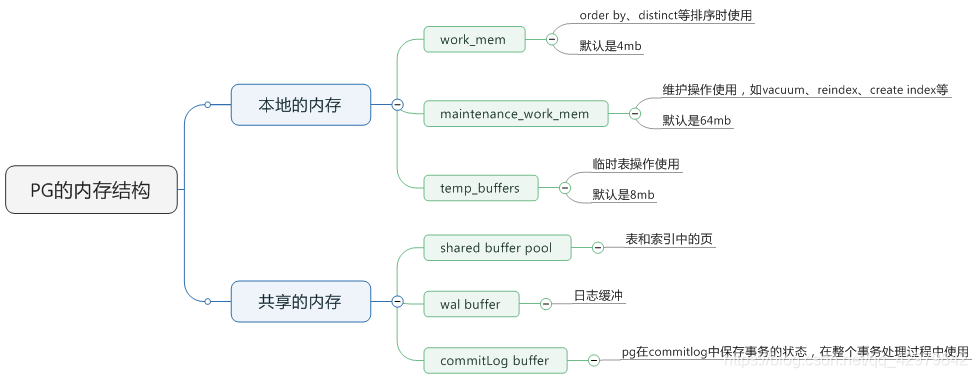
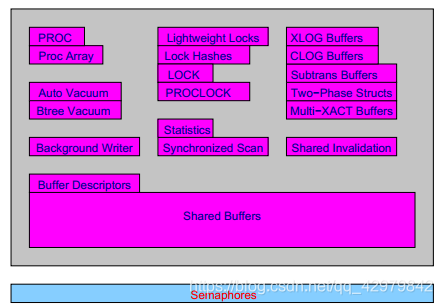
一、共享内存
PostgreSQL在启动后会生成一块共享内存,共享内存包括数据块缓冲区、WAL日志缓冲区以及CLOG缓冲区。除此之外,共享内存还包含进程信息、统计信息、锁信息、日志信息等。
相关参数
shared_buffers:
设置数据库服务器将使用的共享内存缓冲区大小,通常都会把此值设置的大一些,这样可以改进性能。一般设置为物理内存的 25%,若把 shared_buffers 设置的更大,如超过物理内存的 40%,就会发现缓冲的效果并不明显了,这是因为 PostgreSQL 是运行文件系统之上的,若文件系统也有缓存,将导致双缓存过多,造成负面影响。
二、本地内存
后台服务进程除了访问共享内存外还需要申请一些本地内存来保存一些临时数据。主要分为临时缓冲区、work_mem、维护操作内存缓冲区。相关变量如下:
temp_buffers:
设置每个数据库会话使用的临时缓冲区的最大数目。此本地缓冲区只用于访问临时表。临时缓冲区是在某个连接会话的服务进程中分配的,属于本地内存。临时缓冲区的大小也是按数据块大小分配的,默认是 1000,对于 8K 的数据块大小为 8MB。
work_mem:
声明内部排序操作和 Hash 表在开始使用临时磁盘文件之前可使用的内存数目。这个内存也是本地内存,默认是 1MB。请注意对于复杂的查询,可能会同时并发运行好几个排序或散列(hash)操作;每个排序或散列操作都会分配这个参数声明的内存来存储中间数据,只有存不下才会使用临时文件。同样,好几个正在运行的会话可能会同时进行排序操作,因此使用的总内存量可能是 work_mem 的好几倍。 ORDER BY、DISTINCT 和 MERGE JOINS 都要用到排序操作。Hash 表在以 Hash join、Hash 为基础的聚集、以 Hash 为基础的 IN 子查询处理中都要用到。
maintenance_work_mem:
声明在维护性操作(比如 CACUUM、CREATE INDEX、ALTER TABLE ADD FOREIGN KEY等)中使用的最大内存数。默认是 16 MB。在一个数据库会话里,只有一个这样的操作可以执行行,并且一个数据库实例通常不会有太多这样的工作并发执行,把这个数值设置得比 work_mem 大一些通常是合适的。更大的设置可以提高上述操作的速度。