1,格式化输出。
现有一练习需求,问用户的姓名、年龄、工作、爱好 ,然后打印成以下格式

------------ info of Alex Li ----------- Name : Alex Li Age : 22 job : Teacher Hobbie: girl ------------- end -----------------
你怎么实现呢?你会发现,用字符拼接的方式还难实现这种格式的输出,所以一起来学一下新姿势
只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量做个映射关系就好啦
name = input("Name:")
age = input("Age:")
job = input("Job:")
hobbie = input("Hobbie:")
info = '''
------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name
Name : %s #代表 name
Age : %s #代表 age
job : %s #代表 job
Hobbie: %s #代表 hobbie
------------- end -----------------
''' %(name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来
print(info)
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
age : %d
我们运行一下,但是发现出错了。。。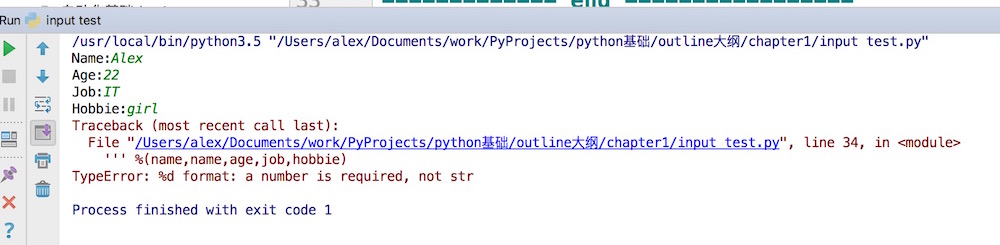
说%d需要一个数字,而不是str, what? 我们明明输入的是数字呀,22,22呀。
不用担心 ,不要相信你的眼睛我们调试一下,看看输入的到底是不是数字呢?怎么看呢?查看数据类型的方法是什么来着?type()
name = input("Name:")
age = input("Age:")
print(type(age))
执行输出是
Name:Alex
Age:22
<class 'str'> #怎么会是str
Job:IT
让我大声告诉你,input接收的所有输入默认都是字符串格式!
要想程序不出错,那怎么办呢?简单,你可以把str转成int
age = int( input("Age:") )
print(type(age))
肯定没问题了。相反,能不能把字符串转成数字呢?必然可以,str( yourStr )
问题:现在有这么行代码
msg = "我是%s,年龄%d,目前学习进度为80%"%('金鑫',18)
print(msg)
这样会报错的,因为在格式化输出里,你出现%默认为就是占位符的%,但是我想在上面一条语句中最后的80%就是表示80%而不是占位符,怎么办?
msg = "我是%s,年龄%d,目前学习进度为80%%"%('金鑫',18)
print(msg)
这样就可以了,第一个%是对第二个%的转译,告诉Python解释器这只是一个单纯的%,而不是占位符。
name = input('输入姓名:')
msg = "我是%s,年龄%s,目前学习进度为80%%" % ('name',18)
print(msg)
输出:我是name(纯name单词),年龄18,目前学习进度为80%
name = input('输入姓名:') 'name' 和 name 差别很大
msg = "我是%s,年龄%s,目前学习进度为80%%" % (name,18)
print(msg)
输出:我是name(输入的名字),年龄18,目前学习进度为80%
2,基本运算符。
运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
算数运算
以下假设变量:a=10,b=20

比较运算
以下假设变量:a=10,b=20

赋值运算
以下假设变量:a=10,b=20

逻辑运算

针对逻辑运算的进一步研究:
1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
例题:
判断下列逻辑语句的True,False。
1,3>4 or 4<3 and 1==1 2,1 < 2 and 3 < 4 or 1>2 3,2 > 1 and 3 < 4 or 4 > 5 and 2 < 1 4,1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8 5,1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
6,not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
2 ,(x,y)
x or y , x为0,值就是y,x为非0,值是x;
x and y, 相反

例题:求出下列逻辑语句的值。
8 or 4 0 and 3 0 or 4 and 3 or 7 or 9 and 6
in,not in :
判断子元素是否在原字符串(字典,列表,集合)中:
例如:
#print('喜欢' in 'dkfljadklf喜欢hfjdkas')
#print('a' in 'bcvd')
#print('y' not in 'ofkjdslaf')
content = input("请输入你的姓名:")
if "马化腾" in content or '麻花藤'in content:
print("敏感字符,重新输入")
else:
print("注册成功")
3,内容编码。
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
|
1
2
3
|
#!/usr/bin/env python
print
"你好,世界"
|
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
|
1
2
3
4
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
print
"你好,世界"
|
ASCII 不能装中文. 8个bit组成.最多有256种可能. 没有中文 1byte
GBK 有中文. 16个bit => 2byte
把ANSI 空余的位置交给各个国家. 交给中国之后. 中国继续编码.-GBK
交给台湾台湾继续编码. BIG5
依然不能国际化
UNICODE 万国码. 目的是把所有国家的文字都进行编码. 占32位. 缺点: 浪费
ASCII码的内容是不能改变的. 编码还应该是原来的编码. 但是unicode占用32个位置.
ASCII会强制在前面补24个0. 在网络传输和数据存储上会浪费空间
32个bit => 4个byte
UTF-8: 可变长度的unicode编码, 8的意思是一个字符最少8位
英文: 8bit, 1byte
欧洲: 16bit, 2byte
中文: 24bit, 3byte
ASCII: 8bit 1byte
GBK: 16bit 2byte
unicode:32bit 4byte
UTF-8: 最少8bit, 1byte, 中文: 24bit 3byte
计算机存储系统单位换算
8bit => 1byte
1024byte => 1KB
1024kb = 1MB
1024MB = 1GB
1024GB = 1TB