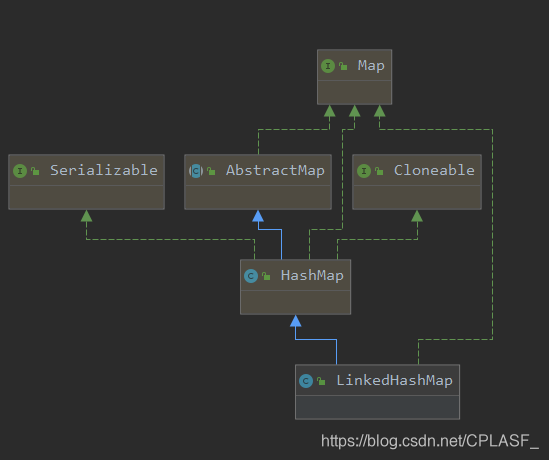
我们常说linkedHashMap是有序的,这个有序也是分为两种的,分别是:插入顺序和访问顺序,我们可以通俗的认为:linkedHashMap = hashmap + 双向链表
以下的学习是基于jdk8
根据linkedHashMap的结构来看,是依赖于hashmap的,通过查看源码,我们也会发现,linkedHashMap只是维护了一个链表,并没有put、remove方法的具体实现,因为linkedHashMap的设计思想是:对数据的操作,是依赖于hashmap中的方法,只是在其中的一些细节方法,linkedHashMap会进行扩展,接下来我们先说属性有哪些
属性信息
/**
* The head (eldest) of the doubly linked list.
* 链表的head节点
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
* 链表的尾结点
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
* false:表示插入顺序;true表示读取顺序
* @serial
*/
final boolean accessOrder;
AccessOrder
该属性是来区分当前linkedHashMap是按照访问顺序排序,还是按照put顺序有序,当该参数为true的时候,表示按照读取顺序有序;默认为false,按照put顺序有序
newNode()
在调用put方法的时候,会调用父类hashmap的put方法,那linkedHashMap如何维护节点之间的顺序呢?
在put方法中,如果得到当前key要存储的位置,会调用newNode()方法,初始化一个node节点,
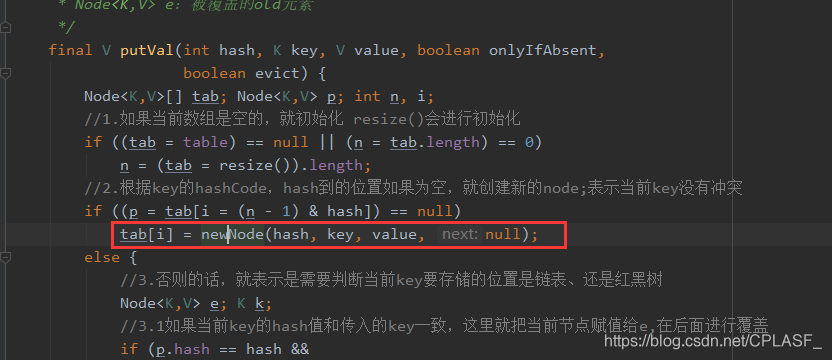
linkedHashMap对该方法,进行了覆写,
/**
* 在向map中put元素的时候,是会初始化一个node节点,如果是linkedHashMap,调用的是该方法
* 在该方法中,可以看到,会初始化一个LinkedHashMap.Entry节点,然后将该节点插入到linkedHashMap的双向链表中
* 默认是加到链表尾部
* @param hash
* @param key
* @param value
* @param e
* @return
*/
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
这里可以看到,除了初始化一个节点之外,还会调用linkNodeLast方法,在linkedNodeLast方法中,会将p节点添加到自己维护的双向链表的尾部
/**
* 这是加入到链表尾部的方法
* 如果当前是第一个put的元素,那p就是head,否则,就把节点放到tail的后面
* @param p
*/
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
按访问顺序有序
假如在初始化linkedHashMap对象的时候,指定accessOrder为true,那表示按照访问顺序有序,在get方法中,会对访问到的元素进行处理
public V get(Object key) {
Node<K,V> e;
// 这里的getNode调用的是hashmap中的方法,获取到当前key所对应的value
if ((e = getNode(hash(key), key)) == null)
return null;
/**
* 如果是按照访问顺序有序,会把获取到的e节点插入到链表的尾部,然后返回e.value
*/
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
这里可以看到,如果是按照访问顺序有序的话,会额外调用afterNodeAccess()方法,如果为false,会直接返回获取到的节点value值,afterNodeAccess方法简单而言,就是将e节点移到链表的尾部,所以,我们可以认为,最近访问的在元素在链表的最后面
所以:对于按照put顺序有序的设置,在put元素的时候,本身就会把最新插入的元素放入到链表的尾部,如果是按照访问顺序有序的话,在get的时候,会把访问的元素移到链表的尾部,根据该特点,也可以实现一个简单的LRU算法
对于hashmap和linkedHashMap来说,最大的区别就是:hashmap是无序的,linkedHashMap自己维护了节点的顺序