内存泄漏检测工具
还有其他的专门进行内存泄漏检测的工具。JRockit Memory Leak Detector可以用来查看内存泄漏,并可以更深入地查出泄漏的根源。这个强大的工具是紧密集成到JRockit JVM中的,其开销非常小,对虚拟机的堆的访问也很容易。
专业工具的优点
一旦知道确实发生了内存泄漏,就需要更专业的工具来查明为什么会发生泄漏。JVM自己是不会告诉您的。这些专业工具从JVM获得内存系统信息的方法基本上有两种:JVMTI和字节码技术(byte code instrumentation)。Java虚拟机工具接口(Java Virtual Machine Tools Interface,JVMTI)及其前身Java虚拟机监视程序接口(Java Virtual Machine Profiling Interface,JVMPI)是外部工具与JVM通信并从JVM收集信息的标准化接口。字节码技术是指使用探测器处理字节码以获得工具所需的信息的技术。
对于内存泄漏检测来说,这两种技术有两个缺点,这使它们不太适合用于生产环境。首先,它们在内存占用和性能降低方面的开销不可忽略。有关堆使用量的信息必须以某种方式从JVM导出,并收集到工具中进行处理。这意味着要为工具分配内存。信息的导出也影响了JVM的性能。例如,当收集信息时,垃圾收集器将运行得比较慢。另外一个缺点是需要始终将工具连在JVM上。这是不可能的:将工具连在一个已经启动的JVM上,进行分析,断开工具,并保持JVM运行。
因为JRockit Memory Leak Detector是集成到JVM中的,就没有这两个缺点了。首先,许多处理和分析工作是在JVM内部进行的,所以没有必要转换或重新创建任何数据。处理还可以背负(piggyback)在垃圾收集器本身上而进行,这意味着提高了速度。其次,只要JVM是使用-Xmanagement选项(允许通过远程JMX接口监控和管理JVM)启动的,Memory Leak Detector就可以与运行中的JVM进行连接或断开。当该工具断开时,没有任何东西遗留在JVM中,JVM又将以全速运行代码,正如工具连接之前一样。
趋势分析
让我们深入地研究一下该工具以及它是如何用来跟踪内存泄漏的。在知道发生内存泄漏之后,第一步是要弄清楚泄漏了什么数据–哪个类的对象引起了泄漏?JRockit Memory Leak Detector是通过在每次垃圾收集时计算每个类的现有对象的数目来实现这一步的。如果特定类的对象数目随时间而增长(“增长率”),就可能发生了内存泄漏。
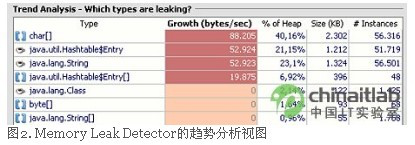
因为泄漏可能像细流一样非常小,所以趋势分析必须运行很长一段时间。在短时间内,可能会发生一些类的局部增长,而之后它们又会跌落。但是趋势分析的开销很小(最大开销也不过是在每次垃圾收集时将数据包由JRockit发送到Memory Leak Detector)。开销不应该成为任何系统的问题——即使是一个全速运行的生产中的系统。
起初数目会跳跃不停,但是一段时间之后它们就会稳定下来,并显示出哪些类的数目在增长。
找出根本原因

有时候知道是哪些类的对象在泄漏就足以说明问题了。这些类可能只用于代码中的非常有限的部分,对代码进行一次快速检查就可以显示出问题所在。遗憾地是,很有可能只有这类信息还并不够。例如,常见到泄漏出在类java.lang.String的对象上,但是因为字符串在整个程序中都使用,所以这并没有多大帮助。
我们想知道的是,另外还有哪些对象与泄漏对象关联?在本例中是String。为什么泄漏的对象还存在?哪些对象保留了对这些对象的引用?但是能列出的所有保留对String的引用的对象将会非常多,以至于没有什么实际用处。为了限制数据的数量,可以将数据按类分组,以便可以看出其他哪些对象的类与泄漏对象(String)关联。例如,String在Hashtable中是很常见的,因此我们可能会看到与String关联的Hashtable数据项对象。由Hashtable数据项倒推,我们最终可以找到与这些数据项有关的Hashtable对象以及String(如图3所示)。
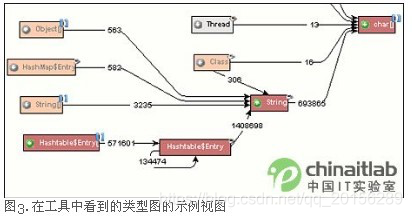
倒推
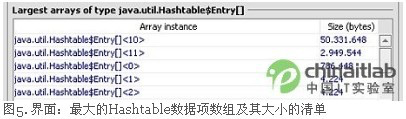
因为我们仍然是以类的对象而不是单独的对象来看待对象,所以我们不知道是哪个Hashtable在泄漏。如果我们可以弄清楚系统中所有的Hashtable都有多大,我们就可以假定最大的Hashtable就是正在泄漏的那一个(因为随着时间的流逝它会累积泄漏而增长得相当大)。因此,一份有关所有Hashtable对象以及它们引用了多少数据的列表,将会帮助我们指出造成泄漏的确切Hashtabl。
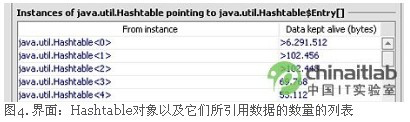
对对象引用数据数目的计算开销非常大(需要以该对象作为根遍历引用图),如果必须对许多对象都这么做,将会花很多时间。如果了解一点Hashtable的内部实现原理就可以找到一条捷径。Hashtable的内部有一个Hashtable数据项的数组。该数组随着Hashtable中对象数目的增长而增长。因此,为找出最大的Hashtable,我们只需找出引用Hashtable数据项的最大数组。这样要快很多。
更进一步
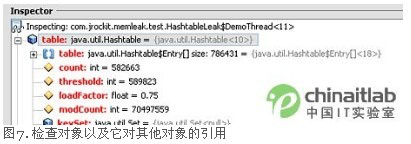
当找到发生泄漏的Hashtable实例时,我们可以看到其他哪些实例在引用该Hashtable,并倒推回去看看是哪个Hashtable在泄漏。

例如,该Hashtable可能是由MyServer类型的对象在名为activeSessions的字段中引用的。这种信息通常就足以查找源代码以定位问题所在了。
找出分配位置
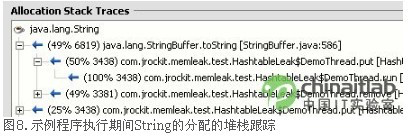
当跟踪内存泄漏问题时,查看对象分配到哪里是很有用的。只知道它们如何与其他对象相关联(即哪些对象引用了它们)是不够的,关于它们在何处创建的信息也很有用。当然了,您并不想创建应用程序的辅助构件,以打印每次分配的堆栈跟踪(stack trace)。您也不想仅仅为了跟踪内存泄漏而在运行应用程序时将一个分析程序连接到生产环境中。
借助于JRockit Memory Leak Detector,应用程序中的代码可以在分配时进行动态添加,以创建堆栈跟踪。这些堆栈跟踪可以在工具中进行累积和分析。只要不启用就不会因该功能而产生成本,这意味着随时可以进行分配跟踪。当请求分配跟踪时,JRockit 编译器动态插入代码以监控分配,但是只针对所请求的特定类。更好的是,在进行数据分析时,添加的代码全部被移除,代码中没有留下任何会引起应用程序性能降低的更改。