https://blog.csdn.net/leesagacious/article/details/73694822
0 : 一些概念
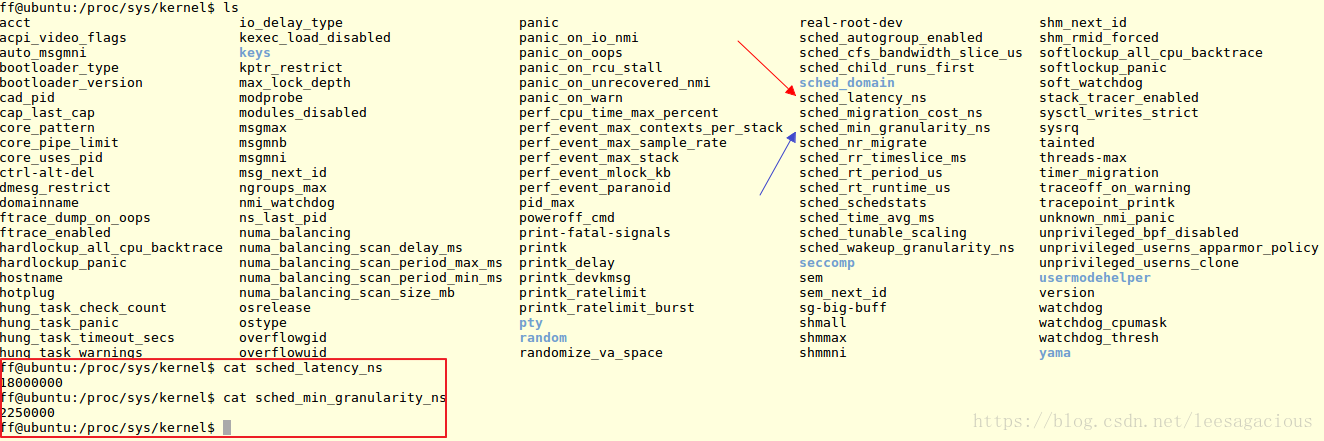
这是我ubuntu上的调度延迟和调度最小颗粒的默认配置,这些配置真的很重要
/**
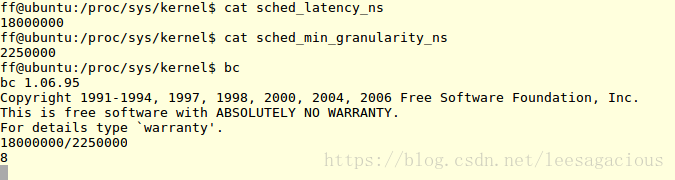
神奇的阿拉伯数字 8 又开始登场了,这次重要了
nr_running : 可运行的Task个数
sched_nr_latency : 默认值为 8,static unsigned int sched_nr_latency = 8;
那么 : 这个是可以自己配置的吗,
既然是被设置为 可配置的参数 ,那么当然是可被配置以适应多种环境了
看unlikely 出现了,除非你是扫地僧,否则别乱动,
好吧,我们就把它当作8来看把,
如果可运行的Task 个数 超过了这个 默认的 8 个,它就不在使用调度延迟了
那么调度周期 = Task 个数 * 调度最小颗粒
如果可运行的Task 个数 小于 8 个,
那么调度周期 = 调度延迟
那么 为什么首先要计算出来调度周期呢 ?
答案是 要分配给Taks们 时间 ,
平均分配 ? 平均地权 ? 那得看该Task有多少斤两了(--权重)
那么 问题来了,什么是调度周期 ? 概念真的很重要 !
举个栗子不太恰当帮你理解 :
一群人排队去面试(或者去银行、xx、xx),每人面试的至少时间就是最小调度颗粒,
即:
任何一个Task,只要分配到了CPU资源,都至少会执行最小调度颗粒这么长的时间
面试完所有的人需要的时间就是调度延迟(不考虑可运行Task 个数 > 8的情况)
即:
每一个可运行的Task都至少运行一次的时间间隔
好吧,每一个被面试者的综合能力(即权重)决定了TA拥有的被面试时间 (不考虑其他情况)
*/
static u64 __sched_period(unsigned long nr_running)
{
/*
可以推理 : 超大型访问量的系统 linux kernel 这个值一定被修改过
好,如果nr_runing 为 0 呢, 是否会选择 idle Task ?
处理的逻辑 可以参见 pick_next_task_fair() 函数
*/
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}