数组和链表
1.数组
数组的长度是固定的
数组只能存储同一种数据类型的元素
注意:在Java中只有一维数组的内存空间是连续,多维数组的内存空间不一定连续。
那么数组又是如何实现随机访问的呢?
寻址公式:i_address = base_address + i * type_length
为什么数组的效率比链表高?
数组是连续存储, 链表是非连续存储
数组的基本操作:
添加 (保证元素的顺序)
最好情况:O(1)
最坏情况:移动n个元素,O(n)
平均情况:移动 n/2 个元素,O(n)
删除 (保证元素的顺序)
最好情况:O(1)
最坏情况:移动n-1个元素,O(n)
平均情况:移动(n-1)/2个元素,O(n)
查找
a. 根据索引查找元素:O(1)
b. 查找数组中与特定值相等的元素
①大小无序:O(n)
②大小有序:O(log2n)
总结: 数组增删慢,查找快。
2.链表
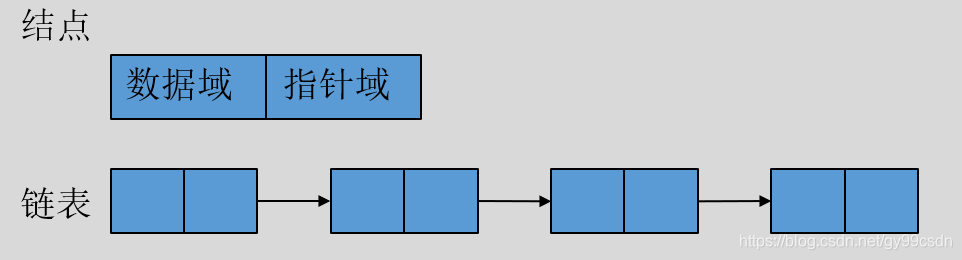
形象地说,链表就是用一串链子将结点串联起来。
结点:包含数据域和指针域。
数据域:数据
指针域:下一个结点的地址
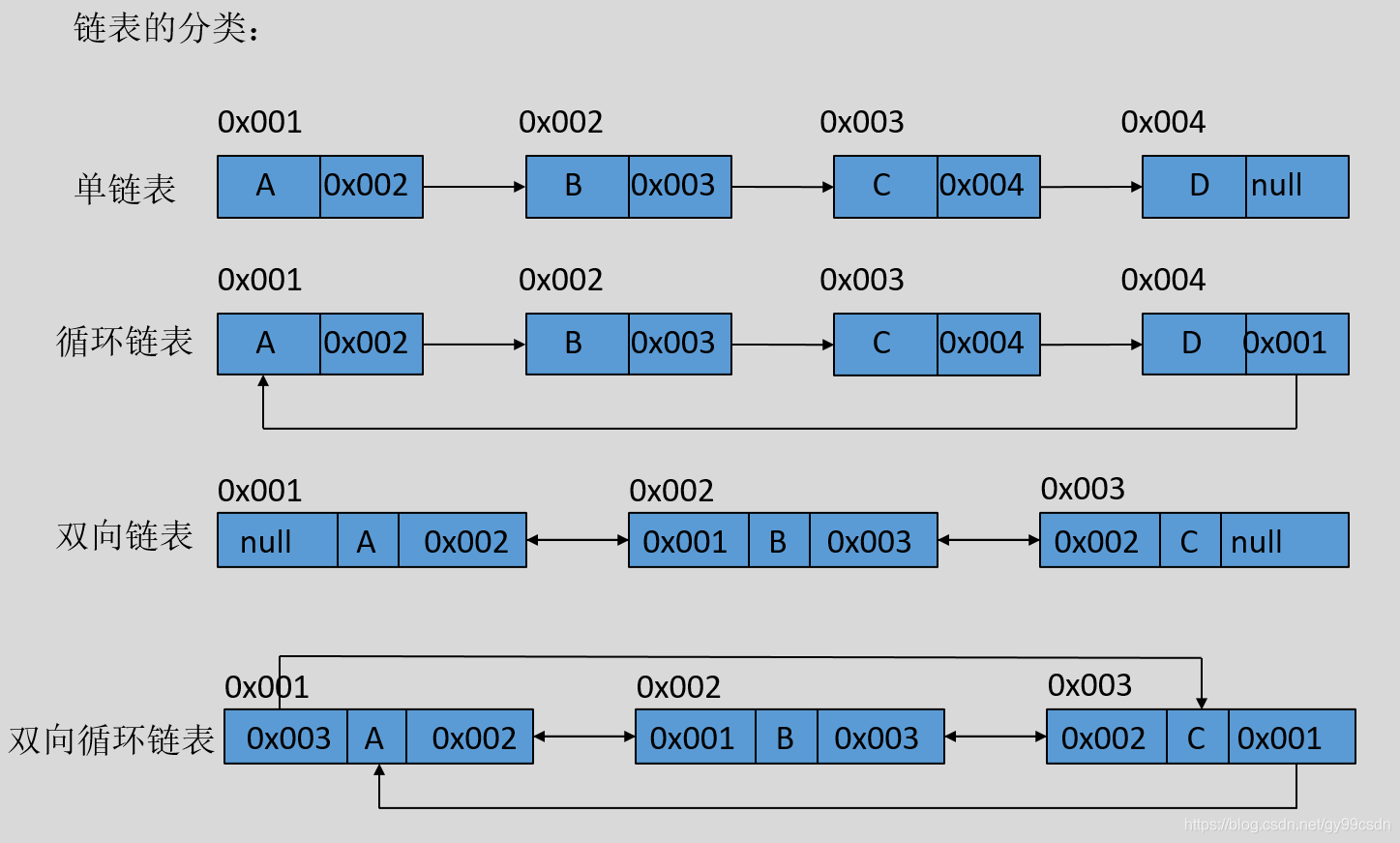
链表及循环链表示例:
Node.java
public class Node {
String value;
Node next;
public Node(String value, Node next) {
this.value = value;
this.next = next;
}
}
LinkedDemo01.java
public class LinkedDemo01 {
public static void main(String[] args) {
Node node1 = new Node("20", null);
Node node2 = new Node("40", node1);
Node node3 = new Node("70", node2);
node1.next=node3;//创建循环链表
System.out.println("输出节点node1的next节点node3的值:"+node1.next.value);
//
//node3->node2->node1
//node3.next.next等价于->node1
System.out.println("输出节点node3的next的next节点的地址:"+node3.next.next.next);
Node nexttest= node2.next;//nexttest即为node1的地址对象
System.out.println("输出nexttest即为node1的地址对象:"+nexttest);
String str="zs";
System.out.println(str);
}
}
结果输出:
输出节点node1的next节点node3的值:70
输出节点node3的next的next节点的地址:com.ketang.day28_20210131.Node@1b6d3586
输出nexttest即为node1的地址对象:com.ketang.day28_20210131.Node@4554617c
zs
双向链表及双向循环链表示例:
DBNode.java
public class DBNode {
String value;
DBNode pre;
DBNode next;
public DBNode(String value, DBNode pre, DBNode next) {
this.value = value;
this.pre = pre;
this.next = next;
}
}
DBNodeDemo.java
public class DBNodeDemo {
public static void main(String[] args) {
DBNode dbNode1 = new DBNode("1", null, null);
DBNode dbNode2 = new DBNode("2", dbNode1, null);
DBNode dbNode3 = new DBNode("3", dbNode2, null);
DBNode dbNode4 = new DBNode("4", dbNode3, null);
// //实现1-->2-->3-->4的双向链表
// // 1<--2<--3<--4
dbNode1.next=dbNode2;
dbNode2.next=dbNode3;
dbNode3.next=dbNode4;
System.out.println(dbNode3.pre.pre.value);
//实现双向循环链表
dbNode1.pre=dbNode4;
dbNode4.next=dbNode1;
System.out.println(dbNode4.next.value);
System.out.println(dbNode1.pre.value);
}
}
DBNodeDemo.java
class DBNodeDemo {
public static void main(String[] args) {
DBNode dbNode1 = new DBNode("1", null, null);
DBNode dbNode2 = new DBNode("2", dbNode1, null);
DBNode dbNode3 = new DBNode("3", dbNode2, null);
DBNode dbNode4 = new DBNode("4", dbNode3, null);
// //实现1-->2-->3-->4的双向链表
// // 1<--2<--3<--4
dbNode1.next=dbNode2;
dbNode2.next=dbNode3;
dbNode3.next=dbNode4;
System.out.println("输出dbNode3节点pre的pre节点dbNode1的值:"+dbNode3.pre.pre.value);
//实现双向循环链表
dbNode1.pre=dbNode4;
dbNode4.next=dbNode1;
System.out.println("输出dbNode4节点next节点dbNode1的值:"+dbNode4.next.value);
System.out.println("输出dbNode1节点pre节点dbNode4的值:"+dbNode1.pre.value);
}
}
结果输出:
输出dbNode3节点pre的pre节点dbNode1的值:1
输出dbNode4节点next节点dbNode1的值:1
输出dbNode1节点pre节点dbNode4的值:4
循环链表我们用的一般比较少,但是当处理的数据具有环形结构时,就特别适合用循环链表,比如约瑟夫问题。
单链表:
增加(在某个结点后面添加)
//添加方法
public boolean add(String str) {
//判断链表是否为空
if (top == null || size == 0) {
//代表一个空链表
top = new Node(str, null);//创建头节点
size++;//长度加一
return true;
}
//查找尾节点
Node mid = top;
while (mid.next != null) {
mid = mid.next;
}
//上述循环的跳出条件,就是mid是尾节点
mid.next = new Node(str, null);//从尾节点开始添加节点
size++;
return true;
}
删除(在某个结点后面删除)
//删除方法
public String delete(String str) {
// TODO:参数验证
if (top == null || size == 0) throw new RuntimeException("linked is null");
//如果要删除的是头结点
if (top.value.equals(str)) {
//要删除的节点是头结点
top = top.next;
size--;
return str;
}
//如果要删除的不是头结点
Node mid = top;
while (mid.next != null && !mid.next.value.equals(str)) {
//一直向后查找
mid = mid.next;
}
//意味着
//1.mid.next=null,没有删除的元素
//2.mid,next就是要删除的点
if (mid.next == null) {
//没找到
return null;
}
//mid.next要找的节点
mid.next = mid.next.next;//覆盖删除
size--;
return str;
}
修改:
//修改方法
public boolean set(String oldStr, String newStr) {
//TODO:参数验证:
if (top == null || size == 0) throw new RuntimeException("likend is null");
//修改是否是头结点
if (top.value.equals(oldStr)) {
//就是要修改头结点
top.value = newStr;
return true;
}
//修改的不是头结点,一直向下寻找
Node mid = top;
//查找要替换的元素
while (mid.next != null && !mid.next.value.equals(oldStr)) {
mid = mid.next;
}
//没找到
if (mid.next == null) {
return false;
}
//必然找到
mid.next.value = newStr;
return true;
}
查找:
a. 根据索引查找元素
b. 查找链表中与特定值相等的元素
①元素大小有序
②元素大小无序
总结:链表增删快,查找慢。
单链表增删改示例:
MyLinked.java
public class MyLinked {
//单链表
Node top;//头结点
int size;
@Override
public String toString() {
return "MyLinked{" +
"top=" + top +
", size=" + size +
'}';
}
//添加方法
public boolean add(String str) {
//判断链表是否为空
if (top == null || size == 0) {
//代表一个空链表
top = new Node(str, null);//创建头节点
size++;//长度加一
return true;
}
//查找尾节点
Node mid = top;
while (mid.next != null) {
mid = mid.next;
}
//上述循环的跳出条件,就是mid是尾节点
mid.next = new Node(str, null);//从尾节点开始添加节点
size++;
return true;
}
//删除方法
public String delete(String str) {
// TODO:参数验证
if (top == null || size == 0) throw new RuntimeException("linked is null");
//如果要删除的是头结点
if (top.value.equals(str)) {
//要删除的节点是头结点
top = top.next;
size--;
return str;
}
//如果要删除的不是头结点
Node mid = top;
while (mid.next != null && !mid.next.value.equals(str)) {
//一直向后查找
mid = mid.next;
}
//意味着
//1.mid.next=null,没有删除的元素
//2.mid,next就是要删除的点
if (mid.next == null) {
//没找到
return null;
}
//mid.next要找的节点
mid.next = mid.next.next;//覆盖删除
size--;
return str;
}
//修改方法
public boolean set(String oldStr, String newStr) {
//TODO:参数验证:
if (top == null || size == 0) throw new RuntimeException("likend is null");
//修改是否是头结点
if (top.value.equals(oldStr)) {
//就是要修改头结点
top.value = newStr;
return true;
}
//修改的不是头结点,一直向下寻找
Node mid = top;
//查找要替换的元素
while (mid.next != null && !mid.next.value.equals(oldStr)) {
mid = mid.next;
}
//没找到
if (mid.next == null) {
return false;
}
//必然找到
mid.next.value = newStr;
return true;
}
//查找方法
public boolean find(String str){
//TODO:参数验证:
if (top == null || size == 0) throw new RuntimeException("likend is null");
//头结点是否是要查找的元素
if (top.value.equals(str)) {
return true;
}
Node mid=top;
//查找指定的元素
while (mid.next != null && !mid.next.value.equals(str)) {
mid = mid.next;
}
//没找到
if (mid.next == null) {
return false;
}else//否则找到
return true;
}
class Node {
String value;
Node next;
public Node(String value, Node next) {
this.value = value;
this.next = next;
}
@Override
public String toString() {
return "Node{" +
"value='" + value + '\'' +
", next=" + next +
'}';
}
}
}
MyLinkedtest.java
public class MyLinkedtest {
public static void main(String[] args) {
MyLinked myLinked = new MyLinked();
myLinked.add("dd");
myLinked.add("gg");
myLinked.add("ss");
System.out.println(myLinked.toString());
String gg = myLinked.delete("gg");
System.out.println("删除gg后的链表:" + myLinked);
myLinked.set("dd", "aa");
myLinked.set("ss", "agrnzb");
System.out.println("修改后的链表:" + myLinked);
System.out.println("是否找到指定元素:" +myLinked.find("dd"));
System.out.println("是否找到指定元素:" +myLinked.find("gg"));
System.out.println("是否找到指定元素:" +myLinked.find("ss"));
System.out.println("是否找到指定元素:" +myLinked.find("agrnzb"));
}
}
结果输出;
MyLinked{
top=Node{
value='dd', next=Node{
value='gg', next=Node{
value='ss', next=null}}}, size=3}
删除gg后的链表:MyLinked{
top=Node{
value='dd', next=Node{
value='ss', next=null}}, size=2}
修改后的链表:MyLinked{
top=Node{
value='aa', next=Node{
value='agrnzb', next=null}}, size=2}
是否找到指定元素:false
是否找到指定元素:false
是否找到指定元素:false
是否找到指定元素:true
承接以上代码实现:(根据下标删除元素)
/* 根据下标删除元素*/
public boolean deleteindex(int index) {
if (top == null || size == 0) throw new RuntimeException("likend is null");
if (index >= size) throw new RuntimeException("越界异常:indexOutOfBoundsException!");
Node mid = top;
//如果节点为第一个节点
if (index == 0) {
System.out.println("第一个节点已删除!");
top = top.next;//将头结点指向第二个节点
size--;
return true;
}
//找到删除节点的前一个节点
int j = 0;
while (mid.next != null && j < index - 1) {
top = top.next;
j++;
}
top.next = top.next.next;
size--;
return true;
}
结果输出;
MyLinked{
top=Node{
value='dd', next=Node{
value='gg', next=Node{
value='ss', next=null}}}, size=3}
是否删除下标为1的元素:true
删除下标为1元素后的单链表:MyLinked{
top=Node{
value='dd', next=Node{
value='ss', next=null}}, size=2}
Exception in thread "main" java.lang.RuntimeException: 越界异常:indexOutOfBoundsException!
at com.ketang.day28_20210131.MyLinked.MyLinked.deleteindex(MyLinked.java:123)
at com.ketang.day28_20210131.MyLinked.MyLinkedtest.main(MyLinkedtest.java:32)
双向链表:
双向链表和单链表的时间复杂度是一样的,但双向链表有单链表没有的独特魅力——它有一条指向前驱结点的链接。(双向链表更常用)
增加 (在某个结点前面添加元素)
删除 (删除该结点)
查找
a. 查找前驱结点
b. 根据索引查找元素
c. 查找链表中与特定值相等的元素
① 元素大小无序
② 元素大小有序
//查找方法
public boolean find(String str){
//TODO:参数验证:
if (top == null || size == 0) throw new RuntimeException("likend is null");
//头结点是否是要查找的元素
if (top.value.equals(str)) {
return true;
}
Node mid=top;
//查找指定的元素
while (mid.next != null && !mid.next.value.equals(str)) {
mid = mid.next;
}
//没找到
if (mid.next == null) {
return false;
}else//否则找到
return true;
}
总结:虽然双向链表更占用内存空间,但是它在某些操作上的性能是优于单链表的。
思想:用空间换取时间。
练习:
1.求链表的中间元素:
解题思路:
定义两个指针fast和slow。slow一次遍历一个节点,fast一次遍历两个节点,由于fast的速度是slow的两倍,所以当fast遍历完链表时,slow所处的节点就是链表的中间节点。
public class practise01 {
public static void main(String[] args) {
Node node1 = new Node("1", null);
Node node2 = new Node("2", node1);
Node node3 = new Node("3", node2);
Node node4 = new Node("4", node3);
Node node5 = new Node("5", node4);
Node z=middleNode(node5);
System.out.println(z);
}
public static Node middleNode(Node head) {
if (head == null || head.next == null) {
return head;
}
Node fast = head.next;//快指针
Node low = head;//慢指针
//快指针走两步,慢指针走一步
while (fast != null && fast.next != null) {
fast = fast.next.next;
low = low.next;
}
return fast == null ? low : low.next;
}
}
结果输出:
Node{
value='3', next=Node{
value='2', next=Node{
value='1', next=null}}}
2.判断链表中是否有环(circle)
3.反转单链表
3.总结

1.数组是连续内存,CPU的高速缓存可预读数据(链表不能)。若数组过大无连续空间,会抛出OOM、
2.数组的缺点是大小固定。数组太大,浪费内存空间;数组太小,需重新申请更大数组,并将数据拷贝过去,耗时。
3.若对内存的使用苛刻,数组更适合。因结点有指针域,更耗内存。且对链表的频繁插入和删除,会导致结点对象的频繁创建和销毁,有可能会导致频繁的GC活动。