目录
前提:提醒本文比较长,前半部分为理论知识,看得会比较困;后半部分为实践,看得会兴奋。
一、什么是JVM?
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM只是定义了一套公开的标准规范,说到底JVM也是一个软件,各个公司只要有能力的可以按照这套规范编写自己的虚拟机,目前市面上有(HotSpot:虚拟机的一种实现,它是sun公司“被oracle公司收购了”开发的,是sun jdk和open jdk中自带的虚拟机,可以在安装的jdk/jre和jre目录下看到jvm.dll文件,同时Hotspot也是目前使用范围最广的虚拟机,而Hotspot JVM是C++汇编语言实现的,所以说虚拟机虽然叫机,但是是软件模拟硬件功能虚拟出来的),JDK是java Development kit(java开发工具),JRE是java Runtime Environment(java运行环境,里面就包含了JVM)。
二、JVM的作用?
1、跨平台运行
JVM屏蔽了与具体操作系统平台(Mac、Windows、Linux等等)相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。JVM在执行字节码时,实际上最终还是把字节码解释(或者是说成翻译)成具体平台上的机器指令(机器语言010101)执行。这就是Java语言最重要的特点跨平台运行。使用JVM就是为了支持与操作系统无关,实现跨平台。java之所以说‘一次编译,处处运行’就是这个原因,只要你机器能安装对应操作系统的JDK/JRE,就可以运行java代码,这就是为什么你可以在Windows和Mac等运行的操作的机器上开发java/android。

从上图中可以看到,有了 JVM 这个抽象层之后,Java 就可以实现跨平台了。JVM 只需要保证能够正确执行 .class 文件,就可以运行在诸如 Linux、Windows、MacOS 等平台上了。
2、跨语言
现在用kotlin编写的代码也可以运行在JVM上,因为kotlin编译之后也是字节码文件,JVM运行的就是字节码,所以说不管你什么语言,只要你能编译成符合规范的字节码文件就能运行在jvm虚拟机上。JVM只识别字节码,所以JVM其实跟语言是解耦的,也就是没有直接关联,并不是它翻译Java文件,而是识别class文件,这个一般称之为字节码。还有像Groovy 、Kotlin、Jruby等等语言,它们其实也是编译成字节码,所以也可以在JVM上面跑,这个就是JVM的跨语言特征。
三、JVM JRE JDK的关系
JVM只是一个翻译,把Class翻译成机器识别的代码,但是需要注意,JVM 不会自己生成代码,需要大家编写代码,同时需要很多依赖类库,这个时候就需要用到JRE。
JRE是什么,它除了包含JVM之外,提供了很多的类库(就是我们说的jar包,它可以提供一些即插即用的功能,比如读取或者操作文件,连接网络,使用I/O等等之类的)这些东西就是JRE提供的基础类库。JVM 标准加上实现的一大堆基础类库,就组成了 Java 的运行时环境,也就是我们常说的 JRE(Java Runtime Environment)。
但对于程序员来说,JRE还不够。我写完要编译代码,还需要调试代码,还需要打包代码、有时候还需要反编译代码。所以我们会使用JDK,因为JDK还提供了一些非常好用的小工具,比如 javac(编译代码)、java、jar (打包代码)、javap(反编译<反汇编>)等。这个就是JDK。
具体可以文档可以通过官网去下载:https://www.oracle.com/java/technologies/javase-jdk8-doc-downloads.html
四、JVM内存模型剖析
根据JVM规范(狭义上指的就 HotSpot,目前使用的最多),JVM 内存共分为线程私有(虚拟机栈,程序计数器,本地方法区),线程共享(堆,方法区)五个部分。
JVM运行过程:HelloWorld.java--(javac编译)--->HelloWorld.class----->通过类加载器加载到JVM的运行时数据区(也就是内存)

1、程序计数器(线程私有的区域)
1.1、为什么JVM中需要程序计数器? 这个和CPU的时间片轮转机制有关,操作系统层的。当某个线程代码执行过程中,被CPU轮转切换到别的线程去执行了,这时候程序计数器就能记录刚刚那个线程执行到哪个位置了,下次CPU切换回来的时候,就从这个记录的位置开始执行。程序计数器是一块很小的内存空间,当前线程执行的字节码的行号指示器。
1.2、JVM中唯一不会发生OOM的区域就是程序计数器。
2、虚拟机栈(线程私有的区域)
就是我们常说的java中的堆栈的栈。
栈是什么样的数据结构?先进后出(FILO)的数据结构,虚拟机栈在JVM运行过程中存储当前线程运行方法所需的数据,指令、返回地址。Java 虚拟机栈是基于线程的。哪怕你只有一个 main() 方法,也是以线程的方式运行的。在线程的生命周期中,参与计算的数据会频繁地入栈和出栈,栈的生命周期是和线程一样的。栈里的每条数据,就是栈帧。在每个 Java 方法被调用的时候,都会创建一个栈帧,并入栈。一旦完成相应的调用,则出栈。所有的栈帧都出栈后,线程也就结束了。
下面通过一段代码执行过程来看看虚拟机栈如何运行的:
public class jvmTest {
public static void main(String[] args) {
jvmTest j = new jvmTest();
j.add();
}
public int add() {
int x = 2;
int y = 6;
int z = (x + y) * 20;
return z;
}
}运行一下上面代码。然后找到它运行后的字节码文件,通过javap工具反编译一下jvmTest.class文件,查看相应的java编译器生成的字节码。

进入该字节码文件夹目录,并打开这个目录下的终端cmd,执行javap -c jvmTest.class,就可以看到对应的字节码

反编译的结果:

每开始执行到一个方法就相当于一个虚拟机栈的栈帧,栈帧入栈操作,当方法执行完,就会出栈。当一个线程所有的栈帧执行完,线程就结束了。
每个栈帧,都包含四个区域:(局部变量表、操作数栈、动态连接、返回地址),栈的大小缺省为1M,可用参数 –Xss调整大小,例如-Xss256k
局部变量表:顾名思义就是局部变量的表,用于存放我们的局部变量的。首先它是一个32位的长度,主要存放我们的Java的八大基础数据类型,一般32位就可以存放下,如果是64位的就使用高低位占用两个也可以存放下,如果是局部的一些对象,比如我们的Object对象,我们只需要存放它的一个引用地址即可。
操作数据栈:存放我们方法执行的操作数的,它就是一个栈,先进后出的栈结构,操作数栈,就是用来操作的,操作的的元素可以是任意的java数据类型,所以我们知道一个方法刚刚开始的时候,这个方法的操作数栈就是空的,操作数栈运行方法就是JVM一直运行入栈/出栈的操作。
动态连接:Java语言特性多态(需要类运行时才能确定具体的方法)。
返回地址:正常返回(调用程序计数器中的地址作为返回)、异常的话(通过异常处理器表<非栈帧中的>来确定)。
下面就结合上面代码的add()栈帧来分析一下内部的执行过程:
public int add();
Code:
0: iconst_2 将int型2入操作数栈
1: istore_1 将操作数栈中的栈帧int型数值,存入局部变量表(下表为1的位置,为0的位置已经被this占用了,当前对象)
2: bipush 6 将int型6入操作数栈
4: istore_2 将操作数栈中的栈帧int型数值,存入局部变量表(下表为2的位置)
5: iload_1 将局部变量表中下标为1的int型数据2入操作数栈
6: iload_2 将局部变量表中下标为2的int型数据6入操作数栈
7: iadd 1)将操作数栈顶的两int型数值出栈 2)相加 3)并将结果压入操作数栈
8: bipush 20 20的值扩展成int入操作数栈
10: imul 1)将操作数栈顶的两int型数值出栈 2)相乘 3)并将结果压入操作数栈
11: istore_3 将操作数栈中的栈帧int型数值,存入局部变量表(下表为3的位置)
12: iload_3 将局部变量表中下标为3的int型数据入操作数栈
13: ireturn 返回在JVM中,基于解释执行的这种方式是基于栈的引擎,这个说的栈,就是操作数栈。Java是解释性语言,解释执行是操作数栈,兼容性好,效率偏低;C语言是寄存器(硬件)运行,移植性差。
3、本地方法栈(线程私有的区域)
本地方法栈跟 Java 虚拟机栈的功能类似,Java 虚拟机栈用于管理 Java 函数的调用,而本地方法栈则用于管理本地方法的调用。但本地方法并不是用 Java 实现的,而是由 C 语言实现的。本地方法栈是和虚拟机栈非常相似的一个区域,它服务的对象是 native 方法。你甚至可以认为虚拟机栈和本地方法栈是同一个区域。虚拟机规范无强制规定,各版本虚拟机自由实现 ,HotSpot直接把本地方法栈和虚拟机栈合二为一(以下会通过HSDB解释原因) 。
4、方法区(线程共享的区域)偏静态的数据,所以不和堆合并成一个区。<=jdk1.7 叫方法区 , >=1.8 叫元空间
方法区主要是用来存放已被虚拟机加载的类相关信息,包括类信息、静态变量、常量、运行时常量池、字符串常量池、java中的全局变量,也就是class的字段,存放在方法区中。
JVM 在执行某个类的时候,必须先加载。在加载类(加载、验证、准备、解析、初始化)的时候,JVM 会先加载 class 文件,而在 class 文件中除了有类的版本、字段、方法和接口等描述信息外,还有一项信息是常量池 (Constant Pool Table),用于存放编译期间生成的各种字面量和符号引用。字面量包括字符串(String a=“b”)、基本类型的常量(final 修饰的变量),符号引用则包括类和方法的全限定名(例如 String 这个类,它的全限定名就是 Java/lang/String)、字段的名称和描述符以及方法的名称和描述符。而当类加载到内存中后,JVM 就会将 class 文件常量池中的内容存放到运行时的常量池中;在解析阶段,JVM 会把符号引用替换为直接引用(对象的索引值)。
例如,类中的一个字符串常量在 class 文件中时,存放在 class 文件常量池中的;在 JVM 加载完类之后,JVM 会将这个字符串常量放到运行时常量池中,并在解析阶段,指定该字符串对象的索引值。运行时常量池是全局共享的,多个类共用一个运行时常量池,class 文件中常量池多个相同的字符串在运行时常量池只会存在一份。
方法区与堆空间类似,也是一个共享内存区,所以方法区是线程共享的。假如两个线程都试图访问方法区中的同一个类信息,而这个类还没有装入 JVM,那么此时就只允许一个线程去加载它,另一个线程必须等待。在 HotSpot 虚拟机、Java7 版本中已经将永久代的静态变量和运行时常量池转移到了堆中,其余部分则存储在 JVM 的非堆内存中,而 Java8 版本已经将方法区中实现的永久代去掉了,并用元空间(class metadata)代替了之前的永久代,并且元空间的存储位置是本地
元空间大小参数:
jdk1.7及以前(初始和最大值):-XX:PermSize;-XX:MaxPermSize;
jdk1.8以后(初始和最大值):-XX:MetaspaceSize; -XX:MaxMetaspaceSize
jdk1.8以后大小就只受本机总内存的限制(如果不设置参数的话)
5、堆(线程共享的区域)偏动态的数据,创建对象数据很频繁
堆是 JVM 上最大的内存区域,我们申请的几乎所有的对象,都是在这里存储的。我们常说的垃圾回收,操作的对象就是堆。堆空间一般是程序启动时,就申请了,但是并不一定会全部使用。随着对象的频繁创建,堆空间占用的越来越多,就需要不定期的对不再使用的对象进行回收。这个在 Java 中,就叫作 GC(Garbage Collection)。
那一个对象创建的时候,到底是在堆上分配,还是在栈上分配呢?这和两个方面有关:对象的类型和在 Java 类中存在的位置。
Java 的对象可以分为基本数据类型和普通对象。
对于普通对象来说,JVM 会首先在堆上创建对象,然后在其他地方使用的其实是它的引用。比如,把这个引用保存在虚拟机栈的局部变量表中。
对于基本数据类型来说(byte、short、int、long、float、double、char),有两种情况。当你在方法体内声明了基本数据类型的对象,它就会在栈上直接分配。其他情况,都是在堆上分配。
堆大小参数:
-Xms:堆的最小值;
-Xmx:堆的最大值;
-Xmn:新生代的大小;
-XX:NewSize;新生代最小值;
-XX:MaxNewSize:新生代最大值;
例如- Xmx256m
6、直接内存(不是JVM的一部分,但可以被JVM使用)
不是虚拟机运行时数据区的一部分,也不是java虚拟机规范中定义的内存区域;如果使用了NIO,这块区域会被频繁使用,在java堆内可以用directByteBuffer对象直接引用并操作;
这块内存不受java堆大小限制,但受本机总内存的限制,可以通过-XX:MaxDirectMemorySize来设置(默认与堆内存最大值一样),所以也会出现OOM异常。
五、从底层深入理解运行时数据区

先看一段代码:-Xms30m -Xmx30m -XX:+UseConcMarkSweepGC -XX:-UseCompressedOops(这四个JVM参数分别是:设置JVM最大内存30M,默认内存30M,使用的CMS垃圾回收器,不使用压缩)
/**
*从底层深入理解运行时数据区
* -Xms30m -Xmx30m -XX:+UseConcMarkSweepGC -XX:-UseCompressedOops
* -Xss1m
*/
public class JVMObject {
public final static String MAN_TYPE = "man"; // 常量
public static String WOMAN_TYPE = "woman"; // 静态变量
public static void main(String[] args)throws Exception {//栈帧
Teacher T1 = new Teacher();//堆中 T1 是局部变量
T1.setName("Mark");
T1.setSexType(MAN_TYPE);
T1.setAge(36);
for (int i=0;i<15;i++){//进行15次垃圾回收
System.gc();//垃圾回收
}
Teacher T2 = new Teacher();
T2.setName("King");
T2.setSexType(MAN_TYPE);
T2.setAge(18);
Thread.sleep(Integer.MAX_VALUE);//线程休眠很久很久
}
}
class Teacher{
String name;
String sexType;
int age;//堆
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSexType() {
return sexType;
}
public void setSexType(String sexType) {
this.sexType = sexType;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}上面代码运行过程的内存的数据分布:
1、启动进程就会去申请内存;
2、上面的两个类:JVMObject.class和Teacher.class会在类加载的时候进入方法区;
3、MAN_TYPE常量和WOMAN_TYPE静态变量会进入方法区;
4、虚拟机栈--main()包装栈帧入栈;
5、main栈帧中的方法执行;
6、执行到main方法的Teacher T1 = new Teacher();时,T1是引用会放到局部变量表中,T1的对象会放到堆内存的Eden区;
7、接下来就是T1.setName("Mark");T1.setSexType(MAN_TYPE);T1.setAge(36);的入操作数栈出操作数栈执行;
8、就是收到调用了15次system.gc();会去堆内存回收垃圾对象,但是T1不会被回收,经历了15次的回收洗礼还没被回收就会进入堆内存的老年代Tenured区;(02:02:54)
9、接下来执行Teacher T2 = new Teacher();T2是引用会放到局部变量表中,T2的对象会放到堆内存的Eden区;
10,、T2.setName("King");T2.setSexType(MAN_TYPE);T2.setAge(18);的入操作数栈出操作数栈执行;

六、内存可视化工具之HSDB
接下来我们就用一个内存可视化工具来看看上面的内存运行时数据区是不是如我们所列步骤执行的:

可以看到我们上面的JVMObject进程一直在运行,没结束。因为我们休眠了很久很久,这时候用HSDB去看他的内存:
1、首先去打开HSDB,进入到 D:\java\jdk\lib


HSDB工具就存在这个jar里面;在这个目录下进入cmd终端:Windows如何进入当前文件的cmd呢?如下图,回车:

然后执行 java -cp .\sa-jdi.jar sun.jvm.hotspot.HSDB 回车就可以打开HSDB;

HSDB工具的可视化界面:

2、到我们的项目下的cmd去,通过 jps 命令找到我们所在进程的进程号 jps:显示电脑上java的进程。

3、把上面的JVMObject进程号绑到HSDB工具上去



假如这时打不开的话,报错:

就去安装jdk的目录下搜sawindbg.dll这个文件,然后复制到报错的目录中D:\java\jre\bin,之后重试上面attach的步骤。
4、小插曲(Android开发)
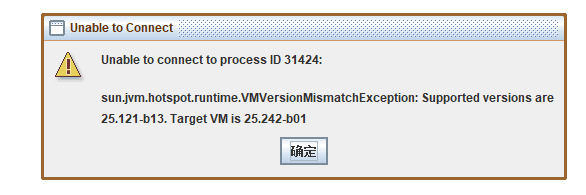
按说java开发者用的工具就是jdk,照着上面的步骤就可以使用HSDB,但是我是Android开发,我的Android studio居然配置的是studio自带的jre/lib,进程运行在studio自带的java运行环境中,所以提示的这个JVM版本不一样


看到没有,这个目录下居然也有这个sa-jdi.jar,而我们上面JVMObject.java这个没有停止的进程运行的是这个jre java运行时环境;你就说日不日,这个地方卡了一小会。
5、继续上面可视化工具HSDB查看运行时内存
这里同一个JVMObject每次运行会有不同的进程号,attach我们的进程号之后,显示当前进程启动的线程,如下图:

找到选中我们程序的main方法主线程,选这个按钮,按钮含义在下面会显示为show the stack memory for the current thread:![]()

这图就是我们的虚拟机栈区的内存情况了,这图包含了很多信息:
1.前面的ox开头的就是内存地址了;
2.虚拟机栈中的main栈帧就是这个:

3.我们上面程序调用了 Thread.sleep(Integer.MAX_VALUE);//线程休眠很久很久,这是个native方法,会打包本地方法栈的栈帧,本地方法栈居然在虚拟机栈中,这就证明上面说的:HotSpot直接把本地方法栈和虚拟机栈合二为一

4、接下来我们通过工具Object Histogram找类对象:需要全路径:com.example.testproject.test.jvmTest

上图就找到了Teacher这个类对象,双击进去就是Teacher对应的new出来的对象:T1和T2

继续选中某个对象,点击Inspect查看对象详情:
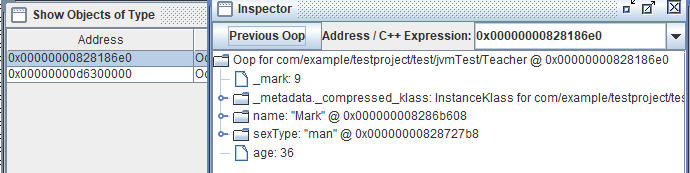
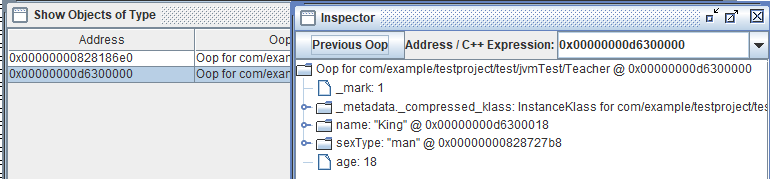
这就是T1和T2两个对象,被我们找到了。那凭什么说这两个对象是存放在堆里面的呢?
通过工具Heap Parameters:
找到堆参数了:如果设置了: -Xms30m -Xmx30m -XX:+UseConcMarkSweepGC -XX:-UseCompressedOops ![]() JVMObject.java运行的虚拟机参数,限制JVM最大内存30M和使用CMS垃圾回收器,会发现新生代和老年代是一段连续的内存地址。注意我下面的截图是没设置这个参数的。
JVMObject.java运行的虚拟机参数,限制JVM最大内存30M和使用CMS垃圾回收器,会发现新生代和老年代是一段连续的内存地址。注意我下面的截图是没设置这个参数的。

可以发现每个区都有个其实地址和终止地址,就是个地址范围,可以发现我们的Mark老师的对象地址为0x00000000828186e0,这个是在老年代,因为Mark老师的T1对象经过了15次gc依然存活。

继续看King老师的T2对象:下图:发现了没有?King老师是新new出来的,放在了Eden区,牛不牛皮?

七、JVM内部做的一些优化
1.编译优化技术----方法内联
方法内联的优化行为,就是把目标方法的代码原封不动的“复制”到调用的方法中,避免真实的方法调用而已。

2.栈的优化技术----栈帧之间数据的共享
在一般的模型中,两个不同的栈帧的内存区域是独立的,但是大部分的JVM在实现中会进行一些优化,使得两个栈帧出现一部分重叠。(主要体现在方法中有参数传递的情况),让下面栈帧的操作数栈和上面栈帧的部分局部变量重叠在一起,这样做不但节约了一部分空间,更加重要的是在进行方法调用时就可以直接公用一部分数据,无需进行额外的参数复制传递了。

八、总结
一句话一键三连:点赞关注+评论。以上就是亲自测试了JVM的内存管理深度剖析。分析了一个JVMObject.java脚本的堆栈内存分配情况。以前书本上的知识都只是概念性的东西,实践才能理解得更深刻。