概述
这一张标题其实是序列构成的数组,其实也无所谓了, 站在小白的角度来讲,就是讲了讲列表, 元组, 数组的一些用法,这里站在我的角度上说说我的看法好了.
目录
- 列表推导,原则和一些问题, 和一些扩展
1.1 列表推导
1.2 一些问题
1.3 一些扩展
1.4 双层列表推导 - 生成器表达式与generator, 数组, 双重生成器表达式
2.1 生成器表达式与generator
2.2 数组
2.3 双重生成器表达式 - 元组
3.1 元组的应用, 元组拆包和字典拆包, 嵌套元组拆包
3.2 以及具名元组 namedtuple的应用
3.3 最后还有一些类的知识 - 切片的各种用法
4.1 高级切片
4.2 切片变量
4.3 给切片赋值
### 1. 列表推导,原则和一些问题, 和一些扩展
1.1 列表推导
列表推导是什么? 看下面这个例子
symbols = '$%&*(@'
codes = []
for item in symbols:
codes.append(ord(item))
print codes
执行结果

看到上面的例子,可以看到, 我们的目的就是为了让symbols里面的内容, 转化为ascii码,我们写了几行? 有用的是3行, 我说这不美观,你同意吗? 你肯定同意, 那么我们能够实用什么方法来简化这种写法吗? 当然有了,那就是列表推导
symbols = '$%&*(@'
codes2 = [ord(item) for item in symbols]
print codes2
执行结果
可以看到,执行结果一摸一样, 这就是列表推导,写法也肯简单, 写法如下, 写的多了, 也就熟悉了,基本上就是下面的格式了, func_one其实也可以是x本身, 或者任何可以返回结果的一些方法. func_two就是关于x的一些判断
result_iter = [ func_one(x) for x in some_iter if func_two(x) ]
1.2 一些问题
变量泄露的问题
看下面一个例子
x = 'my precious'
dummy = [x for x in 'ABC']
print x
# 其实和下面的是一样的
# x = 'my precious'
# dummy = []
# for x in 'ABC':
# dummy.append(x)
# print x
执行结果
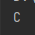
本来结果应该是my precious, 这个问题只会出现在python2中, python3已经把这个问题解决了
1.3 一些扩展
扩展什么呢? 就是写的多了, 就会发现, 列表推导其实和filter() + map()组合很像
filter: filter(func, iter) 满足条件返回
map: map(func, iter) 根据条件转换(映射)
如下面的例子,还是将symbols = '$%&*(@'转化为ascii码
symbols = '$%&*(@'
beyond_ascii = [ord(x) for x in symbols if ord(x) > 20]
print beyond_ascii
beyond_ascii = filter(lambda x: x > 20, map(ord, symbols))
print beyond_ascii
执行结果
效率上其实是差不多的, 别问我为什么, 我也不知道为什么, 书上说的效率差不多, 我还没有到能够独自分析效率的水平, 但是另一句我们可以理解,列表推导更加容易理解, 这个不用多说了吧, 那是肯定的啊
1.4 双层列表推导
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
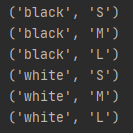
tshirts = [(color, size) for color in colors for size in sizes]
print tshirts
tshirts = [(color, size) for size in sizes for color in colors]
print tshirts
执行结果

没什么好解释的,看看就完了
2 生成器表达式与generator, 数组, 双重生成器表达式
2.1 生成器表达式与generator
还是把symbols = '$%&*(@'转化为ascii码,但是这次我们不是用列表推导了, 而是使用生成器表达式
symbols = '$%&*(@'
beyond_ascii = tuple(ord(symbol) for symbol in symbols)
print beyond_ascii
执行结果

这个其实就是generator的简便写法,具体可以看我之前专门写generator的文章
python简单进阶,Generator
语法上和列表推导差不多, 可以说除了[]换为了(),其实没有任何区别
那么其实有一个问题,为什么这个能够直接打印呢? 其实使用tuple()把generator循环了一遍,转化为了tuple, 我们如果不转化, 直接打印, 打印的肯定是一个genertor的地址

# coding=utf-8
symbols = '$%&*(@'
beyond_ascii = (ord(symbol) for symbol in symbols)
print beyond_ascii
try:
while True:
print beyond_ascii.next()
except StopIteration:
print '接收到了 StopIteration , 遍历终止'
执行结果

可以看到, 我们打印beyond_ascii,第一行是<generator object <genexpr> at 0x00000000037C9548>, 这证明了生成器表达式就是一个generator, 然后我们用for loop的内在原理去遍历这个generator,这可是流畅的python一书中没有讲到的,看到这nm不点个赞,不收个藏?
2.2 数组
简单的看一下例子吧, 还是将symbols = '$%&*(@'变为ascii码的数组
import array
beyond_ascii = array.array('i', (ord(symbol) for symbol in symbols))
print beyond_ascii
执行结果

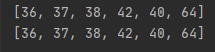
前面的i其实就是代表着这是一个整数数组, 在纯数字的情况下,数组的效率是要比列表快的,不要问为什么快, 书上说的, 我也不清楚具体原因,如果要我猜的话, 可能是存储的结构吧,下面是前面不同字符所代表的不同数组类型

2.3 双重生成器表达式
简单看一下例子就完了
# 每次循环拿一个 yield嘛
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
test_double_generator = ((c, s) for c in colors for s in sizes)
for tshirt in test_double_generator:
print tshirt
执行结果
3 元组
元组是对数据的记录,也就是说,因为不可变,其中信息的位置信息也很重要,嘚啵嘚、嘚啵嘚,说了一大堆废话
举个例子
traveler_ids = [('USA', '123456'), ("CHINA", '654321'), ("JAPAN", '123')]
for country, id in traveler_ids:
print country
执行结果
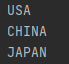
什么意思? TMD就是说, 元组中第一个数据是国家, 第二个数据是什么traveler_id,然后规定好,我们按照这种格式去写, 那么元组就保留了信息, 有点像内存数据库的感觉,你说我能说什么? 这不是跟放屁一样吗?
3.1 元组的应用, 元组拆包和字典拆包, 嵌套元组拆包
元组拆包, 就是TMD把元组里面不同的值分别做不同的处理(赋给不同的值)
也可以认为是“可迭代对象拆包”
方式一、平行赋值, _在国际化的软件中并不是一个很好的占位符,但其它情况下是很好的占位符
a, b = (1, 2)
print a, b
# 执行结果就不打印了
方式二、不使用中间变量交换两个变量的值
a, b = (1, 2)
b, a = a, b
print a, b
# 执行结果就不打印了
方式三、使用* 将元组拆分, 使用**将字典拆分(字典的key必须是str,且和函数定义时的param名字一样,数量一样)
a, b = (1, 2)
def test_func_1(a, b):
return a / b, a % b
def test_fun_2(a=None, b=None):
return a / b, a % b
def test_fun_3(x, y, a=None, b=None):
return x / y, x % y, a / b, a % b
params_tuple = (20, 8)
params_dict = {
'a': 20, 'b': 8}
print test_func_1(*params_tuple)
print test_fun_2(**params_dict)
print test_fun_3(*params_tuple, **params_dict)
执行结果

方式四, 使用*来获取其他不想要的信息
a, b, *reset = range(5) # 但是在python2中不能使用, python3中可以
嵌套元组拆包
# coding=utf-8
metro_areas = [
('王晓峰', '男', 23, ('河南省', '项城市', '惠民小区')),
('张冠举', '男', 24, ('河南省', '项城市', '袁张营')),
('龙斌', '男', 24, ('河南省', '项城市', '荣楼'))
]
for name, sex, age, (province, area, city) in metro_areas:
print name, province
执行结果

3.2 以及具名元组 namedtuple的应用
废话少说, 先举个例子
from collections import namedtuple
City = namedtuple('City', 'name, country, population, coordinates')
tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
print tokyo
print tokyo.name
print tokyo.country
print tokyo.population
print tokyo.coordinates
print tokyo[0]
print tokyo[1]
print tokyo[2]
print tokyo[3]
执行结果

_fields属性,这个我感觉就是把类的__dict__包装了一下,接着上面的代码,如下
for item in tokyo.__dict__:
print item,
print tokyo.__getattribute__(item)
print '======================'
for item in tokyo._fields:
print item,
print tokyo.__getattribute__(item)
执行结果
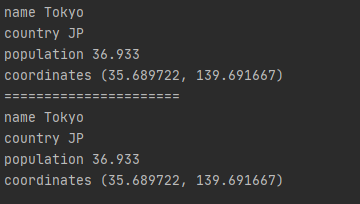
_make(iter)通过接收一个可迭代对象来生成一个类的实例,和 Class(*iter)作用类似,以OrderedDict的形式返回
LatLong = namedtuple('LatLong', 'Lat, long')
ShangHai_data = ('ShangHai', 'CHINA', 32.000, LatLong(123, 321))
ShangHai = City._make(ShangHai_data)
print ShangHai._asdict()
print ShangHai.country
执行结果

不过就是直接用元组来进行namedtuple的生成罢了,没什么卵用
3.3 最后还有一些类的知识
这个就是随便写着玩玩, 看看得了
class TestClassOne(object):
def __init__(self, name=None, age=None, sex=None):
super(TestClassOne, self).__init__()
self.name = name
self.age = age
self.sex = sex
data = ('王晓峰', 23, '男')
test = TestClassOne(*data)
print test.__dict__
for filed in test.__dict__.keys():
print test.__getattribute__(filed)
执行结果

4. 切片的各种用法
切片切的是index [x:y] x<=index<y
举例
a = [1, 2, 3, 4, 5, 6, 7]
print a[0:len(a)]
print a[2:len(a)]
print a[:2]
执行结果
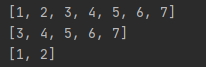
高级切片
高级切片 iteration[a:b:c] 在a, b之间以c为间隔切片, c负值意味着反向
s = 'bicycle'
print s[::3]
print s[::-1]
print s[::-2]
执行结果
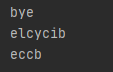
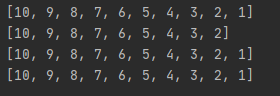
当最后一个为负数的时候,我也没有弄懂, 但是有几个比较有意思的代码, 看一下吧, 如果有人弄明白了, 请直接给博主发消息, 一起讨论
test = range(1, 11)
print test[10::-1]
print test[10:0:-1]
print test[-1::-1]
print test[-1:-11:-1]
执行结果
切片变量
直接看例子吧,没啥好说的
test = range(1, 11)
slice_1 = slice(1, 12, 2)
print test[slice_1]
执行结果

给切片赋值
看例子吧,没什么好说的
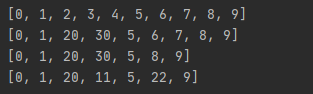
l = range(10)
print l
l[2:5] = [20, 30]
print l
del l[5: 7]
print l
l[3:: 2] = [11, 22]
print l
执行结果