阅读导航
前言
今天学了图的构造,老师讲解之后要求我们自己实现构造一个图,这里我建了一个无向图,图的后续操作将在近几天更新~~~
构建的图为抽象城市间的距离得到,并使用邻接矩阵表示该无向图。
记录成长历程,让我们一起进步吧~
注:在这里我将使用两个图作为运行示例,一个图用字母表示,另一个则更为实际,以真实城市举例
图的构建
以下图为例,我们一起来构造了解它吧~↓
无向字母图
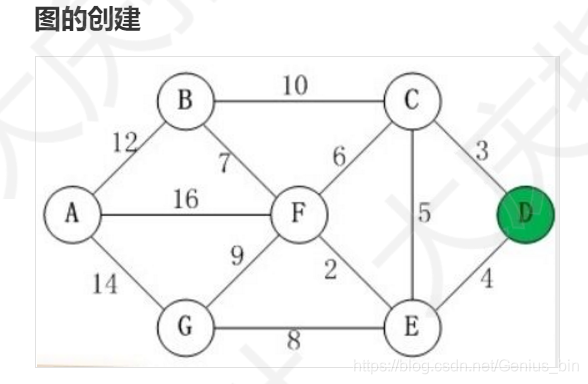
根据图的结构,我们可以写出邻接矩阵为:

实际城市图
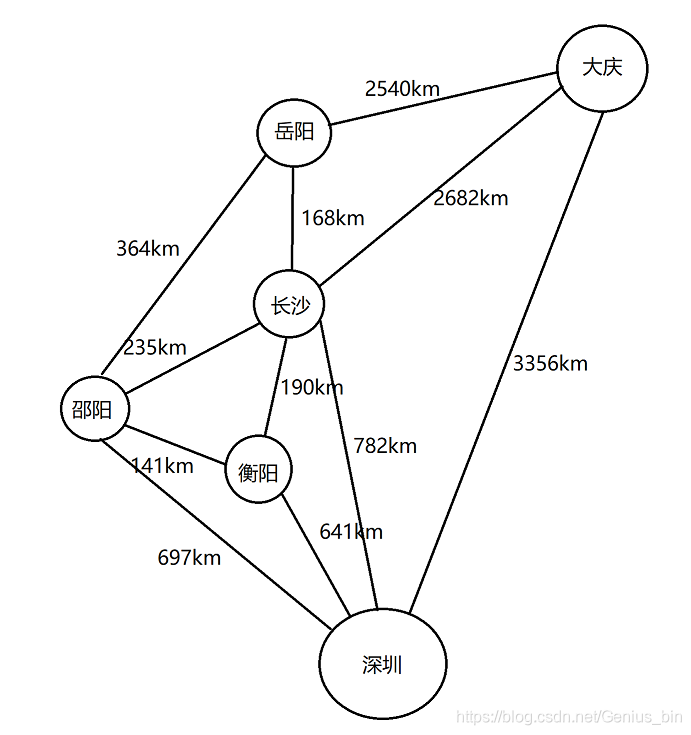
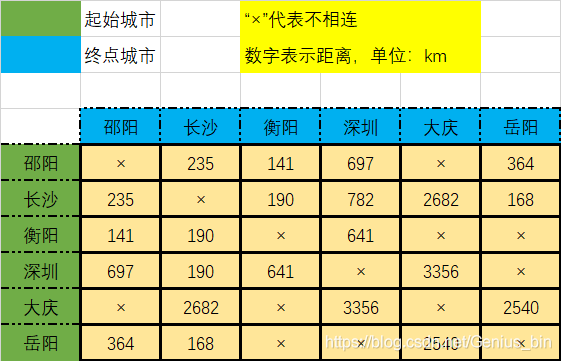
同样,用邻接矩阵表示:
图构建代码
void CreGraph::Create_Graph(vector<string>& city_Name, vector<vector<string>>& city_Vertex_Information) {
int len = city_Name.size();
for (int i = 0; i < city_Name.size(); ++i) {
this->city_Index[city_Name[i]] = i;//每个城市给予一个编号
}
this->city_Information.assign(len, vector<int>(len, 0));//初始化
//到哈希表中查找每个城市对应编号,将其记录到startINdex、endIndex
//起始城市:city_Information[i][0];
//目的城市:city_Information[i][1];
//城市间的距离:city_Information[i][2];
for (int i = 0; i < city_Vertex_Information.size(); i++) {
for (int j = 0; j < city_Vertex_Information[i].size(); j++) {
int start_Index = city_Index[city_Vertex_Information[i][0]];
int end_Index = city_Index[city_Vertex_Information[i][1]];
//start、end作为下标,距离就是数组元素的值
stringstream str;
str << city_Vertex_Information[i][2];
int distance;//将字符串转换为整型数据
str >> distance;
this->city_Information[start_Index][end_Index] = distance;
}
}
}
BFS广度优先搜索
void CreGraph::BFS(string start_city) {
int cur_Index = city_Index[start_city];//找到起始元素下标
queue<int> que;
que.push(cur_Index);
unordered_set<int> visited_City;//生成哈希集合收集访问过元素(防止重复入栈)
visited_City.insert(cur_Index);
while (!que.empty()) {
int cur_City_Index = que.front();
que.pop();
cout << city_Name[cur_City_Index] << " ";//输出当前城市
for (int column = 0; column < city_Information[cur_City_Index].size(); column++) {
int cur_Visited_City = city_Information[cur_City_Index][column];//当前城市正访问的城市
if (cur_Visited_City > 0 && visited_City.find(column) == visited_City.end()) {
que.push(column);//若该城市与之连通且曾未访问过,压入队列
visited_City.insert(column);//将当前访问到的节点放入visited 集合
}
}
}
}
DFS深度优先搜索
栈实现
void CreGraph::DFS(string start_city) {
stack<int> stk;
stk.push(city_Index[start_city]);//哈希中查找城市对应下标
unordered_set<int> visited_City;
visited_City.insert(city_Index[start_city]);//初始时将起始城市加入到哈希集合(访问过的城市)中
while (!stk.empty()) {
int cur_visit_City = stk.top();
stk.pop();
cout << city_Name[cur_visit_City] << " ";
for (int column = 0; column < city_Information[cur_visit_City].size(); column++) {
if (city_Information[cur_visit_City][column] > 0 && visited_City.find(column) == visited_City.end()) {
stk.push(column);
visited_City.insert(column);
}
}
}
}
递归实现
void CreGraph::Recur_DFS(string start_city, unordered_set<int>& visited_City) {
int cur_visit_City = city_Index[start_city];
visited_City.insert(city_Index[start_city]);//初始时将起始城市加入到哈希集合(访问过的城市)中
cout << city_Name[cur_visit_City] << " ";
for (int column = 0; column < city_Information[cur_visit_City].size(); column++) {
if (city_Information[cur_visit_City][column] > 0 && visited_City.find(column) == visited_City.end()) {
visited_City.insert(column);
Recur_DFS(city_Name[column], visited_City);
}
}
}
普里姆最小生成树
代码最终实现的是将最小代价生成树的边存储到 prim_Edges 容器中
普里姆算法用的是实际城市图进行举例
//优先级队列生成最小堆的构造规则↓
struct queue_cmp {
//构建最小堆
bool operator()(Edge* a, Edge* b) {
return a->distance > b->distance;
}
};
//string startCity;//起始城市
//string endCity;//终点城市
//int distance;//城市间距离
void CreGraph::PrimAlgorithm(string start_city) {
int edgeNum = city_Name.size() - 1;//构建最小连通图需要城市数-1条边
unordered_set<int> marked_City;//标记已经在连接线上的节点
int cur_City_Index = city_Index[start_city];//用变量记录当前正使用城市的下标(原哈希val值)
priority_queue<Edge*, vector<Edge*>, queue_cmp> minEdge;//最小堆优先级队列
while (edgeNum) {
marked_City.insert(cur_City_Index);
for (int column = 0; column < city_Information[cur_City_Index].size(); column++) {
//从邻接矩阵中寻找边
if (city_Information[cur_City_Index][column] > 0 && marked_City.find(column) == marked_City.end()) {
Edge* newEdge = new Edge(cur_City_Index, column, city_Information[cur_City_Index][column]);
minEdge.push(newEdge);//将边放入最小堆
}
}
while (1) {
Edge* edge = minEdge.top();//取出最小堆中距离最短的边
minEdge.pop();
if (marked_City.find(edge->startCity) == marked_City.end() ||
marked_City.find(edge->endCity) == marked_City.end()) {
//根据prim算法,需有一点存于另一个集合中(有一点不存在mark集合之中)
prim_Edges.push_back(edge);
cur_City_Index = edge->endCity;
break;
}
}
edgeNum--;//找到一条边edgeNum减一
}
}
并查集与kruskal算法
并查集
定义:
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。这一类问题近几年来反复出现在信息学的国际国内赛题中。其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受;即使在空间上勉强通过,运行的时间复杂度也极高,根本就不可能在比赛规定的运行时间(1~3秒)内计算出试题需要的结果,只能用并查集来描述。
并查集是一种树型的数据结构,用于处理一些不相交集合(disjoint sets)的合并及查询问题。常常在使用中以森林来表示。
这里推荐一篇关于并查集的博客,解释得非常地道生动,吐血推荐~~~
秒杀并查集-----用故事讲并查集(简单易懂)
并查集代码:
头文件:
#include <iostream>
#include <vector>
#include <queue>
#include <stack>
#include <string>
#include <unordered_map>
#include <unordered_set>
#include <sstream>
#include<algorithm>
using namespace std;
struct Node {
//每个城市
string name;
Node(string name) :name(name){
}
};
class UnionFind {
public:
//key:城市名 value:对应节点位置
unordered_map<string, Node*> name_node;//每个城市对应的节点位置
//key:需要寻找队长的城市 value:上一级位置
unordered_map<Node*, Node*> nameLeader;
//key:队长的位置 value:这个队伍中共有多少成员
unordered_map<Node*, int> leadNum;
void init(vector<string>& city);//初始化城市节点
Node* findCaptain(string name);
bool isSameSet(string name1, string name2);
void unionTwoTeam(string name1, string name2);
};
源文件
#include "UnionFind.h"
//struct Node {//每个城市
// string name;
// Node(string name) :name(name) {}
//};
key:城市名 value:对应节点位置
//unordered_map<string, Node*> name_ndoe;//每个城市对应的节点位置
key:需要寻找队长的城市 value:上一级位置
//unordered_map<Node*, Node*> nameLeader;
key:队长的node value:这个队伍中共有多少成员
//unordered_map<Node*, int> leadNum;
void UnionFind::init(vector<string>& city) {
for (int i = 0; i < city.size(); i++) {
Node* node = new Node(city[i]);
name_node[city[i]] = node;//初始化node_Name哈希表
nameLeader[node] = node;//初始时领导为自己
leadNum[node] = 1;//各成一队,队员为自己(数目为1)
}
}
Node* UnionFind::findCaptain(string name) {
Node* node = name_node[name];
vector<Node*> allNode;//用于收集寻找队长路上的所有节点
while (node != nameLeader[node]) {
//不相等说明此时还没找到“队长”
allNode.push_back(node);
node = nameLeader[node];
}
/*到此,node已经是“队长”节点*/
for (auto nodesOnRoad : allNode) {
//将一路上所有节点都与“队长”相连
nameLeader[nodesOnRoad] = node;//设置这些节点的队长为node
}
return node;
}
bool UnionFind::isSameSet(string name1, string name2) {
Node* captain1 = findCaptain(name1);
Node* captain2 = findCaptain(name2);
return captain1 == captain2;
}
void UnionFind::unionTwoTeam(string name1, string name2) {
if (isSameSet(name1, name2))
return;//已经在一个队伍中就无须合并
Node* captain1 = findCaptain(name1);
Node* captain2 = findCaptain(name2);
int nums1 = leadNum[captain1];
int nums2 = leadNum[captain2];
Node* smallTeam = nums1 > nums2 ? captain2 : captain1;//将较小的队伍合并到较大的队伍中去
Node* bigTeam = smallTeam == captain1 ? captain2 : captain1;
nameLeader[smallTeam] = bigTeam;
leadNum[bigTeam] += leadNum[smallTeam];
leadNum.erase(smallTeam);//合并完成之后原来的队长将被撤销
}
kruskal算法
kruskal算法
假设连通网N=(V,{E})。则令最小生成树的初始状态为只有n个顶点而无边的非连通图T=(V,{}),图中每个顶点自成一个连通分量。在E中选择最小代价的边,若该边依附的顶点落在T中不同的连通分量中,则将该边加入到T中,否则舍去此边而选择下一条代价最小的边,依次类推,直到T中所有顶点都在同一连通分量上为止。
通过前面的并查集的了解,我们能很快想到使用并查集去实现kruskal算法,
代码如下:
vector<Edge*> CreGraph::KruskalAlgorithm() {
priority_queue<Edge*, vector<Edge*>, Queue_cmp> minEdge;//使用最小堆
for (int i = 0; i < city_Information.size(); i++) {
for (int j = 0; j < city_Information[i].size(); j++) {
if (city_Information[i][j]>0) {
Edge* edge = new Edge(i, j, city_Information[i][j]);//创建边并放入最小堆
minEdge.push(edge);
}
}
}
//堆中存储了所有的边,现在我们需要选择权值最小且不在并查集中的边
int times = city_Name.size();
times--;//共需要取出 城市数-1 条边
vector<Edge*> res;
UnionFind ufset;
ufset.init(city_Name);
while (times) {
Edge* edge = minEdge.top();
minEdge.pop();
string startCity = city_Name[edge->startCity];
string endCity = city_Name[edge->endCity];
if (ufset.findCaptain(startCity) != ufset.findCaptain(endCity)) {
//两城市不在同一个集合才可以加入到最终结果当中
res.push_back(edge);//加入结果集
ufset.unionTwoTeam(startCity, endCity);//加入之后合并这两个队伍
times--;
}
}
return res;
}
迪杰斯特拉算法求解最小路径
迪克斯特拉算法
迪杰斯特拉算法(Dijkstra)是由荷兰计算机科学家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉算法。是从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题。迪杰斯特拉算法主要特点是从起始点开始,采用贪心算法的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。
unordered_map<int, pair<int, int>> CreGraph::dijkstra(string destination) {
//key为该城市编号,val分别表示到终点的最短距离&&上一个节点的编号
unordered_map<int, pair<int, int>> dist;//存放该点到终点的最短距离,以及上一个节点的位置
unordered_set<int> includedCity;//存储已经找到最短路径的点
int curindex = city_Index[destination];//初始时该目的城市的下标
dist.insert(make_pair(city_Index[destination], make_pair(0, curindex)));
includedCity.insert(curindex);//起始城市放入set集合进行标记
int nums = city_Name.size();
nums--;
string curcity = destination;
unordered_map<int, pair<int, int>> resDist;
while (nums) {
curindex = city_Index[curcity];
//首先我们需要找到共有多少点与此点相连(这里的“点”代指城市)
for (int i = 0; i < city_Information.size(); i++) {
if (city_Information[i][curindex] && includedCity.find(i) == includedCity.end()) {
//没在结果集中
int distance = city_Information[i][curindex] + dist[curindex].first;//找到的这点到目的点距离
if (dist.find(i) == dist.end() || distance < dist[i].first) {
//该点未存在于结果集中则加入其中
dist[i] = make_pair(distance, curindex);
}
}
}
/*选出与curindex城市相连的点之后需要选出一条距离最短的边*/
int mindist = INT_MAX;
int mincity;//用于记录最小路径上的城市
unordered_map<int, pair<int, int>>::iterator it = dist.begin();
for (; it != dist.end(); it++) {
if ((it->second.first) < mindist && includedCity.find(it->first) == includedCity.end()) {
//该城市距离较小且之前不在最短路径上
mindist = it->second.first;
mincity = it->first;
}
}
resDist.insert(make_pair(mincity, make_pair(mindist, curindex)));
includedCity.insert(mincity);//最短路径上新的城市,将其记录到set集合中
curcity = city_Name[mincity];//更新curcity如此往复去寻找最短路径
nums--;
}
return resDist;
}
完整代码
头文件定义(Graph.h)
#include <iostream>
#include <vector>
#include <queue>
#include <stack>
#include <string>
#include <unordered_map>
#include <unordered_set>
#include <sstream>
#include <algorithm>
#include "UnionFind.h"
using namespace std;
struct Edge {
int startCity;//起始城市的对应哈希val值//可以理解为城市代码、城市编号
int endCity;//终点城市对应哈希val值
int distance;//城市间距离
Edge(int start, int end, int distance) :startCity(start), endCity(end), distance(distance) {
}
};
/*使用哈希表转换信息,使用一个二维数组完成接收*/
class CreGraph {
public:
vector<string> city_Name; //存储所有的城市名
unordered_map<string, int> city_Index;//key值存城市名,val存对应下标
vector<vector<int>> city_Information;//Relation of Citys 城市间关系表
vector<Edge*> prim_Edges;//存放普里姆算法得到图的边
void Create_Graph(vector<string>& city_Name, vector<vector<string>>& city_Information);
void BFS(string start_city);//Broad First Search 广度优先搜索
void DFS(string start_city);//Deep First Search 深度优先搜索
void Recur_DFS(string start_city, unordered_set<int>& visited_City);//递归深度优先搜索
void PrimAlgorithm(string start_city);
vector<Edge*> KruskalAlgorithm();//克鲁斯卡尔算法
unordered_map<int, pair<int, int>> dijkstra(string destination);//迪杰斯特拉算法求解最小路径
};
并查集
头文件定义(UnionFind.h)
#include <iostream>
#include <vector>
#include <queue>
#include <stack>
#include <string>
#include <unordered_map>
#include <unordered_set>
#include <sstream>
#include<algorithm>
using namespace std;
struct Node {
//每个城市
string name;
Node(string name) :name(name) {
}
};
class UnionFind {
public:
//key:城市名 value:对应节点位置
unordered_map<string, Node*> name_node;//每个城市对应的节点位置
//key:需要寻找队长的城市 value:上一级位置
unordered_map<Node*, Node*> nameLeader;
//key:队长的位置 value:这个队伍中共有多少成员
unordered_map<Node*, int> leadNum;
void init(vector<string>& city);//初始化城市节点
Node* findCaptain(string name);
bool isSameSet(string name1, string name2);
void unionTwoTeam(string name1, string name2);
};
并查集源文件(UnionFind.cpp)
#include "UnionFind.h"
//struct Node {//每个城市
// string name;
// Node(string name) :name(name) {}
//};
key:城市名 value:对应节点位置
//unordered_map<string, Node*> name_ndoe;//每个城市对应的节点位置
key:需要寻找队长的城市 value:上一级位置
//unordered_map<Node*, Node*> nameLeader;
key:队长的node value:这个队伍中共有多少成员
//unordered_map<Node*, int> leadNum;
void UnionFind::init(vector<string>& city) {
for (int i = 0; i < city.size(); i++) {
Node* node = new Node(city[i]);
name_node[city[i]] = node;//初始化node_Name哈希表
nameLeader[node] = node;//初始时领导为自己
leadNum[node] = 1;//各成一队,队员为自己(数目为1)
}
}
Node* UnionFind::findCaptain(string name) {
Node* node = name_node[name];
vector<Node*> allNode;//用于收集寻找队长路上的所有节点
while (node != nameLeader[node]) {
//不相等说明此时还没找到“队长”
allNode.push_back(node);
node = nameLeader[node];
}
/*到此,node已经是“队长”节点*/
for (auto nodesOnRoad : allNode) {
//将一路上所有节点都与“队长”相连
nameLeader[nodesOnRoad] = node;//设置这些节点的队长为node
}
return node;
}
bool UnionFind::isSameSet(string name1, string name2) {
Node* captain1 = findCaptain(name1);
Node* captain2 = findCaptain(name2);
return captain1 == captain2;
}
void UnionFind::unionTwoTeam(string name1, string name2) {
if (isSameSet(name1, name2))
return;//已经在一个队伍中就无须合并
Node* captain1 = findCaptain(name1);
Node* captain2 = findCaptain(name2);
int nums1 = leadNum[captain1];
int nums2 = leadNum[captain2];
Node* smallTeam = nums1 > nums2 ? captain2 : captain1;//将较小的队伍合并到较大的队伍中去
Node* bigTeam = smallTeam == captain1 ? captain2 : captain1;
nameLeader[smallTeam] = bigTeam;
leadNum[bigTeam] += leadNum[smallTeam];
leadNum.erase(smallTeam);//合并完成之后原来的队长将被撤销
}
图—源文件(函数实现)(GraphFun.cpp)
#include "Graph.h"
using namespace std;
//vector<string> city_Name;
//unordered_map<string, int> city_Index;//key值存城市名,val存对应下标
//vector<vector<int>> city_Information;//Relation of Citys
void CreGraph::Create_Graph(vector<string>& city_Name, vector<vector<string>>& city_Vertex_Information) {
int len = city_Name.size();
for (int i = 0; i < city_Name.size(); ++i) {
this->city_Index[city_Name[i]] = i;//每个城市给予一个编号
}
this->city_Information.assign(len, vector<int>(len, 0));//初始化
//到哈希表中查找每个城市对应编号,将其记录到startINdex、endIndex
//起始城市:city_Information[i][0];
//目的城市:city_Information[i][1];
//城市间的距离:city_Information[i][2];
for (int i = 0; i < city_Vertex_Information.size(); i++) {
for (int j = 0; j < city_Vertex_Information[i].size(); j++) {
int start_Index = city_Index[city_Vertex_Information[i][0]];
int end_Index = city_Index[city_Vertex_Information[i][1]];
//start、end作为下标,距离就是数组元素的值
stringstream str;
str << city_Vertex_Information[i][2];
int distance;//将字符串转换为整型数据
str >> distance;
this->city_Information[start_Index][end_Index] = distance;
}
}
//输出无向图~
for (int i = 0; i < city_Information.size(); i++) {
for (int j = 0; j < city_Information[i].size(); j++) {
//这里使用printf打印较规范
printf("%d\t", city_Information[i][j]);
}
printf("\n");
}
}
void CreGraph::BFS(string start_city) {
int cur_Index = city_Index[start_city];//找到起始元素下标
queue<int> que;
que.push(cur_Index);
unordered_set<int> visited_City;//生成哈希集合收集访问过元素(防止重复入栈)
visited_City.insert(cur_Index);
while (!que.empty()) {
int cur_City_Index = que.front();
que.pop();
cout << city_Name[cur_City_Index] << " ";//输出当前城市
for (int column = 0; column < city_Information[cur_City_Index].size(); column++) {
int cur_Visited_City = city_Information[cur_City_Index][column];//当前城市正访问的城市
if (cur_Visited_City > 0 && visited_City.find(column) == visited_City.end()) {
que.push(column);//若该城市与之连通且曾未访问过,压入队列
visited_City.insert(column);//将当前访问到的节点放入visited 集合
}
}
}
}
void CreGraph::DFS(string start_city) {
stack<int> stk;
stk.push(city_Index[start_city]);//哈希中查找城市对应下标
unordered_set<int> visited_City;
visited_City.insert(city_Index[start_city]);//初始时将起始城市加入到哈希集合(访问过的城市)中
while (!stk.empty()) {
int cur_visit_City = stk.top();
stk.pop();
cout << city_Name[cur_visit_City] << " ";
for (int column = 0; column < city_Information[cur_visit_City].size(); column++) {
if (city_Information[cur_visit_City][column] > 0 && visited_City.find(column) == visited_City.end()) {
stk.push(column);
visited_City.insert(column);
}
}
}
}
void CreGraph::Recur_DFS(string start_city, unordered_set<int>& visited_City) {
int cur_visit_City = city_Index[start_city];
visited_City.insert(city_Index[start_city]);//初始时将起始城市加入到哈希集合(访问过的城市)中
cout << city_Name[cur_visit_City] << " ";
for (int column = 0; column < city_Information[cur_visit_City].size(); column++) {
if (city_Information[cur_visit_City][column] > 0 && visited_City.find(column) == visited_City.end()) {
visited_City.insert(column);
Recur_DFS(city_Name[column], visited_City);
}
}
}
struct queue_cmp {
//构建最小堆
bool operator()(Edge* a, Edge* b) {
return a->distance > b->distance;
}
};
//string startCity;//起始城市
//string endCity;//终点城市
//int distance;//城市间距离
void CreGraph::PrimAlgorithm(string start_city) {
int edgeNum = city_Name.size() - 1;//构建最小连通图需要城市数-1条边
unordered_set<int> marked_City;//标记已经在连接线上的节点
int cur_City_Index = city_Index[start_city];//用变量记录当前正使用城市的下标(原哈希val值)
priority_queue<Edge*, vector<Edge*>, queue_cmp> minEdge;
while (edgeNum) {
marked_City.insert(cur_City_Index);
for (int column = 0; column < city_Information[cur_City_Index].size(); column++) {
//从邻接矩阵中寻找边
if (city_Information[cur_City_Index][column] > 0 && marked_City.find(column) == marked_City.end()) {
Edge* newEdge = new Edge(cur_City_Index, column, city_Information[cur_City_Index][column]);
minEdge.push(newEdge);//将边放入最小堆
}
}
while (1) {
Edge* edge = minEdge.top();//取出最小堆中距离最短的边
minEdge.pop();
if (marked_City.find(edge->startCity) == marked_City.end() ||
marked_City.find(edge->endCity) == marked_City.end()) {
//根据prim算法,需有一点存于另一个集合中(没在mark集合之中)
prim_Edges.push_back(edge);
cur_City_Index = edge->endCity;
break;
}
}
edgeNum--;
}
}
struct Queue_cmp {
bool operator()(Edge* a, Edge* b) {
return a->distance > b->distance;
}
};
vector<Edge*> CreGraph::KruskalAlgorithm() {
priority_queue<Edge*, vector<Edge*>, Queue_cmp> minEdge;//使用最小堆
for (int i = 0; i < city_Information.size(); i++) {
for (int j = 0; j < city_Information[i].size(); j++) {
if (city_Information[i][j] > 0) {
Edge* edge = new Edge(i, j, city_Information[i][j]);//创建边并放入最小堆
minEdge.push(edge);
}
}
}
//堆中存储了所有的边,现在我们需要选择权值最小且不在并查集中的边
int times = city_Name.size();//共需要取出 城市数-1 条边
times--;
vector<Edge*> res;
UnionFind ufset;
ufset.init(city_Name);
while (times) {
Edge* edge = minEdge.top();
minEdge.pop();
string startCity = city_Name[edge->startCity];
string endCity = city_Name[edge->endCity];
if (ufset.findCaptain(startCity) != ufset.findCaptain(endCity)) {
//两城市不在同一个集合才可以加入到最终结果当中
res.push_back(edge);//加入结果集
ufset.unionTwoTeam(startCity, endCity);//加入之后合并这两个队伍
times--;
}
}
return res;
}
//vector<string> city_Name;
//unordered_map<string, int> city_Index;//key值存城市名,val存对应下标
//vector<vector<int>> city_Information;//Relation of Citys
unordered_map<int, pair<int, int>> CreGraph::dijkstra(string destination) {
//key为该城市编号,val分别表示到终点的最短距离&&上一个节点的编号
unordered_map<int, pair<int, int>> dist;//存放该点到终点的最短距离,以及上一个节点的位置
unordered_set<int> includedCity;//存储已经找到最短路径的点
int curindex = city_Index[destination];//初始时该目的城市的下标
dist.insert(make_pair(city_Index[destination], make_pair(0, curindex)));
includedCity.insert(curindex);//起始城市放入set集合进行标记
int nums = city_Name.size();
nums--;
string curcity = destination;
unordered_map<int, pair<int, int>> resDist;
while (nums) {
curindex = city_Index[curcity];
//首先我们需要找到共有多少点与此点相连(这里的“点”代指城市)
for (int i = 0; i < city_Information.size(); i++) {
if (city_Information[i][curindex] && includedCity.find(i) == includedCity.end()) {
//没在结果集中
int distance = city_Information[i][curindex] + dist[curindex].first;//找到的这点到目的点距离
if (dist.find(i) == dist.end() || distance < dist[i].first) {
//该点未存在于结果集中则加入其中
dist[i] = make_pair(distance, curindex);
}
}
}
/*选出与curindex城市相连的点之后需要选出一条距离最短的边*/
int mindist = INT_MAX;
int mincity;//用于记录最小路径上的城市
unordered_map<int, pair<int, int>>::iterator it = dist.begin();
for (; it != dist.end(); it++) {
if ((it->second.first) < mindist && includedCity.find(it->first) == includedCity.end()) {
//该城市距离较小且之前不在最短路径上
mindist = it->second.first;
mincity = it->first;
}
}
resDist.insert(make_pair(mincity, make_pair(mindist, curindex)));
includedCity.insert(mincity);//最短路径上新的城市,将其记录到set集合中
curcity = city_Name[mincity];//更新curcity如此往复去寻找最短路径
nums--;
}
return resDist;
}
源文件(函数使用)
#include "Graph.h"
using namespace std;
int main() {
vector<vector<string>> city_Vertex_Information;//此城市信息为 邻接矩阵 表示
city_Vertex_Information = {
{
"A","B","12"},
{
"B","A","12"},
{
"A","F","16"},
{
"F","A","16"},
{
"A","G","14"},
{
"G","A","14"},
{
"B","C","10"},
{
"C","B","10"},
{
"B","F","7"},
{
"F","B","7"},
{
"C","D","3"},
{
"D","C","3"},
{
"C","E","5"},
{
"E","C","5"},
{
"C","F","6"},
{
"F","C","6"},
{
"D","E","5"},
{
"E","D","5"},
{
"E","F","2"},
{
"F","E","2"},
{
"F","G","9"},
{
"G","F","9"}
};
CreGraph s;
s.city_Name = {
"A","B","C","D","E","F","G" };
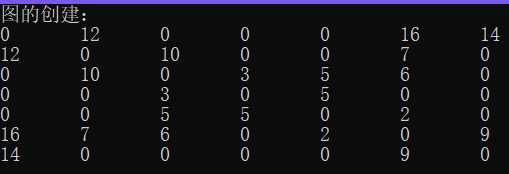
cout << "图的创建:" << endl;
s.Create_Graph(s.city_Name, city_Vertex_Information);
/********************************************************************/
cout << endl << "BFS广度优先搜索:" << endl;
s.BFS("A");
/********************************************************************/
cout << endl << "DFS深度优先搜索:" << endl;
s.DFS("A");
/********************************************************************/
cout << endl << "DFS递归法深度优先搜索:" << endl;
unordered_set<int> visitedCity;
s.Recur_DFS("A", visitedCity);
/********************************************************************/
cout << endl << endl << "迪杰斯塔拉算法:" << endl;
unordered_map<int, pair<int, int>> resDist = s.dijkstra("D");
cout << "dijkstra最小路径:" << endl;
for (auto& p : resDist) {
cout << s.city_Name[p.second.second] << "--->" << s.city_Name[p.first] << ":" << p.second.first << "km" << endl;
}
cout << endl;
/********************************************************************/
city_Vertex_Information = {
{
"邵阳","长沙","235"},
{
"长沙","邵阳","235"},
{
"邵阳","衡阳","141"},
{
"衡阳","邵阳","141"},
{
"邵阳","深圳","697"},
{
"深圳","邵阳","697"},
{
"邵阳","岳阳","364"},
{
"岳阳","邵阳","364"},
{
"长沙","衡阳","190"},
{
"衡阳","长沙","190"},
{
"长沙","深圳","782"},
{
"深圳","长沙","782"},
{
"长沙","大庆","2682"},
{
"大庆","长沙","2682"},
{
"长沙","岳阳","168"},
{
"岳阳","长沙","168"},
{
"衡阳","深圳","641"},
{
"深圳","衡阳","641"},
{
"深圳","大庆","3356"},
{
"大庆","深圳","3356"},
{
"大庆","岳阳","2540"},
{
"岳阳","大庆","2540"}
};
s.city_Name = {
"邵阳","长沙","衡阳","深圳","大庆","岳阳" };
cout << endl << endl << "图的创建:" << endl;
s.Create_Graph(s.city_Name, city_Vertex_Information);
/********************************************************************/
cout << endl << "BFS广度优先搜索:" << endl;
s.BFS("邵阳");
/********************************************************************/
cout << endl << "DFS深度优先搜索:" << endl;
s.DFS("邵阳");
/********************************************************************/
cout << endl << "DFS递归法深度优先搜索:" << endl;
visitedCity.clear();
s.Recur_DFS("邵阳", visitedCity);
/********************************************************************/
cout << endl << endl << "普里姆算法:最小生成树:" << endl;
s.PrimAlgorithm("邵阳");
/********************************************************************/
vector<Edge*> edges;
edges = s.prim_Edges;
for (auto val : edges) {
cout << s.city_Name[val->startCity] << "--->" << s.city_Name[val->endCity] << " :" << val->distance << "km" << endl;
}
/********************************************************************/
cout << endl << "Kruskal算法:";
edges = s.KruskalAlgorithm();
for (auto edge : edges) {
cout << s.city_Name[edge->startCity] << "--->" << s.city_Name[edge->endCity] << ":" << edge->distance << "km" << endl;
}
/********************************************************************/
}
运行图

