在linux 上使用工具播放音频文件时,有两种音频数据拷贝的方式:
一、Memory mapped I/O
就是把磁盘上的file映射到内存上,当我们从内存上fetch byte时,对应的file就被读取。同样的,当我们在内存上存储字节的时候,对应的file就被写入。这就让我们不需通过read和write系统调用而去操作I/O。
mmap内存映射建立一段可以被多个进程读写的内存段。共享内存。
mmap函数作用是告诉内核把给定的文件file映射到内存的一块空间,mmap函数原型如下:
#include <sys/mmam.h>
void *mmap(void *addr, size_t len, int prot,int flag, int fields, off_t off);
函数返回值就是the starting address of the mapped area。
参数addr代表被映射到内存的地址。一般把addr设置成为0,让操作系统自己去选择该映射到内存的那个地址上。
参数fields就是要被映射的文件的文件描述符。在把这个文件映射到内存空间之前,我们必须先open这个文件描述符。
参数len代表the number of bytes to map。
参数off is the starting offset in the file of the bytes to map。
参数prot的值和代表的含义如下表格,prot用于设置内存段的访问权限

参数flag代表内存映射区的属性:
MAP_FIXED 内存段必须位于addr指定的位置
MAP_SHARED 内存段是共享的,对内存段的修改保存到磁盘文件中
MAP_PRIVATE 内存段是私有的,对内存段的修改只对本进程内部有效
二、Read/Write I/O
1. 文件I/O—read函数
在linux系统中最常用,基本的读写文件I/O的系统调用就是read函数和write函数。
read函数表示从fd指向的文件中读取cont个字节的数据。
函数原型:
#include<unistd.h>
ssize_t read(int fd, void *buf, size_t count);
参数说明:
int fd : 文件描述符,指向要读取数据的文件
void *buf : 用于存放读取的数据的缓存开始地址
size_t count : 读取到缓冲区的字节数
size_t你可以理解成 unsigned int,而 ssize_t 你可以理解成 signed int。
返回值说明:
成功返回实际读取的字节数,出错返回-1并设置errno,如果在调read之前已到达文件末尾,则这次read返回0。
2. 文件I/O—write函数
write函数表示将数据写入到fd指定的一个已打开的文件中。
函数原型:
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
参数说明:
int fd : 文件描述符,指向要写入数据的文件
void *buf : 写缓存的开始地址
size_t count : 写缓存的字节大小
返回值说明:
write函数写入成功(ssize_t)返回值是每次实际写入的无符号字节数,如果write什么都没写则返回0,另外,write函数的返回值可能小于count参数,原因是可能磁盘数据已满,write只写入了“部分”数据到磁盘中。如果write出错则返回-1,并设置errno。
注意几点:
-
从标准输入设备或网络设备读取数据,read在读取数据时默认情况下没有数据的话,它会一直等待数据到来,如果一直没有数据该进程会被操作系统标识睡眠
-
从标准输入设备或网络设备写入数据,write函数默认情况下缓冲区写满的话会一直阻塞,除非缓冲区中的数据被读取,否则该进程会被操作系统标识睡眠,让出cpu
3. 文件I/O缓冲
当调用read和write这些系统调用来操作磁盘文件时,系统并不保证调用write成功后,数据已经写入磁盘,因为系统为了减少对磁盘的物理操作,出于速度和效率的考虑,会对文件数据进行缓存。
4. 实验
下面通过一个实验来说明这种情况,使用系统函数(read,write)和标库函数(fgetc,fputc)同样对一个文件一次只读写一个字节,看看谁的效率更高。
dict.txt文件中的数据非常大。
标准库函数实现文件读写实验:get_put程序
#include <stdio.h>
#include <stdlib.h>
//putc和getc标准库函数每次读写一个字符
int main(void)
{
FILE *fp, *fp_out;
int n;
fp = fopen(“dict.txt”, “r”);
if(fp == NULL){
perror(“fopen error”); //perror是一个错误处理函数
exit(1);
}
fp_out = fopen(“test.txt”, “w”);
if(fp == NULL){
perror(“fopen error”);
exit(1);
}
//从dict.txt文件中读取数据,然后写入到test.txt文件中
while((n = fgetc(fp)) != EOF){
fputc(n, fp_out);
}
fclose(fp);
fclose(fp_out);
return 0;
}
系统函数实现文件读写实验:read_write程序
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <errno.h>
#define N 1
int main(int argc, char *argv[])
{
int fd, fd_out;
int n;
char buf[N];
fd = open(“dict.txt”, O_RDONLY);
if(fd < 0){
perror(“open dict.txt error”);
exit(1);
}
fd_out = open(“test.txt”, O_WRONLY|O_CREAT|O_TRUNC, 0644);
if(fd < 0){
perror(“open test.txt error”);
exit(1);
}
//调用read和write每次只读写一字节
//从dict.txt文件中读取数据,写入test.txt文件中
while((n = read(fd, buf, N))){
if(n < 0){
perror(“read error”);
exit(1);
}
write(fd_out, buf, n);
}
close(fd);
close(fd_out);
return 0;
}
get_put使用fgetc,fputc标准库函数读写文件,read_write使用read,write系统函数读写文件,通过对比两个程序的执行时间发现,使用系统函数读写速度反而比标准库函数读写速度要慢很多,原因就在于“预读入,缓输出”机制,为了方便暂时这么理解,下面我们会进行详细介绍。
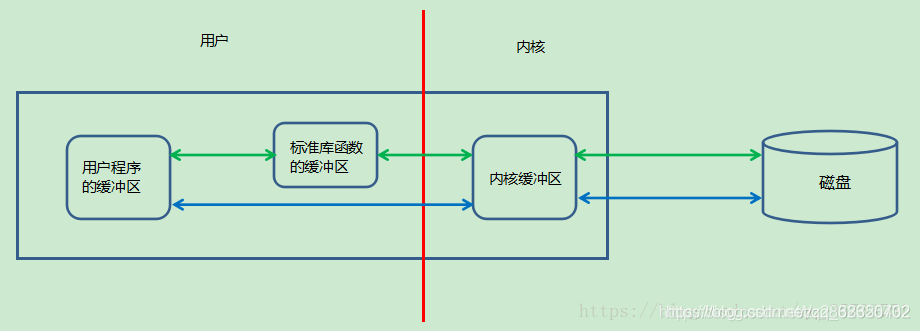
5. I/O缓冲区
对于fget,fput函数来说,每一个FILE文件流都有一个buf缓冲区,默认是8192字节,fget和fput函数有用户区缓冲区,也有内核缓冲区。
而read和write函数常称为Unbuffered I/O(注意:这里说的无缓冲指的是用户空间的缓冲区),但是write和read会使用内核缓冲区。
预读入:
磁盘的读写是物理操作,通过系统程序调用磁盘读写,硬件的物理操作会消耗硬件的使用寿命,为了减少对磁盘的物理操作。
当我们从磁盘中读取数据时,不管用户程序需要读取多少数据,系统调用都会从磁盘中把数据读满到内核空间的内核缓冲区,即便用户程序只需要读取1个字节,系统都会把内核缓冲区读满,下次用户需要再读1个字节时,就直接从内核缓冲区中读取。
read和write的缓输出:
使用read和write函数,程序调用write写数据时,系统并不会直接把数据写入磁盘中,而是先把数据写入内核模式中的内核缓冲区,系统规定write使用了内核缓冲区 ,默认是4096字节大小,直到把内核缓冲区写满,然后kernel再把数据一次性写入磁盘中。
这样做的目的是为了提高效率,因为我们在写数据的时候是在用户模式中调用用户程序把数据写入buf中,是从用户模式切换到内核模式(这一切换过程是非常耗时的,特别是频繁的切换极其耗时,所以用户模式切换到内核模式整个过程是最根本的原因),把数据写入内核模式中的内核缓冲区中。
同理,使用系统调用read读取磁盘是也是一次性把内核的缓冲区一次性读满(减少对磁盘的物理I/O操作,提高效率),然后再根据实际要读取的数据直接从内核的buf缓冲区中读取数据,而不是再从磁盘中读取数据了。
fget和fput缓输出:
使用fget和fput标库函数和read,write函数最大的不同就是标库函数自带了一个缓冲区,也就是说在fget和fput的内部实现中包含一个缓冲区,标库函数在读数据的时候不管是读取多少的字节,读完了都会放入用户模式中自带的缓冲区里,这个缓冲区的大小系统默认也是4096,标库函数的缓冲区写满时会调用系统的write,也就是说fget,fput内部实现会调用write进行工作区域的切换,(read/write是属于系统调用)从用户模式切换到内核模式,间接调用write把数据写入内核缓冲区中,然后把数据一次性写入磁盘中。
6. 通过strace命令跟踪程序的系统调用
strace命令可以用于跟踪查看程序执行期间所使用的系统调用查看程序执行期间所有的系统调用。
执行strace ./get_put.c命令,查看get_put程序执行时的系统调用情况,如图所示:
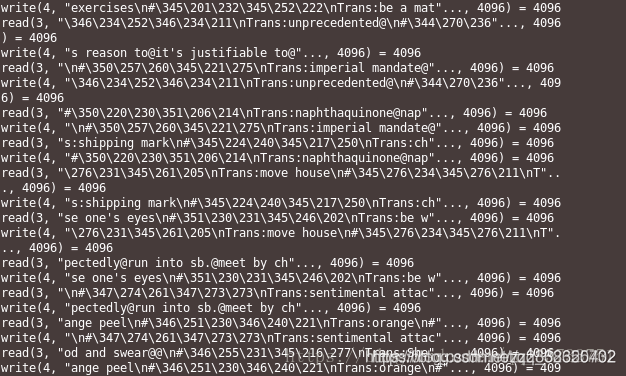
我们发现get_put程序很快就执行完了,速度很快,前面我们说过fgetc和fputc标准库函数读写文件时同样也调用了read和write系统函数,不同的是,标准库函数每次调用read和write读写了4096字节大小才从用户模式到内核模式的切换,减少了用户到内核的切换次数,整个读写过程相对来说花费的时间更少,提高了效率。
执行strace ./read_write.c命令,查看read_write程序执行时的系统调用情况: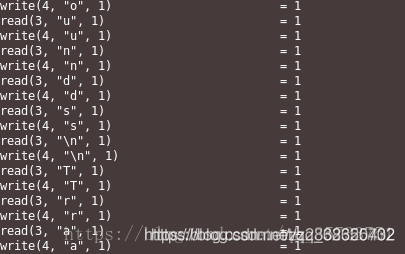
通过strace命令跟踪read_write.c执行期间所有的系统调用发现,read_write程序执行时花费的时间较长,基本上每read和write一次,只读写一个字节大小,这意味着每读写一个字节就从用户模式到内核模式的切换,这样切换太过于频繁,耗时,这对整个读写过程来说降低了效率。
7. 总结
从(read/write)和(fget/fput)的缓输出的特点可知,read/write系统调用每次读取一个字节的话,那就意味着要调用write/read进行空间区域切换一次(即用户到内核),把数据写入内核缓冲区,每一次切换只写入一个字节。
而fget/fput每次读取一个字节时,会把数据写入标库函数的缓冲区直到读满为止,然后才调用write进行工作区域的切换把数据写入内核缓冲区,每一次切换写入了4096个字节。
从时间上来说,fget/fput减少了用户到内核的切换的次数,从而提高了读写效率,另外read和write本身是无用户空间缓冲区的,在读写数据时只使用了内核缓冲区,读写比较耗时。