1、Thread类的sleep()方法和对象的wait()方法都可以让线程暂停执行,它们有什么区别?
答:sleep()方法(休眠)是线程类(Thread)的静态方法,调用此方法会让当前线程暂停执行指定的时间,将执行机会(CPU)让给其他线程,但是对象的锁依然保持,因此休眠时间结束后会自动恢复(线程回到就绪状态,请参考第6题中的线程状态转换图)。wait()是Object类的方法,调用对象的wait()方法导致当前线程放弃对象的锁(线程暂停执行),进入对象的等待池(wait pool),只有调用对象的notify()方法(或notifyAll()方法)时才能唤醒等待池中的线程进入等锁池(lock pool),如果线程重新获得对象的锁就可以进入就绪状态。
java中定义的线程状态
public enum State {
/**
* Thread state for a thread which has not yet started.
*/
NEW,
/**
* Thread state for a runnable thread. A thread in the runnable
* state is executing in the Java virtual machine but it may
* be waiting for other resources from the operating system
* such as processor.
*/
RUNNABLE,
/**
* Thread state for a thread blocked waiting for a monitor lock.
* A thread in the blocked state is waiting for a monitor lock
* to enter a synchronized block/method or
* reenter a synchronized block/method after calling
* {@link Object#wait() Object.wait}.
*/
BLOCKED,
/**
* Thread state for a waiting thread.
* A thread is in the waiting state due to calling one of the
* following methods:
* <ul>
* <li>{@link Object#wait() Object.wait} with no timeout</li>
* <li>{@link #join() Thread.join} with no timeout</li>
* <li>{@link LockSupport#park() LockSupport.park}</li>
* </ul>
*
* <p>A thread in the waiting state is waiting for another thread to
* perform a particular action.
*
* For example, a thread that has called <tt>Object.wait()</tt>
* on an object is waiting for another thread to call
* <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on
* that object. A thread that has called <tt>Thread.join()</tt>
* is waiting for a specified thread to terminate.
*/
WAITING,
/**
* Thread state for a waiting thread with a specified waiting time.
* A thread is in the timed waiting state due to calling one of
* the following methods with a specified positive waiting time:
* <ul>
* <li>{@link #sleep Thread.sleep}</li>
* <li>{@link Object#wait(long) Object.wait} with timeout</li>
* <li>{@link #join(long) Thread.join} with timeout</li>
* <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li>
* <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li>
* </ul>
*/
TIMED_WAITING,
/**
* Thread state for a terminated thread.
* The thread has completed execution.
*/
TERMINATED;
}
2、线程的sleep()方法和yield()方法有什么区别?
join:当某个线程拥有cpu资源时,它决定把资源让给另一个特定的线程。b.join();a会等待b执行完成后再继续向下执行a.
yield:把当前线程的执行权交出去,把当前线程由running变成runnable状态。当某个线程获得cpu时,它让出这个机会,给与它优先级相同或者更高的线程,自己也可能获得机会。
答:
① sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
② 线程执行sleep()方法后转入阻塞(blocked)状态,而执行yield()方法后转入就绪(ready)状态;
③ sleep()方法声明抛出InterruptedException,而yield()方法没有声明任何异常;
④ sleep()方法比yield()方法(跟操作系统CPU调度相关)具有更好的可移植性。
3、当一个线程进入一个对象的synchronized方法A之后,其它线程是否可进入此对象的synchronized方法B?
答:不能。其它线程只能访问该对象的非同步方法,同步方法则不能进入。因为非静态方法上的synchronized修饰符要求执行方法时要获得对象的锁,如果已经进入A方法说明对象锁已经被取走,那么试图进入B方法的线程就只能在等锁池(注意不是等待池哦)中等待对象的锁。
4、请说出与线程同步以及线程调度相关的方法。
答:
- wait():使一个线程处于等待(阻塞)状态,并且释放所持有的对象的锁;
- sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要处理InterruptedException异常;
- notify():唤醒一个处于等待状态的线程,当然在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且与优先级无关;
- notityAll():唤醒所有处于等待状态的线程,该方法并不是将对象的锁给所有线程,而是让它们竞争,只有获得锁的线程才能进入就绪状态;
补充:Java 5通过Lock接口提供了显式的锁机制(explicit lock),增强了灵活性以及对线程的协调。Lock接口中定义了加锁(lock())和解锁(unlock())的方法,同时还提供了newCondition()方法来产生用于线程之间通信的Condition对象;此外,Java 5还提供了信号量机制(semaphore),信号量可以用来限制对某个共享资源进行访问的线程的数量。在对资源进行访问之前,线程必须得到信号量的许可(调用Semaphore对象的acquire()方法);在完成对资源的访问后,线程必须向信号量归还许可(调用Semaphore对象的release()方法)。
5、举例说明同步和异步。
答:如果系统中存在临界资源(资源数量少于竞争资源的线程数量的资源),例如正在写的数据以后可能被另一个线程读到,或者正在读的数据可能已经被另一个线程写过了,那么这些数据就必须进行同步存取(数据库操作中的排他锁就是最好的例子)。当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就应该使用异步编程,在很多情况下采用异步途径往往更有效率。事实上,所谓的同步就是指阻塞式操作,而异步就是非阻塞式操作。
同步就是整个处理过程顺序执行,当各个过程都执行完毕,并返回结果。是一种线性执行的方式,执行的流程不能跨越。一般用于流程性比较强的程序,比如用户登录,需要对用户验证完成后才能登录系统。
异步则是只是发送了调用的指令,调用者无需等待被调用的方法完全执行完毕;而是继续执行下面的流程。是一种并行处理的方式,不必等待一个程序执行完,可以执行其它的任务,比如页面数据加载过程,不需要等所有数据获取后再显示页面。
很多时候为了提高执行效率,可以将主线程中的任务分解成若干个子任务由子线程并发执行,如果主线程需要等待子线程全部执行完成再结束,那么主线程在子线程执行过程中需要阻塞;
如果主线程不需要等待子线程执行完成就可以提前结束,那么主线程在子线程执行过程中不需要阻塞,也就会出现主线程已跑完,子线程还在跑。 需要等待就要阻塞线程执行,不需要等待就不用了阻塞线程执行,就是非阻塞。
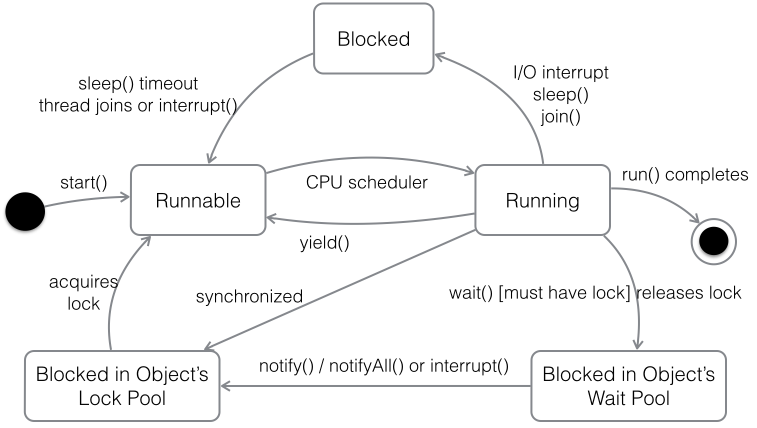
6、线程的基本状态以及状态之间的关系?
其中Running表示运行状态,Runnable表示就绪状态(万事俱备,只欠CPU),Blocked表示阻塞状态,阻塞状态又有多种情况,可能是因为调用wait()方法进入等待池,也可能是执行同步方法或同步代码块进入等锁池,或者是调用了sleep()方法或join()方法等待休眠或其他线程结束,或是因为发生了I/O中断。
7、简述synchronized 和java.util.concurrent.locks.Lock的异同?
答:Lock是Java 5以后引入的新的API,和关键字synchronized相比主要相同点:Lock 能完成synchronized所实现的所有功能;主要不同点:Lock有比synchronized更精确的线程语义和更好的性能,而且不强制性的要求一定要获得锁。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且最好在finally 块中释放(这是释放外部资源的最好的地方)。Lock是api层面的,synchronized是jvm层次的,有优化的可能。
8、Java中如何实现序列化,有什么意义?
答:序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决对象流读写操作时可能引发的问题(如果不进行序列化可能会存在数据乱序的问题)。
要实现序列化,需要让一个类实现Serializable接口,该接口是一个标识性接口,标注该类对象是可被序列化的,然后使用一个输出流来构造一个对象输出流并通过writeObject(Object)方法就可以将实现对象写出(即保存其状态);如果需要反序列化则可以用一个输入流建立对象输入流,然后通过readObject方法从流中读取对象。序列化除了能够实现对象的持久化之外,还能够用于对象的深度克隆。
9、Java中有几种类型的流?
答:字节流和字符流。字节流继承于InputStream、OutputStream,字符流继承于Reader、Writer。在java.io 包中还有许多其他的流,主要是为了提高性能和使用方便。关于Java的I/O需要注意的有两点:一是两种对称性(输入和输出的对称性,字节和字符的对称性);二是两种设计模式(适配器模式和装饰模式)。
10、XML文档定义有几种形式?它们之间有何本质区别?解析XML文档有哪几种方式?
答:XML文档定义分为DTD和Schema两种形式,二者都是对XML语法的约束,其本质区别在于Schema本身也是一个XML文件,可以被XML解析器解析,而且可以为XML承载的数据定义类型,约束能力较之DTD更强大。对XML的解析主要有DOM(文档对象模型,Document Object Model)、SAX(Simple API for XML)和StAX(Java 6中引入的新的解析XML的方式,Streaming API for XML),其中DOM处理大型文件时其性能下降的非常厉害,这个问题是由DOM树结构占用的内存较多造成的,而且DOM解析方式必须在解析文件之前把整个文档装入内存,适合对XML的随机访问(典型的用空间换取时间的策略);SAX是事件驱动型的XML解析方式,它顺序读取XML文件,不需要一次全部装载整个文件。当遇到像文件开头,文档结束,或者标签开头与标签结束时,它会触发一个事件,用户通过事件回调代码来处理XML文件,适合对XML的顺序访问;顾名思义,StAX把重点放在流上,实际上StAX与其他解析方式的本质区别就在于应用程序能够把XML作为一个事件流来处理。将XML作为一组事件来处理的想法并不新颖(SAX就是这样做的),但不同之处在于StAX允许应用程序代码把这些事件逐个拉出来,而不用提供在解析器方便时从解析器中接收事件的处理程序。
11、Statement和PreparedStatement有什么区别?哪个性能更好?
答:与Statement相比,①PreparedStatement接口代表预编译的语句,它主要的优势在于可以减少SQL的编译错误并增加SQL的安全性(减少SQL注入攻击的可能性);②PreparedStatement中的SQL语句是可以带参数的,避免了用字符串连接拼接SQL语句的麻烦和不安全;③当批量处理SQL或频繁执行相同的查询时,PreparedStatement有明显的性能上的优势,由于数据库可以将编译优化后的SQL语句缓存起来,下次执行相同结构的语句时就会很快(不用再次编译和生成执行计划)。
补充:为了提供对存储过程的调用,JDBC API中还提供了CallableStatement接口。存储过程(Stored Procedure)是数据库中一组为了完成特定功能的SQL语句的集合,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。虽然调用存储过程会在网络开销、安全性、性能上获得很多好处,但是存在如果底层数据库发生迁移时就会有很多麻烦,因为每种数据库的存储过程在书写上存在不少的差别。
什么是SQL注入:
通过sql语句的拼接达到无参数查询数据库数据目的的方法。
如将要执行的sql语句为 select * from table where name = “+appName+”,利用appName参数值的输入,来生成恶意的sql语句,如将[‘or’1’=’1’] 传入可在数据库中执行。
因此可以采用PrepareStatement来避免Sql注入,在服务器端接收参数数据后,进行验证,此时PrepareStatement会自动检测,而Statement不 行,需要手工检测。
12、使用JDBC操作数据库时,如何提升读取数据的性能?如何提升更新数据的性能?
答:要提升读取数据的性能,可以指定通过结果集(ResultSet)对象的setFetchSize()方法指定每次抓取的记录数(典型的空间换时间策略);要提升更新数据的性能可以使用PreparedStatement语句构建批处理,将若干SQL语句置于一个批处理中执行。
13、在进行数据库编程时,连接池有什么作用?
答:由于创建连接和释放连接都有很大的开销(尤其是数据库服务器不在本地时,每次建立连接都需要进行TCP的三次握手,释放连接需要进行TCP四次握手,造成的开销是不可忽视的),为了提升系统访问数据库的性能,可以事先创建若干连接置于连接池中,需要时直接从连接池获取,使用结束时归还连接池而不必关闭连接,从而避免频繁创建和释放连接所造成的开销,这是典型的用空间换取时间的策略(浪费了空间存储连接,但节省了创建和释放连接的时间)。池化技术在Java开发中是很常见的,在使用线程时创建线程池的道理与此相同。基于Java的开源数据库连接池主要有:C3P0、Proxool、DBCP、BoneCP、Druid等。
补充:在计算机系统中时间和空间是不可调和的矛盾,理解这一点对设计满足性能要求的算法是至关重要的。大型网站性能优化的一个关键就是使用缓存,而缓存跟上面讲的连接池道理非常类似,也是使用空间换时间的策略。可以将热点数据置于缓存中,当用户查询这些数据时可以直接从缓存中得到,这无论如何也比数据库中查询块。
数据库链接池和线程池的区别?
连接池:
1、连接池是面向数据库连接的
2、连接池是为了优化数据库连接资源
3、连接池有点类似在客户端做优化
线程池:
1.、线程池是面向后台程序的
2、线程池是是为了提高内存和CPU效率
3、线程池有点类似于在服务端做优化
14、什么是DAO模式?
答:DAO(Data Access Object)顾名思义是一个为数据库或其他持久化机制提供了抽象接口的对象,在不暴露底层持久化方案实现细节的前提下提供了各种数据访问操作。在实际的开发中,应该将所有对数据源的访问操作进行抽象化后封装在一个公共API中。用程序设计语言来说,就是建立一个接口,接口中定义了此应用程序中将会用到的所有事务方法。在这个应用程序中,当需要和数据源进行交互的时候则使用这个接口,并且编写一个单独的类来实现这个接口,在逻辑上该类对应一个特定的数据存储。DAO模式实际上包含了两个模式,一是Data Accessor(数据访问器),二是Data Object(数据对象),前者要解决如何访问数据的问题,而后者要解决的是如何用对象封装数据。
15、监听器有哪些作用和用法?
答:Java Web开发中的监听器(listener)就是application、session、request三个对象创建、销毁或者往其中添加修改删除属性时自动执行代码的功能组件,如下所示:
- ①ServletContextListener:对Servlet上下文的创建和销毁进行监听。
- ②ServletContextAttributeListener:监听Servlet上下文属性的添加、删除和替换。
- ③HttpSessionListener:对Session的创建和销毁进行监听。
补充:session的销毁有两种情况:1、session超时(可以在web.xml中通过/标签配置超时时间);2、通过调用session对象的invalidate()方法使session失效。 - ④HttpSessionAttributeListener:对Session对象中属性的添加、删除和替换进行监听。
- ⑤ServletRequestListener:对请求对象的初始化和销毁进行监听。
- ⑥ServletRequestAttributeListener:对请求对象属性的添加、删除和替换进行监听。
16、web.xml 的作用?
答:用于配置Web应用的相关信息,如:监听器(listener)、过滤器(filter)、 Servlet、相关参数、会话超时时间、安全验证方式、错误页面等。
17、请对以下Java EE中的名词进行解释
答:
- 1.容器:容器为Java EE应用程序组件提供了运行时支持。容器提供了一份从底层Java EE API到应用程序组件的联合视图。Java EE应用程序组件不能直接地与其它Java EE应用程序组件交互。它们通过容器的协议和方法来达成它们之间以及它们与平台服务之间的交互。在应用程序组件和Java EE服务之间插入一个容器,这允许该容器透明地为组件注入必须的服务,例如声明式事务管理,安全检查,资源池和状态管理。
- 2.资源适配器:资源适配器是一个系统级的组件,它通常实现了对外部资源管理器的网络连接。资源适配器能够扩展Java EE平台的功能。这只需要实现一个Java EE标准服务API(例如JDBC驱动程序),或者定义并实现一个能连接到外部应用程序系统的资源适配器就可以达到。资源适配器也可以提供完整的本地或本地资源的服务。资源适配器接口通过Java EE服务供应商接口(Java EE SPI)来连接Java EE平台。使用Java EE SPI连接到Java EE平台的资源适配器可以和所有的Java EE产品协同工作。
- 3.JNDI(Java Naming & Directory Interface):Java命名目录接口,主要提供的功能是:提供一个目录系统,让其它各地的应用程序在其上面留下自己的索引,从而满足快速查找和定位分布式应用程序的功能。
- 4.JMS(Java Message Service):Java消息服务是用于消息发送的标准API,它支持可靠的“点对点”消息发送和“发布-订阅”模型。Java EE规范要求JMS供应商同时实现“点对点”消息发送和”发布/订阅”型消息发送。
- 5.JTA(Java Transaction API):Java 事务编程接口。Java事务API由两部分组成:①一个应用程序级的边界划分接口,容器和应用程序组件用它来划分事务边界;②一个介于事务管理器和资源管理器之间的Java EE SPI级接口。
- 6.JPA(Java Persistence API):Java持久化API是用于持久化和对象/关系映射管理的标准API。通过使用一个Java域模型来管理关系型数据库,Java EE规范为应用程序开发者提供了一种对象/关系映射功能。Java EE必须对Java持久化API提供支持。它也可以用在Java SE环境中。
- 7.JAF(JavaBean Activation FrameWork):JAF API提供了一个框架来处理不同MIME类型的数据,它们源于不同的格式和位置。JavaMail API使用了JAF API。JAF API包含在Java SE中,因此它可以被Java EE应用程序使用。
- 8.JAAS(Java Authentication and Authorization Service):使服务能够基于用户进行验证和实施访问控制。它实现了一个Java版的标准的的Plugable Authentication Module (PAM)框架,并支持基于用户的授权。Java Authorization Service Provider Contract for Containers (JACC) 定义了Java EE应用程序服务器和授权服务提供方之间的协议,允许将自定义的授权服务提供方插入任何Java EE产品中。
- 9.JMX(Java Management Extension):Java平台企业版管理规范中定义了一种API,通过一种特殊的管理型EJB来管理Java EE服务器。JMX API也提供了一些管理上的支持。
18、抽象类能否被实例化 ?抽象类的作用是什么?
答:抽象类不能被实例化;抽象类通常不是由程序员定义的,而是由项目经理或模块设计人设计的。抽象类通常是为了规范抽象方法必须要重写,不然没法用。作为模块设计者,可以设计普通方法让程序员直接调用,设计一些抽象方法让程序员覆盖,实现具体的逻辑。
19、HashTable, HashMap,TreeMap区别?
答:
1、HashTable线程同步,HashMap非线程同步。
2、HashTable不允许<键,值>有空值,HashMap允许<键,值>有空值。
3、HashTable使用Enumeration,HashMap使用Iterator。
4、HashTable中hash数组的默认大小是11,增加方式的old*2+1,HashMap中hash数组的默认大小是16,增长方式一定是2的指数倍。
5、TreeMap能够把它保存的记录根据键排序,默认是按升序排序。
20、sendRedirect(重定向), foward(转发)区别
答:转发是服务器行为,重定向是客户端行为。
转发过程:客户浏览器发送http请求->web服务器接受此请求->调用内部的一个方法在容器内部完成请求处理和转发动作->将目标资源 发送给客户;在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。
重定向过程:客户浏览器发送http请求->web服务器接受后发送302状态码响应及对应新的location给客户浏览器->客户浏览器发现 是302响应,则自动再发送一个新的http请求,请求url是新的location地址->服务器根据此请求寻找资源并发送给客户。在这里location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的 路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。
21、关于Cache(Ehcache,Memcached)
22、反射讲一讲,主要是概念,都在哪需要反射机制,反射的性能,如何优化
答:
(1)反射机制的定义
是在运行状态中,对于任意的一个类,都能够知道这个类的所有属性和方法,对任意一个对象都能够通过反射机制调用一个类的任意方法,这种动态获取类信息及动态调用类对象方法的功能称为java的反射机制。
反射的作用:
1、动态地创建类的实例,将类绑定到现有的对象中,或从现有的对象中获取类型。
2、应用程序需要在运行时从某个特定的程序集中载入一个特定的类
(2)使用场景
情景一:不得已而为之
有的类是我们在编写程序的时候无法使用new一个对象来实例化对象的。例如:
- 调用的是来自网络的二进制.class文件,而没有其.java代码;
- 注解 - 注解本身仅仅是起到标记作用,它需要利用反射机制,根据注解标记去调用注解解释器,执行行为。如果没有反射机制,注解并不比注释更有用。
情景二:动态加载(可以最大限度的体现Java的灵活性,并降低类的耦合性:多态)
有的类可以在用到时再动态加载到jvm中,这样可以减少jvm的启动时间,同时更重要的是可以动态的加载需要的对象(多态)。例如:
- 动态代理 - 在切面编程(AOP)中,需要拦截特定的方法,通常,会选择动态代理方式。这时,就需要反射技术来实现了。
情景三:避免将程序写死到代码里
因为java代码是先通过编译器将.java文件编译成.class的二进制字节码文件,因此如果我们使用new Person()来实例化对象person会出现的问题就是如果我们希望更换person的实例对象,就要在源代码种更改然后重新编译再运行,但是如果我们将person的实例对象类名等信息编写在配置文件中,利用反射的Class.forName(className)方法来实例化java对象(因为实例化java对象都是根据全限定名查找到jvm内存中的class对象,并根据class对象中的累信息实例化得到java对象,因此xml文件中只要包含了权限定类名就可以通过反射实例化java对象),那么我们就可以更改配置文件,无需重新编译。例如:
- 开发通用框架 - 反射最重要的用途就是开发各种通用框架。很多框架(比如 Spring)都是配置化的(比如通过 XML 文件配置 JavaBean、Filter 等),为了保证框架的通用性,它们可能需要根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射——运行时动态加载需要加载的对象
(3)反射的缺点
- 性能开销 - 由于反射涉及动态解析的类型,因此无法执行某些 Java 虚拟机优化。因此,反射操作的性能要比非反射操作的性能要差,应该在性能敏感的应用程序中频繁调用的代码段中避免。
- 破坏封装性 - 反射调用方法时可以忽略权限检查,因此可能会破坏封装性而导致安全问题。
- 内部曝光 - 由于反射允许代码执行在非反射代码中非法的操作,例如访问私有字段和方法,所以反射的使用可能会导致意想不到的副作用,这可能会导致代码功能失常并可能破坏可移植性。反射代码打破了抽象,因此可能会随着平台的升级而改变行为。
23、写代码分别使得JVM的堆、栈和持久代发生内存溢出(栈溢出)
一个死循环 递归调用就 可以栈溢出。建好多对象实例放入ArrayList里可以堆溢出。持久代溢出可以新建很多 ClassLoader 来装载同一个类文件。
因为方法区是保存类的相关信息的,所以当我们加载过多的类时就会导致方法区溢出。CGLIB同样会缓存代理类的Class对象,但是我们可以通过配置让它不缓存Class对象,这样就可以通过反复创建代理类达到使方法区溢出的目的。
package com.cdai.jvm.overflow;
import java.lang.reflect.Method;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class MethodAreaOverflow2 {
static class OOMObject {
}
public static void main(String[] args) {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method,
Object[] args, MethodProxy proxy) throws Throwable {
return method.invoke(obj, args);
}
});
OOMObject proxy = (OOMObject) enhancer.create();
System.out.println(proxy.getClass());
}
}
}24、一道阿里面试题分析
public class MyStack {
private List<String> list = new ArrayList<String>();
public synchronized void push(String value) {
synchronized (this) {
list.add(value);
notify();
}
}
public synchronized String pop() throws InterruptedException {
synchronized (this) {
if (list.size() <= 0) {
wait();
}
return list.remove(list.size() - 1);
}
}
} list.remove(list.size() - 1);这句代码有可能引发数组下标越界
原因:
假设其中一种情形呵!出问题的情形可能很多,但原理都差不多。下面的标号代表程序时序的先后顺序。
1,初始化时list的值为0,然后线程1调用了pop,于是被wait了,然后释放了锁。
2,线程2调用push,在notify之前有线程3调用pop(记住这时候线程1还没有被唤醒,还在wait住),此时线程3会因为等待锁而挂起,或自旋,反正就是在等待锁可用。3,然后线程2继续往下执行,notify被执行(但这时候线程1是不会唤醒的,因为锁还在线程2占用),线程2退出push方法,释放内置锁,此时,线程1和线程3都在内置锁等待队列里面。由于synchronized是没法保证线程竞争的公平性,所以线程1和线程3都可能得到锁。
4,假设线程1竞争到了锁,不会出问题,正常去除list值,然后remove,执行完后线程3执行,同样被wait住。
5,假设线程3竞争到了锁,问题来了,线程3会判断到list的size不为0,于是remove,所以list的size就为0了,然后线程 3释放锁,这时候,线程1就得到锁,于是从wait中醒来,继续执行,然后直接调用list的remove,由于list的size=0,那么remove(-1),越界错误就产生了。
还有同学说两个线程都在wait处等候也会出问题,其实不会出问题的,因为是调用的notify而不是notifyAll,如果是调用notifyAll那么也会出同样的问题。
至于改进:看到这个题目我就很纳闷,为什么要用双重锁,好像没有必要双重锁。我第一眼看到双重锁的时候就在想,出题者是不是在模拟一个套管死锁,我也确实为找这个死锁付出了一些时间。但是这个双重检查都是可重入的锁,都是对于this对象上的锁。所以不存在套管死锁。
改进1,——最小代码改动,就在remove之前再检查list.size==0
改进2,——去掉push和pop方法内的第二重锁检查,我确实没有发现这个锁会有什么用,反而耗性能。当然还要有方案1的判断。
改进3,——重新设计,如果是我来设计这么一个生产者,消费者模式。我更愿意用LinkedBlockingQueue,它有take方法阻塞消费者直到队列可用。而且还有offer方法阻塞生产者直到队列可以插入,可以有效的阻止OOM。