双链表
单链表结点中只有一个指向其后继的指针,这使得单链表只能从头结点依次顺序的向后遍历,访问后继结点时间复杂度为O(1),访问前驱结点的时间复杂度为O(n).

双链表仅仅是在单链表的结点中增加一个指向其前驱的prior指针,因此,在双链表中执行按值查找和按位查找的操作和单链表相同。但双链表在插入和删除操作的实现上,和单链表有着较大的不同。这是因为“链”变化时也需要对prior指针做出修改,其关键在于保证在修改的过程中不断链。此外,双链表可以很方便地找到其前驱结点,因此,插入,删除结点算法的时间复杂度为O(1).
双链表的结点定义:
class linknode():#每个结点有两个数据成员,结点元素和指向下一个结点的指针
def __init__(self,item):
self.item=item
self.next=None
self.prior=None
插入节点:
 在双链表中p指向的结点之后插入s指向的节点,执行代码为:
在双链表中p指向的结点之后插入s指向的节点,执行代码为:
s->next=p->next
s->prior=p
p->next->prior=s
p-next=s
删除节点
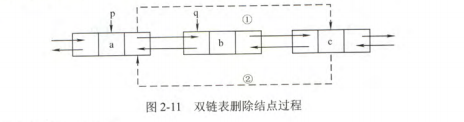
删除双链表中q指向的结点,执行代码:
p->next=q->next
q->next->prior=p
循环链表
循环单链表
循环单链表和单链表的区别在于,表中最后一个结点的指针不是NULL,而改为指向头结点,从而整个链表形成一个环。

表尾指针的next指向头结点,因此表中没有指针域为NULL的结点,因此循环单链表的判空条件为:
头结点->next==L?True:False
循环双链表
和循环单链表的不同在于:头结点的prior指针还要指向尾结点,其余的结点也都有两个指针域,prior指向它的前驱结点。
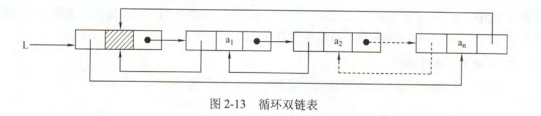
当循环双链表为空表时,其头结点的prior和next都等于L