词语与词频统计
from pyspark.ml.feature import CountVectorizerModel
cv_model = CountVectorizerModel.load("hdfs://hadoop-master:9000/headlines/models/CV.model")
# 得出词频向量结果
cv_result = cv_model.transform(words_df)
# 训练IDF模型
from pyspark.ml.feature import IDF
idf = IDF(inputCol="countFeatures", outputCol="idfFeatures")
idfModel = idf.fit(cv_result)
idfModel.write().overwrite().save("hdfs://hadoop-master:9000/headlines/models/IDF.model")
得到了两个少量文章测试的模型,以这两个模型为例子查看结果,所有不同的词
cv_model.vocabulary
['this',
'pa',
'node',
'data',
'数据',
'let',
'keys',
'obj',
'组件',
'npm',
'child',
'节点',
'log',
'属性',
'key',
'console',
'value',
'var',
'return',
'div']
# 每个词的逆文档频率,在历史13万文章当中是固定的值,也作为后面计算TFIDF依据
idfModel.idf.toArray()[:20]
array([0.6061358 , 0. , 0.6061358 , 0.6061358 , 0.45198512,
0.78845736, 1.01160091, 1.01160091, 1.01160091, 0.78845736,
1.29928298, 1.70474809, 0.31845373, 1.01160091, 0.78845736,
0.45198512, 0.78845736, 0.78845736, 0.45198512, 1.70474809])
上传训练13万文章的模型
- 20篇文章,计算出代表20篇文章中N个词的IDF以及每个文档的词频,最终得到的是这20片文章的TFIDF
两个模型训练需要很久,所以在这里我们上传已经训练好的模型到指定路径
hadoop dfs -mkdir /headlines
hadoop dfs -mkdir /headlines/models/
hadoop dfs -put modelsbak/countVectorizerOfArticleWords.model/ /headlines/models/
hadoop dfs -put modelsbak/IDFOfArticleWords.model/ /headlines/models/
最终:

2.4.2.3 计算N篇文章数据的TFIDF值
- 步骤:
- 1、获取两个模型相关参数,将所有的13万文章中的关键字对应的idf值和索引保存
- 为什么要保存这些值?并且存入数据库当中?
- 2、模型计算得出N篇文章的TFIDF值选取TOPK,与IDF索引查询得到词
- 1、获取两个模型相关参数,将所有的13万文章中的关键字对应的idf值和索引保存
获取两个模型相关参数,将所有的关键字对应的idf值和索引保存
-
后续计算tfidf画像需要使用,避免放入内存中占用过多,持久化使用
-
建立表
CREATE TABLE idf_keywords_values(
keyword STRING comment "article_id",
idf DOUBLE comment "idf",
index INT comment "index");
然后读取13万参考文档所有词语与IDF值进行计算:
from pyspark.ml.feature import CountVectorizerModel
cv_model = CountVectorizerModel.load("hdfs://hadoop-master:9000/headlines/models/countVectorizerOfArticleWords.model")
from pyspark.ml.feature import IDFModel
idf_model = IDFModel.load("hdfs://hadoop-master:9000/headlines/models/IDFOfArticleWords.model")
进行计算保存
#keywords_list_with_idf = list(zip(cv_model.vocabulary, idf_model.idf.toArray()))
#def func(data):
# for index in range(len(data)):
# data[index] = list(data[index])
# data[index].append(index)
# data[index][1] = float(data[index][1])
#func(keywords_list_with_idf)
#sc = spark.sparkContext
#rdd = sc.parallelize(keywords_list_with_idf)
#df = rdd.toDF(["keywords", "idf", "index"])
# df.write.insertInto('idf_keywords_values')
存储结果:
hive> select * from idf_keywords_values limit 10;
OK
&# 1.417829594344155 0
pa 0.6651385256756351 1
ul 0.8070591229443697 2
代码 0.7368239176481552 3
方法 0.7506253985501485 4
数据 0.9375297590538404 5
return 1.1584986818528347 6
对象 1.2765716628665975 7
name 1.3833429138490618 8
this 1.6247297855214076 9
hive> desc idf_keywords_values;
OK
keyword string article_id
idf double idf
index int index
模型计算得出N篇文章的TFIDF值,IDF索引结果合并得到词
对于词频处理之后的结果进行计算
保存TFIDF的结果,在article数据库中创建表
CREATE TABLE tfidf_keywords_values(
article_id INT comment "article_id",
channel_id INT comment "channel_id",
keyword STRING comment "keyword",
tfidf DOUBLE comment "tfidf");
计算tfidf值进行存储
from pyspark.ml.feature import CountVectorizerModel
cv_model = CountVectorizerModel.load("hdfs://hadoop-master:9000/headlines/models/countVectorizerOfArticleWords.model")
from pyspark.ml.feature import IDFModel
idf_model = IDFModel.load("hdfs://hadoop-master:9000/headlines/models/IDFOfArticleWords.model")
cv_result = cv_model.transform(words_df)
tfidf_result = idf_model.transform(cv_result)
def func(partition):
TOPK = 20
for row in partition:
# 找到索引与IDF值并进行排序
_ = list(zip(row.idfFeatures.indices, row.idfFeatures.values))
_ = sorted(_, key=lambda x: x[1], reverse=True)
result = _[:TOPK]
for word_index, tfidf in result:
yield row.article_id, row.channel_id, int(word_index), round(float(tfidf), 4)
_keywordsByTFIDF = tfidf_result.rdd.mapPartitions(func).toDF(["article_id", "channel_id", "index", "tfidf"])
结果为:

如果要保存对应words读取idf_keywords_values表结果合并
# 利用结果索引与”idf_keywords_values“合并知道词
keywordsIndex = ktt.spark.sql("select keyword, index idx from idf_keywords_values")
# 利用结果索引与”idf_keywords_values“合并知道词
keywordsByTFIDF = _keywordsByTFIDF.join(keywordsIndex, keywordsIndex.idx == _keywordsByTFIDF.index).select(["article_id", "channel_id", "keyword", "tfidf"])
keywordsByTFIDF.write.insertInto("tfidf_keywords_values")
合并之后存储到TFIDF结果表中,便于后续读取处理
hive> desc tfidf_keywords_values;
OK
article_id int article_id
channel_id int channel_id
keyword string keyword
tfidf double tfidf
Time taken: 0.085 seconds, Fetched: 4 row(s)
hive> select * from tfidf_keywords_values limit 10;
OK
98319 17 var 20.6079
98323 17 var 7.4938
98326 17 var 104.9128
98344 17 var 5.6203
98359 17 var 69.3174
98360 17 var 9.3672
98392 17 var 14.9875
98393 17 var 155.4958
98406 17 var 11.2407
98419 17 var 59.9502
Time taken: 0.499 seconds, Fetched: 10 row(s)
2.4.3 TextRank计算
步骤:
- 1、TextRank存储结构
- 2、TextRank过滤计算
创建textrank_keywords_values表
CREATE TABLE textrank_keywords_values(
article_id INT comment "article_id",
channel_id INT comment "channel_id",
keyword STRING comment "keyword",
textrank DOUBLE comment "textrank");
进行词的处理与存储
# 计算textrank
textrank_keywords_df = article_dataframe.rdd.mapPartitions(textrank).toDF(
["article_id", "channel_id", "keyword", "textrank"])
# textrank_keywords_df.write.insertInto("textrank_keywords_values")
分词结果:
# 分词
def textrank(partition):
import os
import jieba
import jieba.analyse
import jieba.posseg as pseg
import codecs
abspath = "/root/words"
# 结巴加载用户词典
userDict_path = os.path.join(abspath, "ITKeywords.txt")
jieba.load_userdict(userDict_path)
# 停用词文本
stopwords_path = os.path.join(abspath, "stopwords.txt")
def get_stopwords_list():
"""返回stopwords列表"""
stopwords_list = [i.strip()
for i in codecs.open(stopwords_path).readlines()]
return stopwords_list
# 所有的停用词列表
stopwords_list = get_stopwords_list()
class TextRank(jieba.analyse.TextRank):
def __init__(self, window=20, word_min_len=2):
super(TextRank, self).__init__()
self.span = window # 窗口大小
self.word_min_len = word_min_len # 单词的最小长度
# 要保留的词性,根据jieba github ,具体参见https://github.com/baidu/lac
self.pos_filt = frozenset(
('n', 'x', 'eng', 'f', 's', 't', 'nr', 'ns', 'nt', "nw", "nz", "PER", "LOC", "ORG"))
def pairfilter(self, wp):
"""过滤条件,返回True或者False"""
if wp.flag == "eng":
if len(wp.word) <= 2:
return False
if wp.flag in self.pos_filt and len(wp.word.strip()) >= self.word_min_len \
and wp.word.lower() not in stopwords_list:
return True
# TextRank过滤窗口大小为5,单词最小为2
textrank_model = TextRank(window=5, word_min_len=2)
allowPOS = ('n', "x", 'eng', 'nr', 'ns', 'nt', "nw", "nz", "c")
for row in partition:
tags = textrank_model.textrank(row.sentence, topK=20, withWeight=True, allowPOS=allowPOS, withFlag=False)
for tag in tags:
yield row.article_id, row.channel_id, tag[0], tag[1]
最终存储为:
hive> select * from textrank_keywords_values limit 20;
OK
98319 17 var 20.6079
98323 17 var 7.4938
98326 17 var 104.9128
98344 17 var 5.6203
98359 17 var 69.3174
98360 17 var 9.3672
98392 17 var 14.9875
98393 17 var 155.4958
98406 17 var 11.2407
98419 17 var 59.9502
98442 17 var 18.7344
98445 17 var 37.4689
98512 17 var 29.9751
98544 17 var 5.6203
98545 17 var 22.4813
98548 17 var 71.1909
98599 17 var 11.2407
98609 17 var 18.7344
98642 17 var 67.444
98648 15 var 20.6079
Time taken: 0.344 seconds, Fetched: 20 row(s)
hive> desc textrank_keywords_values;
OK
article_id int article_id
channel_id int channel_id
keyword string keyword
textrank double textrank
2.5.3 文章画像结果
对文章进行计算画像
- 步骤:
- 1、加载IDF,保留关键词以及权重计算(TextRank * IDF)
- 2、合并关键词权重到字典结果
- 3、将tfidf和textrank共现的词作为主题词
- 4、将主题词表和关键词表进行合并,插入表
加载IDF,保留关键词以及权重计算(TextRank * IDF)
idf = ktt.spark.sql("select * from idf_keywords_values")
idf = idf.withColumnRenamed("keyword", "keyword1")
result = textrank_keywords_df.join(idf,textrank_keywords_df.keyword==idf.keyword1)
keywords_res = result.withColumn("weights", result.textrank * result.idf).select(["article_id", "channel_id", "keyword", "weights"])
合并关键词权重到字典结果
keywords_res.registerTempTable("temptable")
merge_keywords = ktt.spark.sql("select article_id, min(channel_id) channel_id, collect_list(keyword) keywords, collect_list(weights) weights from temptable group by article_id")
# 合并关键词权重合并成字典
def _func(row):
return row.article_id, row.channel_id, dict(zip(row.keywords, row.weights))
keywords_info = merge_keywords.rdd.map(_func).toDF(["article_id", "channel_id", "keywords"])
将tfidf和textrank共现的词作为主题词
topic_sql = """
select t.article_id article_id2, collect_set(t.keyword) topics from tfidf_keywords_values t
inner join
textrank_keywords_values r
where t.keyword=r.keyword
group by article_id2
"""
article_topics = ktt.spark.sql(topic_sql)
将主题词表和关键词表进行合并
article_profile = keywords_info.join(article_topics, keywords_info.article_id==article_topics.article_id2).select(["article_id", "channel_id", "keywords", "topics"])
# articleProfile.write.insertInto("article_profile")
结果显示
hive> select * from article_profile limit 1;
OK
26 17 {"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)2.5 离线增量文章画像计算
学习目标
- 目标
- 了解增量更新代码过程
- 应用
- 无
2.5.1 离线文章画像更新需求
文章画像,就是给每篇文章定义一些词。
- 关键词:TEXTRANK + IDF共同的词
-
主题词:TEXTRANK + ITFDF共同的词
-
更新文章时间:
1、toutiao 数据库中,news_article_content 与news_article_basic—>更新到article数据库中article_data表,方便操作
第一次:所有更新,后面增量每天的数据更新26日:1:00~2:00,2:00~3:00,左闭右开,一个小时更新一次
2、刚才新更新的文章,通过已有的idf计算出tfidf值以及hive 的textrank_keywords_values
3、更新hive的article_profile
2.5.2 定时更新文章设置
- 目的:通过Supervisor管理Apscheduler定时运行更新程序
- 步骤:
- 1、更新程序代码整理,并测试运行
- 2、Apscheduler设置定时运行时间,并启动日志添加
- 3、Supervisor进程管理
2.5.2.1 更新程序代码整理,并测试运行
注意在Pycharm中运行要设置环境:
PYTHONUNBUFFERED=1
JAVA_HOME=/root/bigdata/jdk
SPARK_HOME=/root/bigdata/spark
HADOOP_HOME=/root/bigdata/hadoop
PYSPARK_PYTHON=/root/anaconda3/envs/reco_sys/bin/python
PYSPARK_DRIVER_PYTHON=/root/anaconda3/envs/reco_sys/bin/python
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
from offline import SparkSessionBase
from datetime import datetime
from datetime import timedelta
import pyspark.sql.functions as F
import pyspark
import gc
class UpdateArticle(SparkSessionBase):
"""
更新文章画像
"""
SPARK_APP_NAME = "updateArticle"
ENABLE_HIVE_SUPPORT = True
SPARK_EXECUTOR_MEMORY = "7g"
def __init__(self):
self.spark = self._create_spark_session()
self.cv_path = "hdfs://hadoop-master:9000/headlines/models/countVectorizerOfArticleWords.model"
self.idf_path = "hdfs://hadoop-master:9000/headlines/models/IDFOfArticleWords.model"
def get_cv_model(self):
# 词语与词频统计
from pyspark.ml.feature import CountVectorizerModel
cv_model = CountVectorizerModel.load(self.cv_path)
return cv_model
def get_idf_model(self):
from pyspark.ml.feature import IDFModel
idf_model = IDFModel.load(self.idf_path)
return idf_model
@staticmethod
def compute_keywords_tfidf_topk(words_df, cv_model, idf_model):
"""保存tfidf值高的20个关键词
:param spark:
:param words_df:
:return:
"""
cv_result = cv_model.transform(words_df)
tfidf_result = idf_model.transform(cv_result)
# print("transform compelete")
# 取TOP-N的TFIDF值高的结果
def func(partition):
TOPK = 20
for row in partition:
_ = list(zip(row.idfFeatures.indices, row.idfFeatures.values))
_ = sorted(_, key=lambda x: x[1], reverse=True)
result = _[:TOPK]
# words_index = [int(i[0]) for i in result]
# yield row.article_id, row.channel_id, words_index
for word_index, tfidf in result:
yield row.article_id, row.channel_id, int(word_index), round(float(tfidf), 4)
_keywordsByTFIDF = tfidf_result.rdd.mapPartitions(func).toDF(["article_id", "channel_id", "index", "tfidf"])
return _keywordsByTFIDF
def merge_article_data(self):
"""
合并业务中增量更新的文章数据
:return:
"""
# 获取文章相关数据, 指定过去一个小时整点到整点的更新数据
# 如:26日:1:00~2:00,2:00~3:00,左闭右开
self.spark.sql("use toutiao")
_yester = datetime.today().replace(minute=0, second=0, microsecond=0)
start = datetime.strftime(_yester + timedelta(days=0, hours=-1, minutes=0), "%Y-%m-%d %H:%M:%S")
end = datetime.strftime(_yester, "%Y-%m-%d %H:%M:%S")
# 合并后保留:article_id、channel_id、channel_name、title、content
# +----------+----------+--------------------+--------------------+
# | article_id | channel_id | title | content |
# +----------+----------+--------------------+--------------------+
# | 141462 | 3 | test - 20190316 - 115123 | 今天天气不错,心情很美丽!!! |
basic_content = self.spark.sql(
"select a.article_id, a.channel_id, a.title, b.content from news_article_basic a "
"inner join news_article_content b on a.article_id=b.article_id where a.review_time >= '{}' "
"and a.review_time < '{}' and a.status = 2".format(start, end))
# 增加channel的名字,后面会使用
basic_content.registerTempTable("temparticle")
channel_basic_content = self.spark.sql(
"select t.*, n.channel_name from temparticle t left join news_channel n on t.channel_id=n.channel_id")
# 利用concat_ws方法,将多列数据合并为一个长文本内容(频道,标题以及内容合并)
self.spark.sql("use article")
sentence_df = channel_basic_content.select("article_id", "channel_id", "channel_name", "title", "content", \
F.concat_ws(
",",
channel_basic_content.channel_name,
channel_basic_content.title,
channel_basic_content.content
).alias("sentence")
)
del basic_content
del channel_basic_content
gc.collect()
sentence_df.write.insertInto("article_data")
return sentence_df
def generate_article_label(self, sentence_df):
"""
生成文章标签 tfidf, textrank
:param sentence_df: 增量的文章内容
:return:
"""
# 进行分词
words_df = sentence_df.rdd.mapPartitions(segmentation).toDF(["article_id", "channel_id", "words"])
cv_model = self.get_cv_model()
idf_model = self.get_idf_model()
# 1、保存所有的词的idf的值,利用idf中的词的标签索引
# 工具与业务隔离
_keywordsByTFIDF = UpdateArticle.compute_keywords_tfidf_topk(words_df, cv_model, idf_model)
keywordsIndex = self.spark.sql("select keyword, index idx from idf_keywords_values")
keywordsByTFIDF = _keywordsByTFIDF.join(keywordsIndex, keywordsIndex.idx == _keywordsByTFIDF.index).select(
["article_id", "channel_id", "keyword", "tfidf"])
keywordsByTFIDF.write.insertInto("tfidf_keywords_values")
del cv_model
del idf_model
del words_df
del _keywordsByTFIDF
gc.collect()
# 计算textrank
textrank_keywords_df = sentence_df.rdd.mapPartitions(textrank).toDF(
["article_id", "channel_id", "keyword", "textrank"])
textrank_keywords_df.write.insertInto("textrank_keywords_values")
return textrank_keywords_df, keywordsIndex
def get_article_profile(self, textrank, keywordsIndex):
"""
文章画像主题词建立
:param idf: 所有词的idf值
:param textrank: 每个文章的textrank值
:return: 返回建立号增量文章画像
"""
keywordsIndex = keywordsIndex.withColumnRenamed("keyword", "keyword1")
result = textrank.join(keywordsIndex, textrank.keyword == keywordsIndex.keyword1)
# 1、关键词(词,权重)
# 计算关键词权重
_articleKeywordsWeights = result.withColumn("weights", result.textrank * result.idf).select(
["article_id", "channel_id", "keyword", "weights"])
# 合并关键词权重到字典
_articleKeywordsWeights.registerTempTable("temptable")
articleKeywordsWeights = self.spark.sql(
"select article_id, min(channel_id) channel_id, collect_list(keyword) keyword_list, collect_list(weights) weights_list from temptable group by article_id")
def _func(row):
return row.article_id, row.channel_id, dict(zip(row.keyword_list, row.weights_list))
articleKeywords = articleKeywordsWeights.rdd.map(_func).toDF(["article_id", "channel_id", "keywords"])
# 2、主题词
# 将tfidf和textrank共现的词作为主题词
topic_sql = """
select t.article_id article_id2, collect_set(t.keyword) topics from tfidf_keywords_values t
inner join
textrank_keywords_values r
where t.keyword=r.keyword
group by article_id2
"""
articleTopics = self.spark.sql(topic_sql)
# 3、将主题词表和关键词表进行合并,插入表
articleProfile = articleKeywords.join(articleTopics,
articleKeywords.article_id == articleTopics.article_id2).select(
["article_id", "channel_id", "keywords", "topics"])
articleProfile.write.insertInto("article_profile")
del keywordsIndex
del _articleKeywordsWeights
del articleKeywords
del articleTopics
gc.collect()
return articleProfile
if __name__ == '__main__':
ua = UpdateArticle()
sentence_df = ua.merge_article_data()
if sentence_df.rdd.collect():
rank, idf = ua.generate_article_label(sentence_df)
articleProfile = ua.get_article_profile(rank, idf)
2.5.3 增量更新文章TFIDF与TextRank(作为测试代码,不往HIVE中存储)
在jupyter notebook中实现计算过程
- 目的:能够定时增量的更新新发表的文章
- 步骤:
- 合并新文章数据
- 利用现有CV和IDF模型计算新文章TFIDF存储,以及TextRank保存
- 利用新文章数据的
- 导入包
import os
# 配置spark driver和pyspark运行时,所使用的python解释器路径
PYSPARK_PYTHON = "/miniconda2/envs/reco_sys/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
import sys
BASE_DIR = os.path.dirname(os.getcwd())
sys.path.insert(0, os.path.join(BASE_DIR))
from datetime import datetime
from datetime import timedelta
import pyspark.sql.functions as F
from offline import SparkSessionBase
import pyspark
import gc
2.5.3.1 合并新文章数据
class UpdateArticle(SparkSessionBase):
"""
更新文章画像
"""
SPARK_APP_NAME = "updateArticle"
ENABLE_HIVE_SUPPORT = True
SPARK_EXECUTOR_MEMORY = "7g"
def __init__(self):
self.spark = self._create_spark_session()
- 增量合并文章
可以根据自己的业务制定符合现有阶段的更新计划,比如按照天,小时更新,
ua.spark.sql("use toutiao")
_yester = datetime.today().replace(minute=0, second=0, microsecond=0)
start = datetime.strftime(_yester + timedelta(days=0, hours=-1, minutes=0), "%Y-%m-%d %H:%M:%S")
end = datetime.strftime(_yester, "%Y-%m-%d %H:%M:%S")
选取指定时间段的新文章(测试时候,为了有数据出现,可以将偏移多一些天数,如days=-50)
注:确保news_article_basic与news_article_content是一致的。
# 合并后保留:article_id、channel_id、channel_name、title、content
# select * from news_article_basic where review_time > "2019-03-05";
# +----------+----------+--------------------+--------------------+
# | article_id | channel_id | title | content |
# +----------+----------+--------------------+--------------------+
# | 141462 | 3 | test - 20190316 - 115123 | 今天天气不错,心情很美丽!!! |
basic_content = ua.spark.sql(
"select a.article_id, a.channel_id, a.title, b.content from news_article_basic a "
"inner join news_article_content b on a.article_id=b.article_id where a.review_time >= '{}' "
"and a.review_time < '{}' and a.status = 2".format(start, end))
# 增加channel的名字,后面会使用
basic_content.registerTempTable("temparticle")
channel_basic_content = ua.spark.sql(
"select t.*, n.channel_name from temparticle t left join news_channel n on t.channel_id=n.channel_id")
# 利用concat_ws方法,将多列数据合并为一个长文本内容(频道,标题以及内容合并)
ua.spark.sql("use article")
sentence_df = channel_basic_content.select("article_id", "channel_id", "channel_name", "title", "content", \
F.concat_ws(
",",
channel_basic_content.channel_name,
channel_basic_content.title,
channel_basic_content.content
).alias("sentence")
)
del basic_content
del channel_basic_content
gc.collect()
# sentence_df.write.insertInto("article_data")
2.5.3.2 更新TFIDF
- 问题:计算出TFIDF,TF文档词频,IDF 逆文档频率(文档数量、某词出现的文档数量)已有N个文章中词的IDF会随着新增文章而动态变化,就会涉及TFIDF的增量计算。
- 解决办法可以在固定时间定时对所有文章数据进行全部计算CV和IDF的模型结果,替换模型即可
对新文章分词,读取模型
# 进行分词前面计算出的sentence_df
words_df = sentence_df.rdd.mapPartitions(segmentation).toDF(["article_id", "channel_id", "words"])
cv_model = get_cv_model()
idf_model = get_idf_model()
定义两个读取函数
def get_cv_model(self):
# 词语与词频统计
from pyspark.ml.feature import CountVectorizerModel
cv_model = CountVectorizerModel.load(cv_path)
return cv_model
def get_idf_model(self):
from pyspark.ml.feature import IDFModel
idf_model = IDFModel.load(idf_path)
return idf_model
def compute_keywords_tfidf_topk(words_df, cv_model, idf_model):
"""保存tfidf值高的20个关键词
:param spark:
:param words_df:
:return:
"""
cv_result = cv_model.transform(words_df)
tfidf_result = idf_model.transform(cv_result)
# print("transform compelete")
# 取TOP-N的TFIDF值高的结果
def func(partition):
TOPK = 20
for row in partition:
_ = list(zip(row.idfFeatures.indices, row.idfFeatures.values))
_ = sorted(_, key=lambda x: x[1], reverse=True)
result = _[:TOPK]
for word_index, tfidf in result:
yield row.article_id, row.channel_id, int(word_index), round(float(tfidf), 4)
_keywordsByTFIDF = tfidf_result.rdd.mapPartitions(func).toDF(["article_id", "channel_id", "index", "tfidf"])
return _keywordsByTFIDF
# 1、保存所有的词的idf的值,利用idf中的词的标签索引
# 工具与业务隔离
_keywordsByTFIDF = compute_keywords_tfidf_topk(words_df, cv_model, idf_model)
keywordsIndex = ua.spark.sql("select keyword, index idx from idf_keywords_values")
keywordsByTFIDF = _keywordsByTFIDF.join(keywordsIndex, keywordsIndex.idx == _keywordsByTFIDF.index).select(
["article_id", "channel_id", "keyword", "tfidf"])
# keywordsByTFIDF.write.insertInto("tfidf_keywords_values")
del cv_model
del idf_model
del words_df
del _keywordsByTFIDF
gc.collect()
# 计算textrank
textrank_keywords_df = sentence_df.rdd.mapPartitions(textrank).toDF(
["article_id", "channel_id", "keyword", "textrank"])
# textrank_keywords_df.write.insertInto("textrank_keywords_values")
前面这些得到textrank_keywords_df,接下来往后进行文章的画像更新
2.5.3.3 增量更新文章画像结果
对于新文章进行计算画像
- 步骤:
- 1、加载IDF,保留关键词以及权重计算(TextRank * IDF)
- 2、合并关键词权重到字典结果
- 3、将tfidf和textrank共现的词作为主题词
- 4、将主题词表和关键词表进行合并,插入表
加载IDF,保留关键词以及权重计算(TextRank * IDF)
idf = ua.spark.sql("select * from idf_keywords_values")
idf = idf.withColumnRenamed("keyword", "keyword1")
result = textrank_keywords_df.join(idf,textrank_keywords_df.keyword==idf.keyword1)
keywords_res = result.withColumn("weights", result.textrank * result.idf).select(["article_id", "channel_id", "keyword", "weights"])
合并关键词权重到字典结果
keywords_res.registerTempTable("temptable")
merge_keywords = ua.spark.sql("select article_id, min(channel_id) channel_id, collect_list(keyword) keywords, collect_list(weights) weights from temptable group by article_id")
# 合并关键词权重合并成字典
def _func(row):
return row.article_id, row.channel_id, dict(zip(row.keywords, row.weights))
keywords_info = merge_keywords.rdd.map(_func).toDF(["article_id", "channel_id", "keywords"])
将tfidf和textrank共现的词作为主题词
topic_sql = """
select t.article_id article_id2, collect_set(t.keyword) topics from tfidf_keywords_values t
inner join
textrank_keywords_values r
where t.keyword=r.keyword
group by article_id2
"""
articleTopics = ua.spark.sql(topic_sql)
将主题词表和关键词表进行合并。
article_profile = keywords_info.join(article_topics, keywords_info.article_id==article_topics.article_id2).select(["article_id", "channel_id", "keywords", "topics"])
# articleProfile.write.insertInto("article_profile")2.6 Apscheduler定时更新文章画像
学习目标
- 目标
- 知道Apscheduler定时更新工具使用
- 应用
- 应用Super进程管理与Apscheduler完成定时文章画像更新
2.6.1 Apscheduler使用
APScheduler:强大的任务调度工具,可以完成定时任务,周期任务等,它是跨平台的,用于取代Linux下的cron daemon或者Windows下的task scheduler。
下载
pip install APScheduler==3.5.3
基本概念:4个组件 triggers: 描述一个任务何时被触发,有按日期、按时间间隔、按cronjob描述式三种触发方式 job stores: 任务持久化仓库,默认保存任务在内存中,也可将任务保存都各种数据库中,任务中的数据序列化后保存到持久化数据库,从数据库加载后又反序列化。 executors: 执行任务模块,当任务完成时executors通知schedulers,schedulers收到后会发出一个适当的事件 schedulers: 任务调度器,控制器角色,通过它配置job stores和executors,添加、修改和删除任务。
简单使用
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.executors.pool import ProcessPoolExecutor
def test_job():
print("python")
# 创建scheduler,多进程执行
executors = {
'default': ProcessPoolExecutor(3)
}
scheduler = BlockingScheduler(executors=executors)
'''
#该示例代码生成了一个BlockingScheduler调度器,使用了默认的默认的任务存储MemoryJobStore,以及默认的执行器ThreadPoolExecutor,并且最大线程数为10。
'''
scheduler.add_job(test_job, trigger='interval', seconds=5)
'''
#该示例中的定时任务采用固定时间间隔(interval)的方式,每隔5秒钟执行一次。
#并且还为该任务设置了一个任务id
'''
scheduler.start()
在目录中新建scheduler目录用于启动各种定时任务
新建main.py文件编写Apscheduler代码,和update.py文件用于调用各种更新函数
from offline.update_article import UpdateArticle
def update_article_profile():
"""
更新文章画像
:return:
"""
ua = UpdateArticle()
sentence_df = ua.merge_article_data()
if sentence_df.rdd.collect():
text_rank_res = ua.generate_article_label(sentence_df)
article_profile = ua.get_article_profile(text_rank_res)
编写定时运行代码
import sys
import os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
sys.path.insert(0, os.path.join(BASE_DIR, 'reco_sys'))
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.executors.pool import ProcessPoolExecutor
from scheduler.update import update_article_profile
# 创建scheduler,多进程执行
executors = {
'default': ProcessPoolExecutor(3)
}
scheduler = BlockingScheduler(executors=executors)
# 添加定时更新任务更新文章画像,每隔一小时更新
scheduler.add_job(update_article_profile, trigger='interval', hours=1)
scheduler.start()
为了观察定期运行结果和异常,添加日志
创建setting目录,添加自定义日志文件logging.py创建
import logging
import logging.handlers
import os
logging_file_dir = '/root/logs/'
def create_logger():
"""
设置日志
:param app:
:return:
"""
# 离线处理更新打印日志
trace_file_handler = logging.FileHandler(
os.path.join(logging_file_dir, 'offline.log')
)
trace_file_handler.setFormatter(logging.Formatter('%(message)s'))
log_trace = logging.getLogger('offline')
log_trace.addHandler(trace_file_handler)
log_trace.setLevel(logging.INFO)
在Apscheduler的main文件中加入,运行时初始化一次
from settings import logging as lg
lg.create_logger()
并在需要打日志的文件中如update_article.py中加入:
import logging
logger = logging.getLogger('offline')
logger.info
logger.warn
2.6.2 Supervisor进程管理
在reco.conf中添加如下:
[program:offline]
environment=JAVA_HOME=/root/bigdata/jdk,SPARK_HOME=/root/bigdata/spark,HADOOP_HOME=/root/bigdata/hadoop,PYSPARK_PYTHON=/miniconda2/envs/reco_sys/bin/python,PYSPARK_DRIVER_PYTHON=/miniconda2/envs/reco_sys/bin/python
command=/miniconda2/envs/reco_sys/bin/python /root/toutiao_project/scheduler/main.py
directory=/root/toutiao_project/scheduler
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/offlinesuper.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true2.7 Word2Vec与文章相似度
学习目标
- 目标
- 知道文章向量计算方式
- 了解Word2Vec模型原理
- 知道文章相似度计算方式
- 应用
- 应用Spark完成文章相似度计算
2.7.1 文章相似度
-
在我们的黑马头条推荐中有很多地方需要推荐相似文章,包括首页频道可以推荐相似的文章,详情页猜你喜欢
-
需求
- 首页频道推荐:每个频道推荐的时候,会通过计算两两文章相似度,快速达到在线推荐的效果,比如用户点击文章,我们可以将离线计算好相似度的文章排序快速推荐给该用户。此方式也就可以解决冷启动的问题
- 方式:
- 1、计算两两文章TFIDF之间的相似度
- 2、计算两两文章的word2vec或者doc2vec向量相似度
我们采用第二种方式,实践中word2vec在大量数据下达到的效果更好。
2.7.2 Word2Vec模型介绍
2.7.2.2 为什么介绍Word2Vec
- 计算相似度:寻找相似词、或者用于文章之间的相似度
- 文本生成、机器翻译等
2.7.2.2 词向量是什么
定义:将文字通过一串数字向量表示
- 词的独热表示:One-hot Representation
- 采用稀疏方式 存储,简单易实现
- 灯泡:[0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0]、灯管:[0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0]
维度过大词汇鸿沟现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕”灯泡”和”灯管”这两个词是同义词也不行
- 词的分布式表示:Distributed representation
- 传统的独热表示( one-hot representation)仅仅将词符号化,不包含任何语义信息
- Distributed representation 最早由 Hinton在 1986 年提出。它是一种低维实数向量,这种向量一般长成这个样子: [0.792, −0.177, −0.107, 0.109, −0.542, …]
- 最大的贡献就是让相关或者相似的词,在距离上更接近了
2.7.2.3 词向量原理
- 统计语言模型: 统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性
例如:一个句子由w1,w2,w3,w4,w5,…….这些词组,使得P(w1,w2,w3,w4,w5……)概率大(可以从训练语料中得出)
-
N-Gram
- 语言是一种序列,词与词之间并不是相互独立
-
一元模型(unigram model):假设某个出现的概率与前面所有词无关
- P(s) = P(w1)P(w2)P(w3)…P(w4)
-
二元模型(bigram model):假设某个出现的概率与前面一个词相关
- P(s) = P(w1)P(w2|w1)P(w3|w2)…P(w_i|w_i-1)
- 三元模型(trigram model):假设某个出现的概率与前面两个词相关
- P(s) = P(w1)P(w2|w1)P(w3|w1,w2)…P(w_i|w_i-2,w_i-1)
注:目前使用较多的是三元模型,由于训练语料限制,无法追求更大的N,并且N越大导致计算量越来越大
2.7.2.4 词向量计算得出
- 通过一个三层神经网络得出,由约书亚.本吉奥(Yoshua Bengio)提出word2vec模型

- 通过窗口输入句子中的连续三个词,w1,w2,w3
- 输入网络中已是初始化的向量,如w1:[0,0,0,0,…..,0],值的向量长度自定义
- 三个词向量,输入到网络中,目标值为原句子的后面一个w4,通过onehot编码定义
- 网络训练,网络参数更新,自动调整w1,w2,w3的向量值,达到经过最后的softmax(多分类概率),输出预测概率,与目标值计算损失
2.7.3 文章词向量训练
- 目的:通过大量历史文章数据,训练词的词向量
由于文章数据过多,在开始设计的时候我们会分频道进行词向量训练,每个频道一个词向量模型。
- 步骤:
- 1、根据频道内容,读取不同频道号,获取相应频道数据并进行分词
- 3、Spark Word2Vec训练保存模型
根据频道内容,读取不同频道号,获取相应频道数据
在setting目录汇总创建一个default.py文件,保存默认一些配置,如频道
channelInfo = {
1: "html",
2: "开发者资讯",
3: "ios",
4: "c++",
5: "android",
6: "css",
7: "数据库",
8: "区块链",
9: "go",
10: "产品",
11: "后端",
12: "linux",
13: "人工智能",
14: "php",
15: "javascript",
16: "架构",
17: "前端",
18: "python",
19: "java",
20: "算法",
21: "面试",
22: "科技动态",
23: "js",
24: "设计",
25: "数码产品",
}
创建word2vec.ipynb文件,用来训练模型:
import os
import sys
# 如果当前代码文件运行测试需要加入修改路径,避免出现后导包问题
BASE_DIR = os.path.dirname(os.path.dirname(os.getcwd()))
sys.path.insert(0, os.path.join(BASE_DIR))
PYSPARK_PYTHON = "/miniconda2/envs/reco_sys/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
from offline import SparkSessionBase
from setting.default import channelInfo
from pyspark.ml.feature import Word2Vec
class TrainWord2VecModel(SparkSessionBase):
SPARK_APP_NAME = "Word2Vec"
SPARK_URL = "yarn"
ENABLE_HIVE_SUPPORT = True
def __init__(self):
self.spark = self._create_spark_session()
w2v = TrainWord2VecModel()
获取数据并分词处理,注意分词函数导入(这里只选取了18号频道部分数据进行测试)
# 这里训练一个频道模型演示即可
w2v.spark.sql("use article")
article = w2v.spark.sql("select * from article_data where channel_id=18 limit 2")
words_df = article.rdd.mapPartitions(segmentation).toDF(['article_id', 'channel_id', 'words'])
Spark Word2Vec训练保存模型
- 模块:from pyspark.ml.feature import Word2Vec
- API:class pyspark.ml.feature.Word2Vec(vectorSize=100, minCount=5, numPartitions=1, stepSize=0.025, maxIter=1, seed=None, inputCol=None, outputCol=None, windowSize=5, maxSentenceLength=1000)
- vectorSize=100: 词向量长度
- minCount:过滤次数小于默认5次的词
- windowSize=5:训练时候的窗口大小
- inputCol=None:输入列名
- outputCol=None:输出列名
new_word2Vec = Word2Vec(vectorSize=100, inputCol="words", outputCol="model", minCount=3)
new_model = new_word2Vec.fit(words_df)
new_model.save("hdfs://hadoop-master:9000/headlines/models/test.word2vec")
上传历史数据训练的模型
在本地准备了训练一段时间每个频道的模型
hadoop dfs -put ./word2vec_model /headlines/models/

2.7.4 增量更新-文章向量计算
有了词向量之后,我们就可以得到一篇文章的向量了,为了后面快速使用文章的向量,我们会将每个频道所有的文章向量保存起来。
- 目的:保存所有历史训练的文章向量
- 步骤:
- 1、加载某个频道模型,得到每个词的向量
- 2、获取频道的文章画像,得到文章画像的关键词(接着之前增量更新的文章article_profile)
- 3、计算得到文章每个词的向量
- 4、计算得到文章的平均词向量即文章的向量
加载某个频道模型,得到每个词的向量
from pyspark.ml.feature import Word2VecModel
channel_id = 18
channel = "python"
wv_model = Word2VecModel.load(
"hdfs://hadoop-master:9000/headlines/models/word2vec_model/channel_%d_%s.word2vec" % (channel_id, channel))
vectors = wv_model.getVectors()
获取新增的文章画像,得到文章画像的关键词
可以选取小部分数据来进行测试
# 选出新增的文章的画像做测试,上节计算的画像中有不同频道的,我们选取Python频道的进行计算测试
profile = articleProfile.filter('channel_id = {}'.format(channel_id))
profile.registerTempTable("incremental")
articleKeywordsWeights = ua.spark.sql(
"select article_id, channel_id, keyword, weight from incremental LATERAL VIEW explode(keywords) AS keyword, weight")
_article_profile = articleKeywordsWeights.join(vectors, vectors.word==articleKeywordsWeights.keyword, "inner")
计算得到文章每个词的向量
- 这里用词的权重 * 词的向量 = weights x vector=new_vector
articleKeywordVectors = _article_profile.rdd.map(lambda row: (row.article_id, row.channel_id, row.keyword, row.weight * row.vector)).toDF(["article_id", "channel_id", "keyword", "weightingVector"])
计算得到文章的平均词向量即文章的向量
def avg(row):
x = 0
for v in row.vectors:
x += v
# 将平均向量作为article的向量
return row.article_id, row.channel_id, x / len(row.vectors)
articleKeywordVectors.registerTempTable("tempTable")
articleVector = ua.spark.sql(
"select article_id, min(channel_id) channel_id, collect_set(weightingVector) vectors from tempTable group by article_id").rdd.map(
avg).toDF(["article_id", "channel_id", "articleVector"])
对计算出的”articleVector“列进行处理,该列为Vector类型,不能直接存入HIVE,HIVE不支持该数据类型
def toArray(row):
return row.article_id, row.channel_id, [float(i) for i in row.articleVector.toArray()]
articleVector = articleVector.rdd.map(toArray).toDF(['article_id', 'channel_id', 'articleVector'])
最终计算出这个18号Python频道的所有文章向量,保存到固定的表当中
- 创建文章向量表
CREATE TABLE article_vector(
article_id INT comment "article_id",
channel_id INT comment "channel_id",
articlevector ARRAY comment "keyword");
保存数据到HIVE
# articleVector.write.insertInto("article_vector")
上传计算好的历史文章向量
hadoop dfs -put ./article_vector /user/hive/warehouse/article.db/
2.7.5 文章相似度计算
-
目的:计算每个频道两两文章的相似度,并保存
-
分析问题:
- 1、是否需要某频道计算所有文章两两相似度?
- 2、相似度结果数值如何保存?
2.7.4.1 问题1
我们在推荐相似文章的时候,其实并不会用到所有文章,也就是TOPK个相似文章会被推荐出去,经过排序之后的结果。如果我们的设备资源、时间也真充足的话,可以进行某频道全量所有的两两相似度计算。但是事实当文章量达到千万级别或者上亿级别,特征也会上亿级别,计算量就会很大。一下有两种类型解决方案
每个频道的文章先进行聚类
可以对每个频道内N个文章聚成M类别,那么类别数越多每个类别的文章数量越少。如下pyspark代码
bkmeans = BisectingKMeans(k=100, minDivisibleClusterSize=50, featuresCol="articleVector", predictionCol='group')
bkmeans_model = bkmeans.fit(articleVector)
bkmeans_model.save(
"hdfs://hadoop-master:9000/headlines/models/articleBisKmeans/channel_%d_%s.bkmeans" % (channel_id, channel))
但是对于每个频道聚成多少类别这个M是超参数,并且聚类算法的时间复杂度并不小,当然可以使用一些优化的聚类算法二分、层次聚类。
局部敏感哈希LSH(Locality Sensitive Hashing)
从海量数据库中寻找到与查询数据相似的数据是一个很关键的问题。比如在图片检索领域,需要找到与查询图像相似的图,文本搜索领域都会遇到。如果是低维的小数据集,我们通过线性查找(Linear Search)就可以容易解决,但如果是对一个海量的高维数据集采用线性查找匹配的话,会非常耗时,因此,为了解决该问题,我们需要采用一些类似索引的技术来加快查找过程,通常这类技术称为最近邻查找(Nearest Neighbor,AN),例如K-d tree;或近似最近邻查找(Approximate Nearest Neighbor, ANN),例如K-d tree with BBF, Randomized Kd-trees, Hierarchical K-means Tree。而LSH是ANN中的一类方法。
- 基本思想:LSH算法基于一个假设,如果两个文本在原有的数据空间是相似的,那么分别经过哈希函数转换以后的它们也具有很高的相似度
经常使用的哈希函数,冲突总是难以避免。LSH却依赖于冲突,在解决NNS(Nearest neighbor search )时,我们期望:

- 离得越近的对象,发生冲突的概率越高
- 离得越远的对象,发生冲突的概率越低
总结:那么我们在该数据集合中进行近邻查找就变得容易了,我们只需要将查询数据进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行线性匹配即可查找到与查询数据相邻的数据。
落入相同的桶内的哈希函数需要满足以下两个条件:
- 如果d(O1,O2)<r1,那么Pr[h(O1)=h(O2)] ≥ p1
- 如果d(O1,O2)>r2,那么Pr[h(O1)=h(O2)] ≤ p2
LSH在线查找时间由两个部分组成:
(1)通过LSH hash functions计算hash值(桶号)的时间;
(2)将查询数据与桶内的数据进行比较计算的时间。第(2)部分的耗时就从O(N)变成了O(logN)或O(1)(取决于采用的索引方法)。
注:LSH并不能保证一定能够查找到与query data point最相邻的数据,而是减少需要匹配的数据点个数的同时保证查找到最近邻的数据点的概率很大。
实际中常见的LSH
LSH详细过程
mini hashing
假设我们有如下四个文档D1,D2,D3,D4D1,D2,D3,D4的集合情况,每个文档有相应的词项,用{w1,w2,..w7}{w1,w2,..w7}表示。若某个文档存在这个词项,则标为1,否则标为0。

过程
1、Minhash的定义为:** 特征矩阵按行进行一个随机的排列后,第一个列值为1的行的行号。

- 重复上述操作
- 矩阵按行进行多次置换,每次置换之后统计每一列(对应的是每个文档)第一个不为0位置的行号,这样每次统计的结果能构成一个与文档数等大的向量,我们称之为签名向量。
- (如果两个文档足够相似,也就是说这两个文档中有很多元素是共有的,这样置换出来的签名向量,如果原来其中有一些文档的相似度很高,那么这些文档所对应的签名向量的相应的元素值相同的概率也很高。)
初始时的矩阵叫做input matrix,由m个文档m,n个词项组成.而把由t次置换后得到的一个t×mt×m矩阵叫做signature matrix。

2、对Signature每行分割成若干brand(一个brand若干行),每个band计算hash值(hash函数可以md5,sha1任意),我们需要将这些hash值做处理,使之成为事先设定好的hash桶的tag,然后把这些band“扔”进hash桶中。

两个文档一共存在b个band,这b个band都不相同的概率是,r和b影响对应的概率.
概率1−(1−s^r)^b就是最终两个文档被映射到同一个hash bucket中的概率。我们发现,这样一来,实际上可以通过控制参数r,b值来控制两个文档被映射到同一个哈希桶的概率。而且效果非常好。比如,令b=20,r=5
s∈[0,1]是这两个文档的相似度,等于给的文当前提条件下:
- 当s=0.8时,两个文档被映射到同一个哈希桶的概率是
- Pr(LSH(O1)=LSH(O2))=1−(1−0.85)5=0.9996439421094793
- 当s=0.2时,两个文档被映射到同一个哈希桶的概率是:
- Pr(LSH(O1)=LSH(O2))=1−(1−0.25)5=0.0063805813047682
参数环境下的概率图:

- 相似度高于某个值的时候,到同一个桶概率会变得非常大,并且快速靠近1
- 当相似度低于某个值的时候,概率会变得非常小,并且快速靠近0
Random Projection
Random Projection是一种随机算法.随机投影的算法有很多,如PCA、Gaussian random projection - 高斯随机投影。
随机桶投影是用于欧几里德距离的 LSH family。其LSH family将x特征向量映射到随机单位矢量v,并将映射结果分为哈希桶中。哈希表中的每个位置表示一个哈希桶。
2.7.4.2 相似度计算
- 目的:计算18号Python频道的文章之间相似度
- 步骤:
- 1、读取数据,进行类型处理(数组到Vector)
- 2、BRP进行FIT
读取数据,进行类型处理(数组到Vector)
from pyspark.ml.linalg import Vectors
# 选取部分数据做测试
article_vector = w2v.spark.sql("select article_id, articlevector from article_vector where channel_id=18 limit 10")
train = articlevector.select(['article_id', 'articleVector'])
def _array_to_vector(row):
return row.article_id, Vectors.dense(row.articleVector)
train = train.rdd.map(_array_to_vector).toDF(['article_id', 'articleVector'])
BRP进行FIT
- class pyspark.ml.feature.BucketedRandomProjectionLSH(inputCol=None, outputCol=None, seed=None, numHashTables=1, bucketLength=None)
- inputCol=None:输入特征列
- outputCol=None:输出特征列
- numHashTables=1:哈希表数量,几个hash function对数据进行hash操作
- bucketLength=None:桶的数量,值越大相同数据进入到同一个桶的概率越高
- method:
- approxSimilarityJoin(df1, df2, 2.0, distCol='EuclideanDistance')
- 计算df1每个文章相似的df2数据集的数据
from pyspark.ml.feature import BucketedRandomProjectionLSH
brp = BucketedRandomProjectionLSH(inputCol='articleVector', outputCol='hashes', numHashTables=4.0, bucketLength=10.0)
model = brp.fit(train)
计算相似的文章以及相似度
similar = model.approxSimilarityJoin(test, train, 2.0, distCol='EuclideanDistance')
similar.sort(['EuclideanDistance']).show()
2.7.4.3 问题3
对于计算出来的相似度,是要在推荐的时候使用。那么我们所知的是,HIVE只适合在离线分析时候使用,因为运行速度慢,所以只能将相似度存储到HBASE当中
- hbase
2.7.5 文章相似度存储
-
目的:将所有文章对应相似度文章及其相似度保存
-
步骤:
- 调用foreachPartition
- foreachPartition不同于map和mapPartition,主要用于离线分析之后的数据落地,如果想要返回新的一个数据DF,就使用map后者。
- 调用foreachPartition
我们需要建立一个HBase存储文章相似度的表
create 'article_similar', 'similar'
# 存储格式如下:key:为article_id, 'similar:article_id', 结果为相似度
put 'article_similar', '1', 'similar:1', 0.2
put 'article_similar', '1', 'similar:2', 0.34
put 'article_similar', '1', 'similar:3', 0.267
put 'article_similar', '1', 'similar:4', 0.56
put 'article_similar', '1', 'similar:5', 0.7
put 'article_similar', '1', 'similar:6', 0.819
put 'article_similar', '1', 'similar:8', 0.28
定义保存HBASE函数,确保我们的happybase连接hbase启动成功,Thrift服务打开。hbase集群出现退出等问题常见原因,配置文件hadoop目录,地址等,还有
- ntpdate 0.cn.pool.ntp.org或者ntpdate ntp1.aliyun.com
- hbase-daemon.sh start thrift
def save_hbase(partition):
import happybase
pool = happybase.ConnectionPool(size=3, host='hadoop-master')
with pool.connection() as conn:
# 建议表的连接
table = conn.table('article_similar')
for row in partition:
if row.datasetA.article_id == row.datasetB.article_id:
pass
else:
table.put(str(row.datasetA.article_id).encode(),
{"similar:{}".format(row.datasetB.article_id).encode(): b'%0.4f' % (row.EuclideanDistance)})
# 手动关闭所有的连接
conn.close()
similar.foreachPartition(save_hbase)2.8 文章相似度增量更新
学习目标
- 目标
- 知道文章向量计算方式
- 了解Word2Vec模型原理
- 知道文章相似度计算方式
- 应用
- 应用Spark完成文章相似度计算
2.8.1 增量更新需求
每天、每小时都会有大量的新文章过来,当后端审核通过一篇文章之后,我们推荐给用户后,一旦发生点击行为了,就会有相应相似文章计算需求。没有选择去在线计算中处理,新文章来了之后立即推荐召回给用用户,这样增加新文章推荐曝光的比例,达到一定速度的曝光。在线需要用用到离线仓库中部分数据,所以速度会受影响。
- 设计:
- 按照之前增量更新文章画像那样的频率,按小时更新增量文章的相似文章
- 如何更新:
- 批量新文章,需要与历史数据进行相似度计算
2.8.2 增量更新文章向量与相似度
- 目标:对每次新增的文章,计算完画像后,计算向量,在进行与历史文章相似度计算
- 步骤:
- 1、新文章数据,按照频道去计算文章所在频道的相似度
- 2、求出新文章向量,保存
- 3、BucketedRandomProjectionLSH计算相似度
完整代码:
def compute_article_similar(self, articleProfile):
"""
计算增量文章与历史文章的相似度 word2vec
:return:
"""
# 得到要更新的新文章通道类别(不采用)
# all_channel = set(articleProfile.rdd.map(lambda x: x.channel_id).collect())
def avg(row):
x = 0
for v in row.vectors:
x += v
# 将平均向量作为article的向量
return row.article_id, row.channel_id, x / len(row.vectors)
for channel_id, channel_name in CHANNEL_INFO.items():
profile = articleProfile.filter('channel_id = {}'.format(channel_id))
wv_model = Word2VecModel.load(
"hdfs://hadoop-master:9000/headlines/models/channel_%d_%s.word2vec" % (channel_id, channel_name))
vectors = wv_model.getVectors()
# 计算向量
profile.registerTempTable("incremental")
articleKeywordsWeights = ua.spark.sql(
"select article_id, channel_id, keyword, weight from incremental LATERAL VIEW explode(keywords) AS keyword, weight where channel_id=%d" % channel_id)
articleKeywordsWeightsAndVectors = articleKeywordsWeights.join(vectors,
vectors.word == articleKeywordsWeights.keyword, "inner")
articleKeywordVectors = articleKeywordsWeightsAndVectors.rdd.map(
lambda r: (r.article_id, r.channel_id, r.keyword, r.weight * r.vector)).toDF(
["article_id", "channel_id", "keyword", "weightingVector"])
articleKeywordVectors.registerTempTable("tempTable")
articleVector = self.spark.sql(
"select article_id, min(channel_id) channel_id, collect_set(weightingVector) vectors from tempTable group by article_id").rdd.map(
avg).toDF(["article_id", "channel_id", "articleVector"])
# 写入数据库
def toArray(row):
return row.article_id, row.channel_id, [float(i) for i in row.articleVector.toArray()]
articleVector = articleVector.rdd.map(toArray).toDF(['article_id', 'channel_id', 'articleVector'])
articleVector.write.insertInto("article_vector")
import gc
del wv_model
del vectors
del articleKeywordsWeights
del articleKeywordsWeightsAndVectors
del articleKeywordVectors
gc.collect()
# 得到历史数据, 转换成固定格式使用LSH进行求相似
train = self.spark.sql("select * from article_vector where channel_id=%d" % channel_id)
def _array_to_vector(row):
return row.article_id, Vectors.dense(row.articleVector)
train = train.rdd.map(_array_to_vector).toDF(['article_id', 'articleVector'])
test = articleVector.rdd.map(_array_to_vector).toDF(['article_id', 'articleVector'])
brp = BucketedRandomProjectionLSH(inputCol='articleVector', outputCol='hashes', seed=12345,
bucketLength=1.0)
model = brp.fit(train)
similar = model.approxSimilarityJoin(test, train, 2.0, distCol='EuclideanDistance')
def save_hbase(partition):
import happybase
for row in partition:
pool = happybase.ConnectionPool(size=3, host='hadoop-master')
# article_similar article_id similar:article_id sim
with pool.connection() as conn:
table = connection.table("article_similar")
for row in partition:
if row.datasetA.article_id == row.datasetB.article_id:
pass
else:
table.put(str(row.datasetA.article_id).encode(),
{b"similar:%d" % row.datasetB.article_id: b"%0.4f" % row.EuclideanDistance})
conn.close()
similar.foreachPartition(save_hbase)
添加函数到update_article.py文件中,修改update更新代码
ua = UpdateArticle()
sentence_df = ua.merge_article_data()
if sentence_df.rdd.collect():
rank, idf = ua.generate_article_label(sentence_df)
articleProfile = ua.get_article_profile(rank, idf)
ua.compute_article_similar(articleProfile)