目录:
java虚拟机汇总
- class文件结构分析
1).class文件常量池中的常量项结构
2). 常用的属性表的集合 - 类加载过程
1).类加载器的原理以及实现 - 虚拟机结构分析
1).jdk1.7和1.8版本的方法区构造变化
2).常量池简单区分 - 对象结构分析<<== 现在位置
1).压缩指针详解 - gc垃圾回收
- 对象的定位方式
题外链接:(压缩指针详解)
目标:能够算出一个对象的具体长度
对象是在堆中创建的
对象的内部结构图为

这就是一个对象的基本结构,下面每一个结构详细说明
1.对象头中的MarkWord
图为马士兵的64位虚拟机MarkWord头信息,每一行都是一种markWord的状态(不是全部代表markword)

然后是32位操作系统的
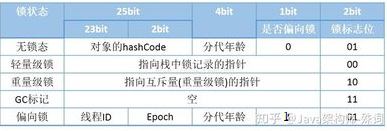
markWord在32操作系统中是32位,在64操作系统中,不管开不开启指针压缩(指针压缩详解)都是64位,8个字节
下面逐个说明下每个字段的意义(64位的,32位同理),目前在jvm阶段的了解即可
-
锁状态
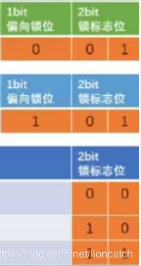
这里分为两个部分,偏向锁位和锁标志位,他们两个共同决定锁的状态(锁升级将在并发编程中说)
偏向锁位:对象是否启用偏向锁标记,只占1个二进制位。为1时表示对象启用偏向锁,为0时表示对象没有偏向锁。
锁标志位:这两位的标志决定了markword整体的格式,可以从图中很明了的看出,每一种锁标志位对应的整个markWord的存储格式都有所不同 -
锁状态为0 01
此时- 前25位没有使用,
- hashCode占了31位,存放该对象的哈希码
- 1位没有使用
- 4位分代年龄,表示了对象在堆中的分代信息,即最高15(这也是目前ps+po的分代年龄)
-
锁状态为1 01
此时此对象为偏向锁状态,原来的hashCode无法存储,转存到管程Monitor中- 前面54位为指向你那个线程的id
- 接下来2位为Epoch:偏向锁的时间戳,如果一个线程来对此对象加锁,发现时间戳和自己的不一样(这个是cas操作中的解决aba问题的版本号,每次偏向时加1),说明有其他线程执行了,此线程将会重新尝试偏向,即重偏向,重新执行cas操作修改前面54位的线程id,如果失败了说明此时有线程在使用,就立即进行锁膨胀(第一次发现有竞争时,就立即膨胀为轻量级锁,再在轻量级锁进行8次cas操作,如果都失败了,就再膨胀为重量级锁)
- 接下来1位没有用到
- 在接下来的4位仍然为分代年龄
-
锁状态为 00
此时状态为轻量级锁(自旋锁),说明此时已经有至少一次竞争了
1. 62位都为线程栈中栈的指针(注:和1 01的54位线程id不一样,一个是id,一个是指针) -
锁状态为 10
重量级锁,直接把自旋的线程全部由cpu扔到内存阻塞队列里去,这里由cpu到内存的过程涉及到了系统的中断,消耗资源较高,所以这也是jdk1.6以前synchronized只用重量级锁效率低的问题,现在引入了偏向自旋锁来减少这种中断的发生
1. 62位都指向互斥量(重量级锁监视器)指针 -
gc标记信息
此需要知道CMS并发标记清除垃圾收集器,- 62位为CMS过程中的标志信息
2.对象头中的kClass
这一部分存储对象的类型指针,该指针指向方法区的类元数据,JVM通过这个指针确定对象是哪个类的实例,长度:32位的JVM为32位,64位的JVM为64位。64位操作系统开启压缩指针后为32位(前面已经提到,一定要看压缩指针详解))
3.实例数据
这里才是最大的数据存储区,没有什么可说的int a =3,就存个int类型的a值为3,如果值是常量或静态的则直接指向方法区中的对应数据,关于这部分的长度,在(压缩指针详解)解析
4.对齐填充
整个对象都要以8字节为基准,比如前面为12字节,那对齐填充就是4字节,加起来是16,可以被8整除,至于为什么,因为操作系统总线带宽是以8字节为基础传输,所以提高传输效率之类的巴拉巴拉。。。