一、步态识别优点及应用
生活中我们是否经常会遇到这样的场景:往往前方走来一个人,离我们还有一定的距离,但是我们却能一眼就认出这个人是我们熟悉的某个人,这是为什么呢?因为每个人的走路姿势都是独一无二的,因为太熟悉,尽管距离我们还是很远,却能够根据他的步态一眼认出他。
一、步态识别的优点:
1、采集装置的成本比面像识别低。步态识别采集的摄像机用一般的即可,因而采集图像成本比面像识别的低。
2、采集的距离比面像识别远,步态识别来集的距离要比面像识别的距离远, 50米以内都可以识别,只要能看清走路的姿态就行,甚至可以背离摄像机,这是面像识別所不行的,面像识别需要在3米以内,而虹膜识别更是需要目标在60厘米以内。
3、步态不易伪装。画像可伪装,而步态却不易,因为当你看到摄像头想伪装时,你的步态却早已被釆集了。
4、使用最方便。 步态识别使用最方使, 面像识别那样需要较好的光照条件来分清面像。
二、步态识别的潜在应用场景
1、安防监测
可将装有步态识别功能的摄像机,安装于工厂、医院、居民楼甚至野外开放等环境之中,能像人脸识别一样发挥出防盗、防窃等功能,通过全面有效的安防布控,保证生命财产安全。比如,石油行业的野外设施此前主要依靠人类安防力量进行巡检、防护,虽然有摄像头等监控设备,但是受限于客观原因,识别有效性不足。而步态识别技术可加强、完善油田的防控网络,及时发现隐患,保护位于野外露天环境的石油设施。
2、刑侦监测
大多数情况下,罪犯视频往往不会露脸、或者清晰度不高,办案警察很难从中获取有效信息,而步态识别技术应用之后,上述现象将得到明显改观,降低办案难度,节约办案时间和成本。
3、公共领域
步态识别可用于公交车、旅游景区等公共领域。在这些领域,步态识别能实现对安防的布控,实现无卡出行,以及对人群密度的预测或进行超流量预警,从而有效防护公共安全。
4、家居领域
在家居领域,步态识别可以很好地应用于智能家居系统中,赋予家电系统的的智能化感知,提供更加个性化的服务。
步态识别技术还处于发展阶段,相信随着时间的推移和科研人员的不断努力,步态识别技术会日趋成熟,会应用到更多的领域。
二、步态识别发展:
以下内容来源:https://mp.weixin.qq.com/s/h1ox-QnSH8NmtRLbTddBDA

Nixon教授在1997年发表了第一篇现代步态识别论文,识别准确率达到了90%,但是步态库数据量较少,只有几人。但其作为开创性的工作,为后续的工作提供了重要的指导。
2015年之前,相关研究主要通过手工设计特征,得益于深度学习的发展,步态识别领域最近几年获得了明显的提升。随着其他方法的应用,深度学习技术不断刷新识别准确率。GaitSet方法是近几年的关键工作之一,提供了一种全新的思路,许多学者将GaitSet作为性能基准,试图超越。
步态识别的难点在于其有角度、衣着、挂件和背包等变化。而这种变化是日常生活场景非常自然,也很常见的。给步态识别带来了许多困难。所以在研究中,我们必须考虑角度等参数的影响。

在步态识别领域接近二十年的发展过程中,领域内主要采用两种主流的研究特征:
1)Appearance-base feature,主要采集人体的体态表面特征。常用的方法会在后续介绍。
2)Model-based feature,主要通过对人体建模,如人体骨架和3D建模等方法提取后的特征再送入分类器中,识别出对应的人。

2005年前,model-based方法是步态研究中的主流,图为王亮老师的相关研究工作。国内最早的步态识别库NLPR/CASIA-A由王亮老师创建。在早期,学者们认为要研究人体步态就需要对人体建模,研究模型的属性诸如手臂摆动幅度,各关节的夹角等。但在后续发展中,基于模型的方法不再受到很大的关注,主要原因在于基于模型的方法在建立人体模型时的计算量大,人体建模精度不高造成了最终识别率低。

因此,学者们将目光投入到更简洁高效的Appearance-based方法。Appearance-based方法提取人体轮廓信息,如最常用的GEI(Gait Energy Image)在提出时就因其简单高效且准确率超越其他所有方法带来了许多关注。其他类似的变种也是同样提取表面特征但是注重点不同,如注重动态信息的GEnI(Gaut Entropy Image),还有GFI(Gait Flow Image)CGI(Chrono Gait Image)等方法。
从不同Appearance-based 方法准确率对比中可以发现,GEI作为最简单的提取并平均人体表面体态,其准确率可以达到非常高的水平,这也是appearance-based方法成为主流研究方法的一大原因。

步态识别算法的发展脉络介绍。最早期的步态识别研究流程是:由图像中提取人体的轮廓,采用不同的人体步态表示方法如之前提及的GEI或者GEnI表示轮廓序列;再使用不同的学习方法提取特征信息,通过分类器识别出人的身份。
随着深度学习的出现与发展,卷积神经网络合并了特征提取与分类两个步骤。近五年的步态识别工作都是基于这个思路,深度学习也给步态识别准确率带来了明显的提升。
近几年,学者们发现表观序列用如用GEI表示,是会损失一些特征信息的。得益于卷积神经网络的拟合学习能力,有的工作开始尝试直接将轮廓序列输入神经网络中,略过轮廓平均这一步骤。GaitSet就是采用了这样的研究思路,将准确率再度提升。
在过去的十几年间,步态识别算法以采用表观特征研究方法为主。而人体模型特征的步态研究由于人体建模方法的精度低,计算量大,识别率低等原因受到关注较少。最近的人体建模技术迅速发展,正促进使用模型特征(Model-based feature)的步态识别研究。
得益于深度学习技术的迅速发展,人体姿态估计(pose estimation)得到巨大发展。在2016—2017年间,OpenPose横空出世。从图像中或者视频序列,OpenPose可以准确的估计人体骨架信息。人体建模技术得到明显的提升,姿态估计技术的发展克服了早期步态识别model-based方法的不足与缺陷,而我们认为这就是步态识别未来发展的方向之一。
三、步态识别相关论文及代码:
Paper:GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition *
将步态作为序列的交叉视角步态识别
Code:https://github.com/AbnerHqC/GaitSet
博客地址:https://blog.csdn.net/qq_14845119/article/details/101067829

GaitSet主要特点:
- 灵活,网络的输入图片除了大小需要固定为64*44这个约束外,不要求输入的时序图片必须具备时序顺序,同时对于个数也不要求,可以输入任意的个数,任意的姿态的,任意拍摄视角的轮廓图。
- 快速,网络直接学习步态的特征,而不是测量一系列的步态轮廓图序列和模板的相似性。通过对学习到的特征和数据库中的特征进行欧式距离的计算来进行识别。
- 刷新了CASIAB和OU-MVLP数据集。
首先网络的输入为5个维度,num_of_people*frame_num*channel*height*width。其中,batch_size= num_of_people*frame_num。训练的时候可以输入多个人的多张图,测试的时候,输入一个人的多张图,也就是说测试的时候,num_of_people=1。
Triplet loss 的margin为0.2,包含了hard loss和full loss。
HPM的尺度scale为5,也就是(1+2+4+8+16)。
每一个batch的输入,类别数p=8,每个类别的帧数k=16,
通道数c1=c2=32,c3=c4=64,c5=c6=128。
输入图像大小为64*44*1,为灰度图,经过2次下采样操作,变为16*11。
先说网络的整体思想,感觉和人脸识别中度量学习很类似,基本思想都是分类,使用triplet loss。当然也是和而不同,区别就在于,
GaitSet中加入了非严格时序维度的图片特征,并且将这个时序维度的特征做attention操作,压缩到batch维度,也就是SP操作。
GaitSet中的一个人的一系列的图最终将高度和宽度维度压缩为1,2,4,8,16共31个维度的特征。也就是HPM模块。
另外一个上图中连续输入的图片是表现在batch维度的操作,虽然图中画了3行红色和蓝色相间的这样的操作,但是,实际上,只有一个分支,通过batch维度实现,也就是论文中说的这部分权值共享的意思。
其中,黄色部分分别表示,卷积+卷积+pooling操作,卷积+卷积操作
粉丝部分每行分别表示,卷积+卷积+pooling操作,卷积+卷积+pooling操作,卷积+卷积操作
+,表示对应维度的加法操作。
MGP模块表示Multilayer Global Pipeline (MGP),主要融合不同层的输出特征,增加模型的不同感受野的信息。
SP表示Set Pooling操作,
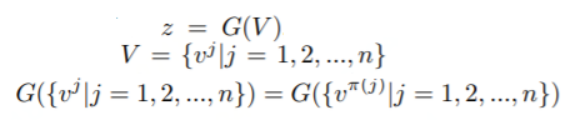
Z表示集合维度的特征,一个人表示一个集合,
V表示帧维度的特征
Π表示任意的组合

SP操作就表示为在set维度,也就是第二维frame_num这个维度进行全局的max,mean,median操作,然后再进行1*1卷积操作。
后续又对SP模块引入attention机制,

最终在SP操作后,再进行加法和max操作,得到最终的输出。
HPP操作表示Horizontal Pyramid Pooling (HPP),主要将height和width维度压缩为1,2,4,8,16这样的一个维度的尺度信息(scale),该操作可以帮助网络处理各个尺度的特征,可以融合局部和全局特征。HPP操作通过Global Max Pooling和Global Average Pooling实现。
![]()
HPM模块表示最终输出的特征向量,MGP模块和主网络模块分别经过HPP操作,宽度和高度这两个维度被压缩成1,2,4,8,16这样的1个维度,像下图的第一列的蓝色的h*w*c变成了第二列的蓝色的1*c,红色的h*w*c变成第二列的2*c。两个这样的31维度concat成62维度。channel维度不变,为D=128,然后再经过一个全连接操作,变成D=256维度。

Batch维度原本为num_of_people*frame_num,frame_num维度经过SP操作变为1,被squeeze掉后,batch维度就是num_of_people,也就是说训练的batch中有几个人,就输出几个对应的62*256的特征向量。测试的时候,因为只有1个人输入,所以输出1个62*256的特征向量。这个特征向量可以理解为,1个人对应62个全连接层的特征向量,每一个特征向量的维度为256维。
对于训练部分,则计算每个特征向量组成的矩阵和自己的转置的自相关矩阵,也就会得到anchor和p,anchor和n,相当于对batch内的所有样本都进行了组合。
Triplet Loss=max(d(a,p)−d(a,n)+margin,0)
总结:
GaitSet更像一个基于黑白轮廓图的度量识别的网络。当然网络也考虑了时序的特征,但是总感觉这样的操作,更像是一个时序维度的attention机制,也就是单纯的把多个时序维度压缩为1个维度,而不像3d-cnn和lstm那样专注的学习时序的相关性更好。当然优点就是该方法具有时序无关性,同时接受任意时序个数的输入,得到一个特征向量。
Paper:GaitPart: Temporal Part-based Model for Gait Recognition
Code:https://github.com/ChaoFan96/GaitPart
在最新的文献中,采用部分特征进行人体描述已被证实有利于个体识别。 综上所述,我们假设人体的每个部分都需要自己的时空表达。然后,我们提出了一种新的基于部分的模型GaitPart,并得到了提高性能的两个方面的效果:一方面,提出了一种新的卷积应用Focal Convolution Layer,以增强部分级空间特征的细粒度学习。 另一方面,提出了微运动捕获模块(MCM),在步态部分中有几个平行的MCM分别对应于人体的预定义部分。





Paper:GAITGRAPH: GRAPH CONVOLUTIONAL NETWORK FOR SKELETON-BASED GAIT RECOGNITION
Code:https://github.com/tteepe/GaitGraph
提出了将骨架姿态与图形卷积网络(GCN)结合起来的步态图,以获得一种现代的基于模型的步态识别方法。

目前的姿态估计算法对遮挡、杂乱和变化的背景、携带的物品和衣服具有很强的鲁棒性。
本文提出了步态图,这是一种新的方法,我们将GCN应用于人体骨架姿态图。姿态估计取代了以前方法中的轮廓提取。
贡献:
基于骨骼的表示在使用不太敏感的个人数据的同时,带回了真实的步态识别。 我们的贡献可以总结如下:(1)我们使用基于模型的步态识别的现代解释,利用稳健的人体姿态估计和强大的时间和空间建模的GCN。 (2)与目前基于模型的方法相比,我们的经验实验显示了最先进的(SOTA)结果。

网络由ResGCN块组成。 该块由图卷积和经典的时域二维卷积和具有可选瓶颈结构的残差连接组成。

如有侵权,联系删除!!