一、网络协议概述


1.1、网络分层的目的是什么
网络为什么要分层呢?因为不同层直接有不同的沟通方式,这个叫做协议。

1.2、IP地址
IP地址时一个网卡在网络世界的通讯地址,相当于现实世界的门牌号。
假设IP地址是10.100.122.2,这个IP地址分层4个部分,用“."分隔,每个部分是一个整数(8 bit),所以一个IP地址是32位,但这样的IP地址很快就bu够用了,因为当初没想到现在有这么多计算机。于是就有了IPV6,也就是fe80::f816:3eff:fec7:7975/64,这个有128位,现在看来是够用了。
本来32位IP地址就不够用,而且还被分成了5类,现在看真实太奢侈了:

对于A,B,C三类,分两部分,前一部分是网络号,后一部分是主机号。
下面的表格,详细解释了A,B,C三类地址能包含的主机的数量:
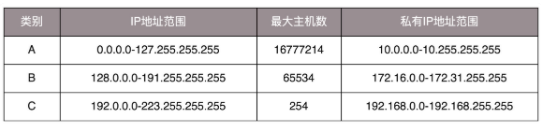
可以看到,C类包含的主机数只有254个,现在看来一个网吧都不够。而B类地址包含的主机数又太多了,6万多台机器放在一个网络下面,一般其他达不到这个规模,闲着就是浪费。
于是有了一个这种的方式,叫做”无类型域间选路“,简称CIDR:这种方式打破了原来设计的几类地址的做法,将32位IP地址一分为二,前面是网络后,后面是主机号。从哪里分呢?10.100.122.2/24,IP地址后面有个斜杠,斜杠后有个24,这种形式就是CIDR。后面24表示在32位中,前24位是网络后,后面8位是主机号。
伴随着CIDR存在的,一个是广播地址,10.100.122.255,如果发送到这个地址,那么所有10.100.122网络里的所有机器都可以收到。一个是子网掩码255.255.255.0。
将子网掩码与IP地址进行AND计算,前面三个255,转成二进制都是1,1和任意数取AND,都是原来的数,因此前三个数不变,为10.100.122。后面一个0,转成二进制是0,0和任意数AND,都是0,因而最后一个数变为0,合起来就是10.100.122.0,这就是网络号:将子网掩码和IP地址按位计算AND,得到的就是网络号。
1.2.1、公有IP地址和私有IP地址
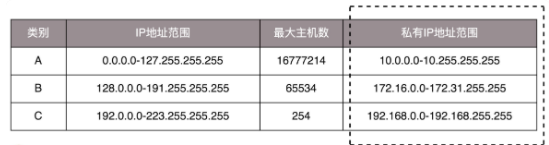
表格中最右一列是私有IP地址段。平时我们看到的数据中心、办公室、家里、学校等的IP地址,一般都是私有IP地址段,因为这些地址允许自己管理、分配,且可以重复。比如你学习的私有IP段和我们学习的是一样的。这就好比你们小区有门牌号121,我们小区也有门牌号121.
但公有IP地址是有组织统一分配的,你要用必须去买。比如你要建一个网站,给你们单位自己人用,那么让你们单位IT给你分配一个IP就行了;但如果有你要做个面向互联网用户的网站,就需要有一个公有IP地址,全世界的人都能访问。
192.168.0.x 是最常见的私有IP地址,你家有wifi,对应就会有一个IP地址,但你家上午的设备不会超过256个,所以/24就基本够了。有时我们也能见到/16这种CIDR。
很明显能看出192.168.0是网络后,而后面的就是主机号,例如网络里第一个地址就是192.168.0.1, 他常是路由器的地址,而192.168.0.255是广播地址,一旦发送给这个广播地址,网段内的所有机器都能收到。
1.3、MAC地址
在IP地址的上一行是 link/ether fa:16:3e:c7:79:75 brd ff:ff:ff:ff:ff:ff,这个被称为MAC地址,是一个网卡的物理地址,用16进制,6个byte 表示
MAC地址更像是身份证,是唯一的表示,但是他不具有路由功能,例如要找一个人,光说人名不行,先要找这个人家在哪个地方,然后在这个地方再找人名。
1.4、如何配置一个IP地址
要配置一个IP地址,可以通过命令行:
1、使用net-tools:
$ sudo ifconfig eth1 10.0.0.1/24
$ sudo ifconfig eth1 up
2、使用iproute2:
$ sudo ip addr add 10.0.0.1/24 dev eth1
$ sudo ip link set up eth1
自己配置IP地址,是随便配置吗?例如你旁边的机器都是192.168.1.x,如果我配置了一个16.158.23.6,会发生什么呢?答案是不能互相通信,下面来说为什么。
假设我在新配置的16.158.23.6上ping 192.168.1.6, 期望可以成功,但实际不能:Linux首先会判断,你要访问的网址,和当前服务器是否是同一个网段,是的话才会发送ARP请求,获取MAC地址。但如果不是同一个网段,就是跨网段调用,他不会直接把包发送到网络上行,而是其他把包发送到网关。
如果配置了网关,Linux会先获取网关的MAC地址,然后把包发出去,所以192.168.1.6这台机器,是不会收到请求包的,因为16.158.23.6把请求发给了网关,而网关的MAC地址并不是192.168.1.6的MAC地址。
而如果没有网关,由于二者不在同一网段,那么包根本就发不出去。
那如果把网关配置为192.168.1.6呢?Linux不会让你配置成功的,因为网关和当前网络至少一个网卡是同一个网段的,所以16.158.23.6的网关不可能是192.168.1.6。
所以,当需要手动配置一个网络IP是,需要确认使用正确的网段。
1.6、动态主机配置协议(DHCP)
一个IP一旦配置后,就不能变,但如果我要经常换地方,怎么办?这时就需要有一个自动配置的协议,即动态主机配置协议(Dynamic Host Configuration Protocol),简称DHCP。
这样,网关只需要配置一段共享的IP地址,每台新接入的集群,通过DHCP协议,来共享的IP里申请,然后自动配置就可以了,等人走了,还回去,其他机器就可以用了。
二、从二层到三层
2.1、第一层(物理层)
当两个人分别拿一台电脑,要联网时,可以拿一根网线,连接两台电脑,当然还需要配置两台电脑的IP、子网掩码、默认网关等。例如一个是192.168.0.1/24,另一个是192.168.0.2/24,必须在同一个网段。
这时,两台电脑已经组成了最小的局域网,即LAN。
如果三个人要联网玩游戏怎么办呢?这时需要一个叫Hub的东西,也就是集线器。和交换机不同,hub没有大脑,他完全在物理层工作,他会将自己收到的每一个字节,都复制到其他端口上,这就是第一层物理层联网的方案。
2.2、第二层(数据链路层)
hub采用的是广播的方式,但每个接入hub的人都能收到。所以,需要完善几个问题:
1)这个包是谁发的,发给谁的
2)大家都在发包,会不会混乱
3)如果发送失败怎么办
这几个问题,都是数据链路层,即MAC层要解决的问题。MAC全称是Medium Access Control,即媒体访问控制。他会控制媒体上发数据时,谁先发、谁后发的问题,防止发生混乱。这解决的是上面的第二个问题,学名叫做多路访问。就像车管所管马路上跑的车。
这个管理分三种方式:
方式1:分多个车道,每个车一个车道,你走你的,我走我的,这在计算机网络里叫信道划分
方式2:今天单号出现,明天双号出行,轮着来。这在计算机网络里叫做轮流协议
方式3:不管三七二十一,有事儿先出门,发现特堵,就回去。错过高峰再出,这叫做随机接入协议。著名的以太网,就是这个方式。
解决了第二个问题,就解决了媒体接入控制的问题,MAC的问题也就解决好了。这和MAC地址没什么关系。
接下来要解决的问题:发给谁,谁接收?这里用到一个物理地址,叫做链路层地址。但是因为第二层主要解决媒体接入控制的问题,所以他成被称为MAC地址。
解决第一个问题,就涉及到第二层的网络包格式。对于以太网,第二层的最开始,就是目标MAC地址和源MAC地址。
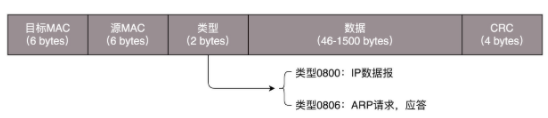
接下来是类型,大部分类型是IP数据包,然后IP里面包含TCP、UDP,以及http等。
有了这个目标MAC地址,数据包在链路上广播,MAC的网卡才能发现,这个包是给他的。MAC的网卡把包收进来,然后打开IP包,发现IP地址也是自己的,再打开TCP包,发现端口是80,也就是Nginx,于是将请求提交给nginx, Nginx返回一个网页,然后层层封装,最后到MAC层,因为来的时候有源MAC地址,返回的时候,源MAC地址就变成了目标MAC,再返回给请求的机器。
这里还有一个没解决的问题,当源集群知道目标机器的时候,可以把目标地址放入包里面,但如果不知道呢?一个广播的网络里面接入了n台机器,但并不知道都有哪些MAC地址,这就是ARP协议,也就是已知IP地址,求MAC地址的协议。

在一个局域网里,当知道了IP地址,不知道MAC怎么办?靠”吼“。

通过广而告之,发送一个广播包,谁是这个IP谁来回答。具体询问和回答的报文,就像下面这样:

为了避免每次都用ARP请求,机器本地也会进行ARP缓存。当然机器会不断地上线下线,IP也可能会变,所以ARP的AMC地址缓存过一段时间就会过期。
局域网
对于hub的方式,人数不多时可以,hub是广播的方式,但如果要智能些:谁能知道目标MAC地址是否就是连接某个口的电脑的MAC地址呢?这就需要一个能把MAC头拿下来,检测一下目标MAC地址,然后根据策略转发的设备,这个设备是第二层设备,称为交换机。
交换机怎么知道每个口的电脑的MAC地址呢?这需要交换机会通过学习记忆:一个MAC1电脑发送一个包给另一台MAC2电脑,当这个包到达交换机的时候,一开始交换机也不知道MAC2的电脑在哪个口,所以他只能将包发给出了发送者之外的所有其他的口,然后,交换机会记住,MAC1是来自哪个口,以后有包的目的是MAC1,就直接发送给这个口,所以久而久之,交换机就知道每个MAC和口的映射关系了,这时就不再需要广播了。当然,每个机器的IP会变,所在的口也会变,因而交换机上的学习的结果,称为转发表,这个表有一个国企时间。
有了交换机,用来接入几十台,上百台机器联网,就不是问题了。
2.3、交换机与VLAN
2.3.1、拓扑结构是怎样形成的
我们常见到办公室是一排排的桌子,每个桌子都有网口,一排十几个座位就有十几个网口,一个楼层就有几十个甚至上百个网口,这样环境就比前面的复杂了。
首先,这时一个交换机肯定不够用,需要多台交换机,交换机直接连接起来,就形成了一个稍微复杂的拓扑结构。
先看两台交换机的场景。两台交换机连接这三个局域网,每个局域网上有多台机器,如果机器1只知道机器4的IP地址,当他想要访问机器4,把包发出去的时候,他必须要知道机器4的MAC地址。

于是机器1发起广播,机器2收到了广播,但不是找他的,所以忽略;交换机A一开始也是不知道任何拓扑信息的,他收到这个广播后,除了广播包来的方向外,转发给其他所有的网口,于是,机器3也收到了广播,但不是找他的,忽略;当然交换机B也收到了广播,这时交换机B也是不知道任何拓扑信息的,所以他也做广播的策略,这时机器4和机器5都收到了广播信息。机器4会主动响应,这是我的MAC地址,于是一个ARP请求就成功完成了。
在上述过程中,交换机A和交换机B都能够学习到这样的信息:机器1是在左边这个网口的。这样当机器2要访问机器1时,机器2并不知道机器1的MAC地址,所以机器2会发起一个ARP请求,这个广播消息会到达机器1,也同时会到达交换机A,由于交换机A知道机器1在哪,所以不会广播到局域网2和局域网3了。
当机器3要访问机器1的时候,也需要发起一个广播的ARP请求,这时交换机A和交换机B都能收到这个广播请求,交换机A知道主机A所在的网口,所以他会把广播消息转发到局域网1,同时,交换机B收到这个广播后,他知道机器1不在右边这个网口,所以他不会将消息广播到局域网3.
2.3.2、如何解决场景的环路问题
随着办公室越来越大,交换机数目也越来越多,当整个拓扑变得复杂了,这么多网线,绕来绕去,不可避免会出现预料不到的情况,其中常见的问题就是环路问题。
如下图,当两个交换机把两个局域网同时连接起来时,你可能觉得这个高可用好,但却出现了环路。

我们来详细一下机器1访问机器2的过程。一开始,机器1并不知道机器2的MAC地址,他需要发起一个ARP广播,广播到达机器2,机器2会把MAC地址返回来,看起来没有2个交换机什么事。
但是两个交换机还是能收到广播包的,交换机A一开始是不知道机器2在哪个局域网的,所以他会把广播消息放到局域网2,在局域网2广播的时候,交换机B右边这个网口也是能收到广播消息的,交换机B又会将这个广播消息发送到局域网1,局域网1的这个广播消息,又会到达交换机A左边的这个借口。交换机A这时候还是不知道机器2在哪个局域网,于是又将广播包转发到局域网2,这样就死循环了。
所以,必须有一个方法解决环路问题。
在数据结构中,有种方法叫做最小生成树。有环的我们成为图。将图中的环破了,就生成了树。在计算机网络中,生成树的算法叫做STP,全称为Spanning Tree Protocol。
2.3.3、如何解决广播问题和安全问题
机器多了,交换机也多了,就算交换机比hub智能一些,但还是难免有广播的问题,这样性能就下来了。
由于在同一个广播域里面,很多包都会在一个局域网里面飘,如果碰到了一个会抓包的程序员,就能抓到这些包,如果没有加密,就能看到敏感信息了。
解决方法有两种:物理隔离、虚拟隔离
1、 物理隔离:每个部门有单独的交换机,配置单独的子网,这样部门之间的沟通就需要路由器了,路由器的原理后面再讲。但这样做的问题在于,有的部门人少,有的部门人多,如果每个部门有单独的交换机,口多了浪费,口少了还不够用。
2、虚拟隔离,也就是我们常说的VLAN,叫虚拟局域网。使用VLAN,一个交换机上会连属于多个局域网的机器,那交换机怎样区分哪个机器属于哪个局域网呢?

我们只需要再二层的头上加一个TAG,里面有一个VLAN ID,一共12位。为什么12位呢?因为12位可以划分4096个VLAN,只有4096个VLAN,是不是不够啊,这个后面再说。
当我们买的交换机是支持VLAN的,当这个交换机把二层的头取下来时,就能识别VLAN ID。只有相同的VLAN的包,才会互相转发,不同VLAN的包,是互相看不到的,这样广播问题和安全问题就解决了。

2.4、ICMP与ping:投石问路的侦察兵
2.4.1、ICMP协议的格式
当网络访问不同时,通常会ping一下,那么ping是如何工作的呢?
ping是基于ICMP协议工作的。ICMP全称Internet Control Message Protocol,就是互联网控制报文协议。其中关键词是”控制“。
ICMP的报文是封装在IP包里的。在传输指令时,肯定需要源地址和目标地址。这个协议本身非常简单,因为侦察兵要轻装上阵。

ICMP报文有很多类型,不同的类型有不同的代码。最常用的类型是主动请求为8,主动请求的应答为0。
2.4.2、查询报文类型
ping就是查询报文,是一种主动请求,并且获得主动应答的ICMP协议。
对于ping的主动请求,进行网络抓包,称为ICMP ECHO REQUEST。同理,主动请求的回复,称为ICMP ECHO REPLY。
比起原生的ICMP,ping多了2个字段,一个是标识符(例如2个侦察兵,一个去找水源的,另一个去侦察敌情的),一个是序号(给每个侦察兵编号)
ping还会存放发送请求的时间,来计算往返时间,说明路程的长短。
2.4.3、差错报文类型
由异常情况发起的,报告发送了不好的事情,对应ICMP的差错报文类型。
举几个差错报文的例子:终点不可达为3;源抑制为4;超时为11;重定向为5。
第一种:终点不可达
对于终点不可达,原因是啥呢?网络不可达代码是0,主机不可达代码是1,协议不可达代码为2,端口不可达代码为3,需要进行分配但设置了不分片代码为4.
第二种:源站抑制
让源站放慢发送速度。
第三种:时间超时
超过网络包的生存时间还是没到
第四种:路由重定向
也即是让下次发给另一个路由器
差错路由的结构相对复杂些,除了前面还有IP,ICMP的前8字节不变,后面则跟上出错的那个IP包的IP头和IP正文的前8个字节。
2.4.4、ping:查询报文类型的使用
我们看ping的发送和接收过程

假设主机A的IP是192.168.1.1, 主机B的IP是192.168.1.2, 他们都在同一个子网,那当你在主机A上运行 ”ping 192.168.1.2" 后,会发生什么?
ping命令执行的时候,源主机首先会构建一个ICMP请求数据包,ICMP数据包包含多个字段,最重要的有2个字段,一个是”类型字段“,对于请求包而言该字段值是8;另一个字段是”字段号”,主要用于区分连续ping时候发出的多个数据包。
然后,由ICMP协议将这个数据包连同地址192.168.1.2 一起交给IP层,IP层将以192.168.1.2作为目的地址,本机IP地址作为源地址,加上一些其他控制信息,构建一个IP数据包。
接下来,需要加入MAC头,如果在ARP映射表中查找出IP地址192.168.1.2所对应的MAC地址,则可以直接使用;如果没有,则需要发送ARP协议,查询MAC地址,获得MAC地址后,由数据链路层构建一个数据帧,目的地址是IP层传过来的MAC地址,源地址是本机的MAC地址;还有附加一些控制信息,依据以太网的介质访问规则,将他们传送出去。
主机B收到这个数据帧后,先检查他的目的MAC地址,并和本机的MAC地址对比,如果符合,则接受,否则丢弃。接受后检查该数据帧,将IP数据包从帧中取出来,交给本机IP层。同样,IP层检查后,将有用的信息提取后交给ICMP协议。
主机B会构建一个ICMP应答包,应答数据包的类型字段为0,顺序号为接收到的请求数据包中的顺序号,然后再发送出去给主机A
在规定的时间内,源主机如果没有收到ICMP的应答包,则说明目标主机不可达;如果接收到熬了ICMP应答包,则说明目标主机可达。
当然上述过程只是最简单的场景,同一个局域网里的情况。如果跨网段的话,还会涉及网关的转发、路由器的转发等等。
经常会遇到一个问题,如果不在我们的控制范围内,很多中间设备都是禁止ping的,但是ping不通不代表网络不通,这时候就要使用telnet,通过其他协议来测试网络是否通。
2.5、网关
校园网的IP是10.10.x.x,然后给你宿舍分配的IP是192.168.1.x,这时,如果宿舍的人要上校园网,需要两个网卡,一个插在校园网的网口,另一个插在宿舍一个同学的电脑上,此时,这个同学就能上网了。但如果该宿舍的其他同学也要上网,就要把已联网成功的同学的电脑当成路由器,然后你需要配置:DHCP(默认的),IP地址,还需要配置网关。
一旦配置了IP地址和网关,就可以访问目标地址了。跨网关时,牵扯到MAC地址和IP地址的变化,这里有必要描述下MAC头和IP头的细节:

在MAC头里,先是目标MAC地址,然后是源地址,然后有一个协议类型,用来说明里面是IP协议。
IP头里面的版本号,目前的主流还是IPV4, TOS 是 IP 头里面的一个字段,代表了当前的包是高优先级的,还是低优先级的。TTL是追踪去往目的地时沿途经过的路由器,还有8位的协议,指TCP还是UDP。最重要的还是源IP地址和目标IP地址。
在任何一台机器上,当要访问另一个IP地址的时候,都会先判断,这个目标IP地址,和当前机器的IP地址,是否在同一个网段。怎样判断同一个网段呢,需要CIDR和子网掩码。
如果是同一个网段,就不需要网关了,直接将源地址和目标地址放入IP头中,然后通过ARP获得MAC地址,将源MAC和目的吗放入MAC头中,发出去就可以了。
如果不是同一网段,就需要发往默认的网关Gateway。Gateway的地址一定是和源IP地址是同一个网段的,例如 192.168.1.0、24这个网段,Gateway往往是192.168.1.1/24 或者 192.168.1.2/24,即不是第一个就是第二个。
如何发往默认的网关呢?由于网关和源IP是同一个网段,这个过程就和发往同一网段其他机器是一样的:将源地址和目标IP都放入IP头中,通过ARP获得网关的MAC地址,将源MAC地址和网关的MAC放入MAC头中,发送出去。网关所在的端口,例如 192.168.1.1/24 将网络包收进来,然后接下来怎么做,就看网关的了。
网关往往是一个路由器,是一个三层转发的设备。啥是三层设备呢?就是把MAC头和IP头都取下来,然后根据里面的内容,看看接下来把包往哪里做转发的设备。
在很多情况下,人们把网关叫做路由器,其实不是很准确。而另一个比喻更恰当:路由器是一台设备,他有5个网口,相当于有5只手,分别连着五个局域网,每只手的IP地址都和局域网的IP地址在相同的网段,每只手都是他握住的那个局域网的网关。
任何一个想发往其他局域网的包,都会到达其中一只手,被拿进来,拿下MAC头和IP头,看看,然后根据自己的路由算法,选择另一只手,加上IP头和MAC头,然后发出去。
2.5.1、静态路由是什么
那么,Gateway会选择哪只手呢?路由分静态路由和动态路由。先看静态路由。
静态路由,其实就是在路由器上,配置一条条规则:想访问BBS站,他从2号口出去,下一跳是IP2;想访问教学视频站,从3号口出去,下一跳是IP3,然后保持在路由器里。
这样当要选择那只手时,就根据规则匹配,从对应的口出去。
经过网关后,IP头和MAC头,哪些变哪些不变呢?
由于MAC地址只是在局域网内才有效的地址,所以MAC地址只要过了网关,就一定会改变,因为已经换了局域网。
不改变IP地址的网关,叫转发网关;改变IP地址的网关,叫做NAT网关。

服务器A要访问服务器吧。首先,服务器A和服务器B不是同一个网段的,所以需要先发给网关。网关是192.168.1.1,然后发送ARP,获取网关的MAC地址,然后发送包,内容如下:
源 MAC:服务器 A 的 MAC
目标 MAC:192.168.1.1
这个网口的 MAC源 IP:192.168.1.101
目标 IP:192.168.4.101
包达到192.168.1.1这个网口,发现MAC一直,把包收进来,然后想想往哪发。
由于配置了静态路由,要想访问192.168.4.0/24,要从192.168.56.1这个口发出去,下一跳为192.168.56.2。
路由器A匹配上了路由后,要从192.168.56.1这个口发出去,发给192.168.56.2,路由器A发送ARP获取192.168.56.2的MAC地址,然后发包出去,内容如下:
源 MAC:192.168.56.1 的 MAC 地址
目标 MAC:192.168.56.2 的 MAC 地址
源 IP:192.168.1.101
目标 IP:192.168.4.101
包到达192.168.56.2这个网口,发现MAC一直,把包收进来,然后考虑往哪发。
由于路由器B配置了静态路由,想要访问192.168.4.101/24,要从192.168.4.1这个口发出去,没有下一跳了。
路由器b 发送ARP获取192.168.4.101的MAC地址,然后发送包,内容如下:
源 MAC:192.168.4.1 的 MAC 地址目标
MAC:192.168.4.101 的 MAC 地址
源 IP:192.168.1.101
目标 IP:192.168.4.101
这样包到达服务器B,MAC地址匹配,把包收进来。
可以看出,没到一个新的局域网,MAC都是要变的,但IP地址不变。在IP头里面,不会保存任何网关的IP地址。所谓的下一跳,某个IP要把这个IP地址转成MAC放入MAC头。
如果源IP和目标IP一致怎样解决呢?

即大唐要到印度,大唐的IP地址是192.168.1.101,印度地址也是192.168.1.101,他们的局域网直接没有上了过,因此IP冲突了。
怎样解决呢?既然他们各自的局域网没有商量过,那么在中间局域网里,就需要使用另外的地址,就像出国,不能再用国家自己的身份证,必须用国际通用的护照。
首先,目标服务器B在国际上要有一个国际的身份,我们给他定一个192.168.56.2(B网关),对应的国内身份是192.168.1.101,凡是要访问192.168.56.2,都转成192.168.1.101。
于是,第一步:
源 MAC:服务器 A 的 MAC
目标 MAC:192.168.1.1 这个网口的 MAC
源 IP:192.168.1.101
目标 IP:192.168.56.2
第二步:
源 MAC:192.168.56.1 的 MAC 地址
目标 MAC:192.168.56.2 的 MAC 地址
源 IP:192.168.56.1
目标 IP:192.168.56.2
第三步:
源 MAC:192.168.1.1 的 MAC 地址
目标 MAC:192.168.1.101 的 MAC 地址
源 IP:192.168.56.1
目标 IP:192.168.1.101
2.6、路由协议
一旦出了网关之后,就好像玄奘西行踏上了江湖漂泊的路,会面临很多路由器,有很多道路可以选。
2.6.1、如何配置路由
路由器就是一台网络设备,他有多张网卡。当一个入口的网络包发送到路由器时,他会根据一个本地的转发信息库,来决定如何正确地转发流量。这个转发信息库被称为路由表。
一张路由表中会有多条路由规则,每条规则至少包含三项信息:
1、目的网络:这个包想去哪
2、出口设备:包从哪个口发出去
3、下一跳网关:下一个路由器的地址
通过route命令和ip route命令都可以进行查询或者配置。
例如,我们设置 ip route add 10.176.48.0/20 via 10.173.32.1 dev eth0 ,就说明要去 10.176.48.0/20 这个目标网络,要从 eth0 这个端口出去,经过 10.173.32.1。
网关上的路由策略,就是按这三项配置信息配置的,这种配置方式的核心思想是:根据目的IP地址来配置路由。
在真是的复杂的网络环境中,除了可以根据目的IP地址配置路由外,还可以根据多个参数来配置路由,这称为路由策略。
可以配置多个路由表,可以根据源IP地址、入口设备、TOS等选择路由表,然后在路由表中查找路由,这样可以使得来自不同来源的包走不同的路由。
ip rule add from 192.168.1.0/24 table 10
ip rule add from 192.168.2.0/24 table 20
表示从 192.168.1.10/24 这个网段来的,使用 table 10 中的路由表,而从 192.168.2.0/24 网段来的,使用 table20 的路由表。
上面的静态路由算法,在网络环境简单的时候,是在可控范围内的,但对于复杂的网络环境,就需要动态路由算法。
2.6.2、动态路由算法
使用动态路由的路由器,可以根据路由协议算法生成动态路由表,随着网络运行状况的变化而变化。
从源地址到目标地址,一定是走的路越少越好,因而就转化成了如何在途中找到最短路径问题。
动态路由协议
1、基于链路状态路由算法的OSPT
OSPF(Open Shortest Path First,开放式最短路径优先)就是这样一个基于链路状态路由协议,广泛应用在数据中心中的协议。由于主要用在数据中心内部,用于路由决策,因而称为内部网关协议(Interior Gateway Protocol,简称 IGP)。
内部网关协议的重点就是找到最短的路径。在一个组织内部,路径最短往往最优。当然有时候 OSPF 可以发现多个最短的路径,可以在这多个路径中进行负载均衡,这常常被称为等价路由。
2、基于距离矢量路由算法的BGP
但是外网的路由协议,也即国家之间的,又有所不同。我们称为外网路由协议(Border Gateway Protocol,简称 BGP)。
三、传输层(最重要)
传输层最重要的协议就是TCP和UDP了,对于应用开发人员来说,最常用就是这两个协议。
3.1、UDP协议:性善而简单
3.1.1、TCP和UDP的区别?
大家都知道,TCP是面向连接的,而UDP是面向无连接的。
在互相发消息前,面向连接的协议会先建立连接,例如TCP会先三次握手,而UDP不会。
所谓建立连接,是为了在客户端和服务端维护连接,而建立一定的数据结构来维护双方交互的状态,用这样的数据结构来保证所谓的面向连接的特性。
TCP提供可靠交付:通过TCP连接传输的数据,无差错、保证不丢、不重、不乱序。
我们知道IP包是没有任何可靠性保证的,一旦发出去,就像西天取经,走丢了,被妖怪吃了,都只能随他去。但TCP号称能做到这些,而UDP继承了IP包的特性,不保证不丢,不保证不乱序。
还有,TCP是面向字节流的。发送的时候发的是一个流,没头没尾。而IP包可不是一个流,而是一个个IP包。之所以变成流,是TCP自己的状态维护做的。而UDP继承了IP的特性,基于数据报的,一个一个地发,一个一个地收。
还有,TCP是有拥塞控制的,他意识到包丢了或网络环境不好了,就会根据情况调整自己的行为,看着如果发快了,就发慢点。UDP就不会,应用让我发,我就发,别的不管。
因而TCP其实是有状态的,里面精确地记录这发送了没有,接收了没有,发到到哪了,应该接收到哪了,错一点都不行。而UDP则是无状态的,发出去就发出去了。
如果MAC层定义了本地局域网的传输行为,IP层定义了整个网络端到端的传输行为,这两层基本定义了这样的基因:网络传输是以包为单位的,二层叫帧,网络层叫包,传输层叫段。我们笼统地称为包。包单独传输,自行选路,在不同的设备封装解封装,不保证到达。
3.1.2、UDP包头是什么样的?

当我发送的UDP包达到目标机器后,发现MAC地址匹配,就取下来,把剩下的包传给处理IP层的代码。把IP头取下来,发现目标IP匹配,接下来,这里面的数据发给谁呢?
发送时,我知道我发的是UDP包,但收到的机器咋知道的呢?所以在IP头里面有个8位的协议,这里会存放数据里是TCP还是UDP。于是,如果我们知道是UDP,就能从数据里面,把内容解析出来。
解析出来以后,数据交给谁处理呢?
处理完传输层的事情,内核的事情基本干完了,里面的数据应该交给应用程序去处理。
应用程序网络通信,无论用TCP还是UDP,都需要监听一个端口。正是这个端口,用来区分应用程序,所以端口不能冲突。所以根据端口号,可以将数据交给应用程序。
当我们看到UDP包头的时候,发现的确有端口号,有源端口号和目标端口号。但对比TCP, 我们发现UDP除了端口号,没有其他的了,真是简单的不行。
3.1.3、UDP三大特点
1、沟通简单
2、轻信他人:UDP不会建立连接,虽然有端口号,但谁都可以给他传数据,他也可以传给任何人数据,甚至同时给多人传数据
3、做事不懂权变:他不会根据网络的情况进行发包的拥塞控制,不管网络丢包多厉害,他还继续发。
3.1.4、UDP的三大使用场景
1、需要资源少,在网络情况好的内网,或者对于丢包不敏感的应用。
2、不需要一对一沟通,而是可以广播的应用
3、需要处理速度快,延时低,可以容忍少数丢包,但是要求及时网络拥塞,也不必退缩。
3.2、TCP协议:性恶而复杂
3.2.1、TCP包头格式
TCP包头比UDP复杂:

1)首先,源端口号和目标端口号是不可少的,这跟UDP一样。
2)接下来是包的序号。为什么要包的序号呢?这时为了解决不乱序的问题,用来排序。
3)还要有确认序号:发出去的包应该有确认,要不然我怎么知道对方收到了没有。没有没有收到就重发,知道对方收到。这是用来解决不丢的问题。
4)接下来有一些状态位:例如SYN是发起一个连接,ACK是回复,RST是重新连接,FIN是结束连接等。
5)还有一个重要的就是窗口大小。TCP要做流量控制,通信双方各声明一个窗口,表示自己当前能够处理的能力,别发送太快,撑死我;也别发送太慢,饿死我。
3.2.2、TCP的三次握手
TCP是基于连接的协议。建立连接的过程,称为三次握手。
A:你好,我是A
B:你好 A,我是B
A:你好 B
我们也常称为“请求–> 应答 --> 应答之应答" 三个回合。
首先,为什么是3次,不是2次或4次呢?
我们假设这个通路是不可靠的,A要发起一个连接,当发了第一个请求没有回信时,会有很多种可能,比如第一个请求包丢了;也可能没丢,但绕了弯路,超时了;也可能B没有响应,不想和我连接。
A不想确认结果,于是再发,再发。终于,有一个请求包到达了B,但请求包到了B的这个事情,A是不知道的,A可能再发。
B收到了请求包,就知道了A要和他建立连接,如果B不想建立连接,A会重试一阵后放弃,建立连接失败,没有问题;如果B想建立连接,则会发送应答包给A。
当然对于B来说,B也不知道A收到了没有,这时候B自然不能认为连接已经建立好了,因为应答包仍然可能丢,会绕弯路而超时,甚至A可能挂了。
而且这时B还可能遇到个诡异的现象,A和B建立连接后,做了简单的通信,然后结束了连接。但A最初在建立连接时,可能给B重复发了几次,有的请求可能绕了一圈到达了B,B会认为这是个正常的建立连接的请求,因此建立了连接,但A并不知道,因此这个连接永远不会终结。因此两次握手不行。
B发送的应答可能会发送多次,但只要一次到达了A,A 就会认为连接已经建立了,因为对于A来说,消息有去有回。A会给B发送应答之应答,而B也在等这个消息,才能确认连接的建立,只有等到了消息,对于B来讲,他的消息才算有去有回。
但如果B在给A发送应答之应答之应答,这样就没头了,所以四次握手是可以的,但没有必要。只要双方的消息都有去有回,就可以了。
好在大部分情况下,A和B建立了连接后,A会马上发送数据,一旦A发送了数据,则很多问题都得到了解决。例如A发给B的应答丢了,当A后续发送数据给B,B收到后,就可以认为这个连接已经建立;或者B挂了,A发送数据会报错,说B不可达,A就知道B出事情了。
当然你可以说A比较坏,建立连接后就是不发数据,我们在程序设计是,可以要求开启keepalive机制,即使没有真实的数据包,也有探活包。
另外,作为服务端B的程序设计者,如果A这种长时间不发包的客户端,可以主动关闭,从而空出资源来给其他客户端使用。
三次握手出了双方建立连接外,主要还是沟通一件事:TCP包的序号的问题。
A要告诉B,我这发起的包的序号,是从哪个号开始的,B同样要告诉A,B发起的包的序号从哪个号开始的。为什么序号不能从1开始呢?因为这样往往会出现冲突:
例如,A连上B后,发送了1,2,3三个包,但是发送3时,可能丢了,或者绕路超时了,于是A重发3,但上次绕路的3又回来了,发给了B,这样B可能认为,是下一个包,这样就发生了错误。所以序号是用来排重的。
因此,每个连接都有不同的序号,这个序号的起始序号是随着时间变化的,可以看成一个32位的计数器,每4微妙加1,如果要序号重复,需要4个多小时。IP包头里有个TTL,即生存时间。
双方建立了连接后,为了维护这个连接,双方都要维护一个状态机,在连接连接过程中,双方的状态变化时序图如下:

一开始,客户端和服务端都处于CLOSED状态。显式服务端主动监听某个端口,处于LISTEN状态。然后客户端主动发起SYN,之后处于SYN-SENT状态。服务端收到发起的连接,并且ACK客户端的SYN,之后处于SYN-RCVD状态。客户端收到服务端发送的SYN和ACK后,发送ACK的ACK,之后处于ESTABLISHED状态,因为他一发一收成功了。服务端收到ACK的ACK之后,处于ESTABLISHED状态,因为他也一发一收了。
3.2.3、TCP四次挥手
TCP连接结束,会做”四次挥手“
A:B,我不想玩了
B:哦,我知道了
这时,A不再发送数据了,但B能不能在ACK后直接关闭连接呢?当然不行,因为A是发完最后的数据,不想玩了,但B还没做完自己的事情,还是可以发送数据的,所以此时称为半关闭状态。
这时A可以选择不再接收数了,也可以选择再接收一段时间数据,等待B也主动关闭。
B:A,好吧,我也不玩了,88
A:好的,88
这样整个连接就关闭了。
但是这个过程有没有异常情况呢?有。
A开始说”我不玩了“,B说”知道了“,这个回合,是没有异常的,因为在此之前,双方还处于合作的状态。但是这个回合结束后,就可能出现异常了:
一种情况是,A说完”不玩了“后,直接跑路,这是会有问题的,因为B还没有发起结束。而如果A跑路,B就算发起结束,也得不到回答,B就不知道该怎么办了。
另一种情况是,A说完”不玩了“,B直接跑路,也是有问题的,因为A不知道B是否还有事情要处理。
为了解决这个问题,TCP协议专门设计了几个状态来处理这些问题,下面看断开连接的状态时序图:

断开时,A说”不玩了“,就进入FIN_WAIT_1的状态,B收到”A不玩“的消息后,回复“知道了”,就进入CLOSE_WAIT的状态
A收到“B说知道了”,就进入FIN_WAIT_2的状态,如果这时候B直接跑路,那A将永远在这个状态,TCP协议里没有对这个状态的处理,但Linux有,可以调整tcp_fin_timeout这个参数,设置一个超时时间。
如果B没有跑路,发送了“B也不玩了”的请求到达A时,A发送“知道B也不玩了”的ACK后,从FIN_WAIT_2状态结束,按说A可以跑路了,但最后的这个ACK万一B没有收到呢?则B会重新发送一个“B 不玩了”,这时如果A已经跑路了,B就再也收不到ACK了,因此TCP协议要求A最后等待一段时间TIME_WAIT,这个时间要足够长,长到如果B没有收到ACK的话,“ B 说不玩了”会重发的,A收到后会重新发一个ACK并且足够时间到达B。
A直接跑路还有一个问题是,A的端口就直接空出来了,可能会被新的应用占用。但B不知道,B原来发的过很多包都在路上,可能会发到新的应用上,虽然序列号是重新生成的,但这里要上一个双保险,防止产生混轮,因此也需要等足够长的世界,等到原来B发送的所有的包都没了,再空出端口来。
等待的世界设为1MSL,MSL是Maximum Segment Lifetime,报文最大生存时间。他是任何报文在网络上存在的最大时间,超过这个时间,报文将被丢弃。因为TCP的报文是基于IP协议的,而IP头中有一个TTL域,是IP数据报可以经过的最大路由数,每经过一个处理他的路由器的这个值就减一,当这个值为0时,这个数据包将被丢弃,同时发送ICMP报文通知源主机,协议规定MSL为2分钟,实际应用时常用的是30秒,1分钟和2分钟等。
还有一个异常情况是,B超过了2MSL实际,依然没有收到他发的FIN的ACK,这时B会重发FIN,A收到后,A表示我已经等了足够长时间了,已经仁至义尽,之后发的我已经不认了,于是就直接发送RST,B就知道A已经结束了。
3.2.4、TCP如何实现有序、不丢
TCP为了保证数据包有序,每个包都有一个ID。在建立连接时,会确定起始ID是什么。为了保证不丢包,对发送的包都要进行ACK应答,但不是逐个应答,而是累计应答,即一次回复某个ID之前的所有请求。
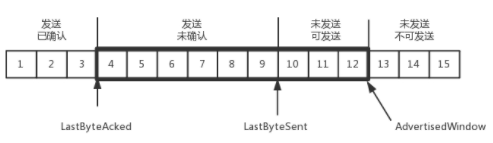
为了记录所有发送的包和接收的包,TCP也需要发送端和接收端分别有缓存来保持这些记录,发送端的缓存里是按照包的ID一个个排列,根据处理的情况分成四个部分:
1)发送了并且已经确认的。可以比喻成你交代下属做的,并且已经做哇了,可以划掉了。
2)发送了并且尚未确认的。可以比喻成你交代下属做的,但还没做哇,需要等待做完回复后,才能划掉
3)没有发送,但已经等待发送的。可以比喻成你准备交代给下属做的,但还没来得及交代的
4)没有发送,并且暂时还不会发送的。可以比喻成你没有交代给下属做的额,且暂时还不会交代给下属做的。
3和4的区别,可以比喻成领导交代下属做事时,要“流量控制,把握分寸”,根据下属的能力来分配工作,不是任务太多,下属做不完,就该辞职了。
到底一个员工能处理多少事情呢?在TCP里,接收端会给发送端报一个窗口大小,叫做Advertised window,这个窗口的大小等于第二部分+第三部分,超过了这个窗口,接收端就处理不过来了,就不能发送了。
于是,发送端需要保持下面的数据结构:
对于接收端来讲,他缓存里记录的内容要简单一些。
第一部分:他接收并且确认过的:我领导交给我的,我已经做完了的
第二部分:还没接收,但马上就能接收的。即我自己能承受的最大工作量
第三部分:还没接收,也没法接收的。即超过了工作量的部分,实在做不完。
对应的数据结构如下:
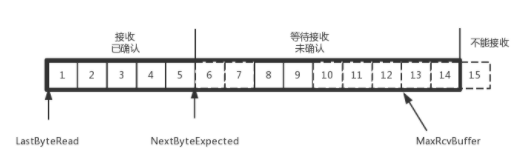
顺序问题与丢包问题
举例:发送端发送1~15条消息,1,2,3发送并收到了确认;4,5,6,7,8,9发送了还还没收到确认,10,11,12还没发出,13,14,15是接收方没有空间,不准备发的。
发送端和接收端当前的状态如下:
1)1,2,3没有问题,双方达成了一致
2)4,5 接收方发ACK了,但发送方还没收到,可能丢了,也可能在路上
3)6,7,8,9肯定都发了,但8,9已经收到了,6,7还没收到,这就出现了乱序,接收方需要先换成8,9但没办法回复ACK
从上面例子可以看出,乱序和丢包都有可能发生,下面看怎样通过确认和重复机制来解决:
假设接收方收到了4,5,然后回复ACK,发送方收到了4的ACK, 但5个ACK包丢了,6,7的数据包在发送给接收方的途中丢了,怎么办呢?
方法1:超时重试。即对每一个发送了的,但没有收到ACK的包,都通过定时器做超时重试,超时时间必须大于往返时间RTT,否则会引起不必要的重发,但也不宜过长。
估计往返时间,需要TCP通过采样RTT时间,然后做加权平均,算出一个值,并且这个值是不断变化的。由于重传时间是不断变化的,我们成为自适应重传算法(Adaptive Retransmission Algorithm)。
如果过一段时间,5,6,7都超时了,就会重新发送。接收方发现原来5接收过,于是丢弃;6收到了,发送ACK,要求下一个是7,7不幸又丢了,当7再次超时的时候,TCP的策略是超时间隔加倍。每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的2倍,超时2次,就说明网络环境差,不再频繁发送。
超时重传的弊端是,超时周期可能相对较长,是不是可以有更快的方式呢?
有:当接收方收到一个序号大于下一个期望的报文段时,就会检测到数据流中的一个间隔,于是他就会发送冗余的ACK,仍然ACK的是期望的报文段,而当客户端收到三个冗余的ACK后,就会在定时器过期之前,重传丢失的报文段。
例如,接收方发现6收到了,8也收到了,但7还没收到,那肯定是丢了,于是发送6的ACK,要求下一个是7。接下来,收到后续的包,仍然发送6的ACK,要求下一个是7,当客户端收到3个重复ACK,就会发现7的确丢了,不等超时,马上重发。
还有一种方式成为Selective Acknowledgement(SACK),这种方式需要在TCP头里面加一个SACK的东西,可以将缓存的地图发送给发送方,例如,可以发送ACK6, SACK8,SACK9,有了地图,发送方一下子就能看出7是丢了。