前言:
大家好,最近几年虽然微服务十分火热,但是仍然有不少人不喜欢微服务,甚至抵制它。其中最主要的原因就是其成本高,难度大。对于难度大,主要是遇到了一些不容易解决的问题,而在这些问题中,其中包括以下三个和测试数据以及测试环境相关的问题:
正文:
一.难以解决的问题:
问题一:测试环境被多个团队共同使用
在大规模的微服务系统中,某些核心服务很多时候都是会被多个团队在共同调用,并且它可能也有多个依赖服务。 而当一个服务的某个测试环境被多个团队(服务)共同使用的时候,主要会存在以下两个困难点。
同一测试数据可能会被不同的团队修改。有些团队通过创建多套测试环境来解决这个问题,但是这样的成本很高。对于很多技术强大的互联网公司,可以通过Docker等技术手段来降低一些成本,但是对于很多传统企业来讲,高成本的多环境很难实施。
同一测试数据可能被其他团队占用,所谓的占用就是一个测试数据一旦不小心被某个人使用了,他可能按自己的场景在进行使用,这个时候你去用它,很可能受到影响而得不到自己想要的结果。
问题二:测试数据准备需要花费大量时间
当测试一些业务不是很复杂的系统时,准备测试数据也许不是一件困难的事情。但是在一些传统行业的复杂系统中,准备测试数据是一项非常困难的事情,比如在银行,保险,通信等复杂系统中。
我曾经测试过一个保险系统,要在测试环境中准备一套数据甚至需要几个小时,因为整个系统的业务非常复杂,数据库设计也非常复杂,而且还是遗留系统,几乎没有人懂得直接操作数据库来准备数据。所以准备数据就必须系统本身来创建。而系统本身是基于MainFrame的,而且UI全部是Console下的UI,操作十分繁琐和复杂,导致创建一套测试数据需要花费很长时间。很多银行和保险公司的核心系统到现在也是保留这样的模式。
因此在这样的传统行业中的遗留系统中,测试数据的准备是一个非常大的问题,
其次很多系统中,测试数据一旦使用了,状态就会改变,从而不能重复使用。所以再次测试就需要重新创建测试数据,这也是一个常见的严重的问题。
问题三:服务部署或网络等问题导致测试环境不稳定以及版本不匹配
这个也是经常会遇到的情况。对于一些稳定而没有什么变化的系统,也许这不是一个问题,但是对于一些正在开发过程中,或者有大量修改或者本身不稳定的系统中,这个问题就十分常见。
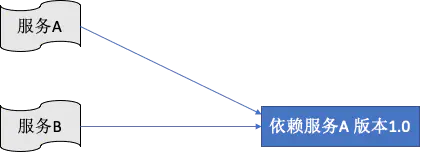
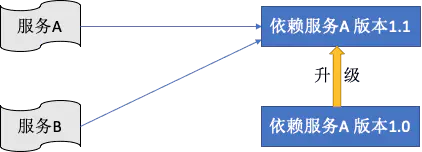
某些服务部署和网络问题,这个容易理解了,就是依赖的服务正在部署。其次是依赖服务的正在调试,而调试的过程中,服务本身的一些状态可能在不停的改变。 或者依赖服务存在Bug,导致服务也存在问题。 最后也许消费端只需要版本1.0依赖服务,但是测试环境中已经部署了2.0版本的服务,导致服务对消费端来讲也不可用了。
二.解决方案:服务虚拟化
可以使用服务虚拟化(Service Virtualization)技术来解决以上这些问题。下图是服务虚拟化的简单示意图:
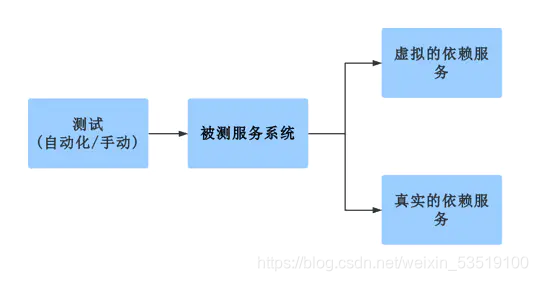
服务虚拟化看起来虽然简单,但是其实现已经做到非常丰富的功能,比如Hoverfly等,从而解决上面那一系列问题。
Hoverfly
Hoverfly是一个开源免费(Apache 2)的服务虚拟化的一个工具,其虚拟数据是可以复用的Json格式的Simulation。它是基于 Go开发的,轻巧,高效。同时支持Python和Java进行扩展,也提供REST API来对其进行控制。并且暂时提供模拟网络延迟,随机错误和限定速率。但是其支持的协议有限,暂时只支持HTTP和HTTPS。但是其最重要的是其支持六种工作模型,它们分别是:Capture模型,Simulate模型,Spy模型,Synthesize模型,Modify模型,Diff模型。
通过这六种模型,基本可以实现服务虚拟化的各种功能。首先,通过Capture模型可以获取到在手工测试和系统正常使用的情况下,各种服务的交互数据,然后再进行分析和修改,可以获得更多类型的数据。
将这些数据通过Spy、Synthesize、Modify和Simulate模型进行不同类型的服务虚拟。不同的团队可以根据基础类型数据快速定制自己团队的私有虚拟数据集,并且还可以根据不同版本的服务,定制不同版本的虚拟数据集,从而隔离了不同版本服务之间的数据,避免了不同团队之间的的测试数据冲突。
三.那么如何利用服务虚拟化跨越测试数据障碍?
1.利用服务虚拟化克服数据成本问题
无论怎样,数据都是一个成本问题,因为它拖累了你的速度。通过使用服务虚拟化,你不仅可以控制依赖应用程序的行为和功能,以达到稳定测试环境的目的,而且你可以完全控制这些依赖的数据源,并提供你当天工作所需的任何数据。此时,规则发生了变化,因为你现在不仅控制了数据,还控制了逻辑。你可以创建按照你希望的方式行事的服务,而不是严格遵守它们的正常行为模式。
在之前的一篇文章中,我讨论了缺陷虚拟化,它有相同的基本原则。但之前我们讨论的是服务逻辑。这篇文章将进行下一步,并讨论数据控制。在我们开始的时候,让我们关注一下当前测试人员和开发人员每天都要面对的数据挑战。
2.开发者生活中的典型数据日
在应用程序开发初期,由于服务的全部功能尚未实现,因此测试所需的数据通常比较简单。随着开发的不断增加功能,测试的成熟度也会增加,数据的复杂度也会增加。
举个例子,我们用我之前文章中的例子——假设我是一家航空公司,正在开发机票页面的功能。我需要验证用户是否能买到机票,根据航班在未来多远的时间,用户会得到几个响应中的一个,随着时间的临近,这些响应会发生变化。在开发之初,我可以简单的生成一堆复杂的数据,其中有未来3个月的航班,这样我就可以做我目前需要的所有测试。但当然问题是,我只是点燃了一颗定时炸弹的引线。3个月后,这些美丽的数据就会过期,而我有可能已经忘记了它。突然间,我所有的测试都会开始失败,而时间恰恰不对,因为即将发布,我根本没有时间重新生成数据…听起来很熟悉?
3.锻造一条可持续发展之路
通过在开发过程的早期引入服务虚拟化,你可以为提供这些数据挑战的解决方案打下基础。一个虚拟服务的数据可以来自许多地方,但在一开始,简单的虚拟服务从固定数据开始。你创建这些“固定资产”或mock来解决what-if场景测试阶段的问题,并使事情非常简单。这里的想法是,“我只需要一个服务,它将用这个特定的有效载荷进行响应”。
随着虚拟服务的成熟,有必要将数据和服务分开,这样如果你想在模拟中添加逻辑,你实际上不必打开虚拟服务来操作数据。事实上,成熟的用户创建虚拟服务的方式是让数据源处理大部分的逻辑。然后,他们可以将数据源交给测试人员或测试数据管理团队来插入这个服务未来可能需要的任何数据。向服务添加新功能就像向数据源添加一行一样简单。这使得虚拟化的工作可以共享,一个虚拟服务可以容纳多个团队。虚拟服务成为活的有机体,可以根据需要成长和改变。
4.这些数据从哪里来?
我们记录的数据并不是来自于生产,这可以保护我们在低级环境中不被数据泄露。这些数据面临的挑战是,由于它不是来自生产,所以它不那么完整或最新。这时,数据的生成和操作就成为服务虚拟化的一个强大功能。
不存在的数据可以用简单的生成数据来补充,来完成我们所需要的数据。在我的航空公司的例子中,回复中的航班日期可以一直是今天的日期,偏移3个月。通过使用数据生成,这个任务变得微不足道。
我们可以通过提供动态数据来管理任何“非定义的”请求/响应关系,继续按摩和操作数据。这些是静态数据集中永远不可能存在的关系类型。在航空公司的例子中,假设当向下游组件发出请求时,它提供了用户的当前位置,这将在响应中作为出发地使用。由于我们的测试用例会不断变化,所以一个真实的服务必须维护所有的当前位置,这样才能在响应中提供这些位置。通过使用虚拟服务,你不需要维护所有的位置,你可以简单地动态返回用户的当前位置作为出发城市。
最后,使用负数据可以静态提供,也可以插入到数据源中,以方便负数据或异常测试。例如,在我的航空公司例子中,这将是插入一个随机取消或延迟的航班,以验证用户在出发去机场之前得到通知。
四.写在最后:
所有的失败都是为成功做准备。抱怨和泄气,只能阻碍成功向自己走来的步伐。放
下抱怨,心平气和地理解失败,无疑是智者的姿态。抱怨无法改变现状,拼搏才能带来希望。真的金子,只要自己不把自己埋没,只要- -心想着闪光,就总有闪光的那一天。所以朋友当你疲惫的时候,不妨稍微休息一下,但是不要忘了,在休息之后,继续背上行囊,大步向前,相信你不忘初心,一路坚持,最终以定可以开出属于自己的一朵花儿,加油。
在这里推荐一个我自己创建的软件测试交流群,qq:642830685,群中群中会不定期的分享软件测试资源,测试面试题以及行业资讯,大家可以在群中积极交流技术。愿你我相遇,皆有所获! 欢迎关注微信公众号:程序媛一菲,下面这些硬核资源就是你的了。