本文以 IBM M. Jones 所著文章为雏形,更正了部分翻译术语,并增加了内存管理的内容,从宏观上讲述 Linux 内核与用户空间隔离的原因,为什么出现了相应的访问 API,大体上介绍内核与用户空间访问的一般模型。如果你想更深入的了解一些内核与用户空间实际交互的案例,请访问:设备驱动与 ioctl 函数详细分析
内存管理
为什么现代操作系统要使用虚拟地址空间而不是直接使用物理内存?1 其实早期的计算机,程序确实是直接使用物理内存的。随着编程技术不断的发展,有一个新的问题摆在人们面前,如何提高内存效率,将有限的物理内存分配给多个程序使用?
假设计算机拥有 256M 内存,程序 A 需要100M,程序 B 需要 150 M,程序 C 需要 50 M,一种常见的作法是,0 ~ 99 分配给 A,100 ~ 199 分配给 B,这样做的问题有三
- 进程地址空间不隔离,虽然每个进程分配了不同的物理地址段,但是由于没有 MMU(内存管理单元)不同进程可以越界访问其他进程空间,可能造成内存数据读写混乱
- 内存使用效率低,C 运行,就必须把内存中的 A 交换到磁盘中,每次这样,硬盘的大量读写数据,性能其实是很低的
- 程序运行地址不确定,程序每次装入时,分配的空间内存地址都不是固定的,但是实际编程中,我们可能总需要访问特定地址的数据
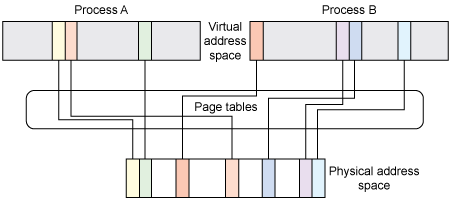
在这种情况下,出现了虚拟地址空间的概念。通过增加中间层的方式,间接访问物理地址。也就是说,把程序给出的地址看作是虚拟地址,通过某种映射方法,将这个虚拟地址转换成实际的物理地址。最终的目的是,每个程序能够访问的物理内存区域相互隔离,不重叠。
每个进程(和内核)会有相同地址指向不同的物理内存区域,不可能立即共享内存。但是有时候我们也需要特意的让两个进程能够共享一块内存区域,幸运的是,有一些解决方案。用户进程可以通过 Portable Operating System Interface for UNIX® (POSIX) 共享的内存机制(shmem)共享内存,但有一点要说明,每个进程可能有一个指向相同物理内存区域的不同虚拟地址。
页表
虚拟内存到物理内存的映射是通过页表完成的,页表是一种特殊的数据结构,操作系统管理页表
- 页/页面:通常将虚拟地址空间以 512Byte ~ 8K,作为一个单位,称为页,并从 0 开始依次对每一个页编号。这个大小通常被称为页面
- 块:将物理地址按照同样的大小,作为一个单位,称为框或者块
- 页表:操作系统通过维护一张表,这张表上记录了每一对页和框的映射关系,即页表
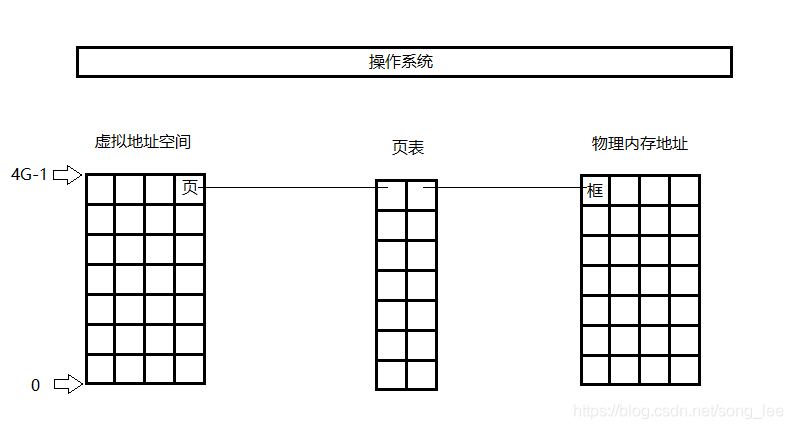
CPU 中有一个页表寄存器,里面存放着当前进程页表的起始地址和页表长度。也就是说,硬件本身提供映射机制,内核则是负责页表的管理和配置。
有时候,进程可能需要一个较大的地址空间,物理内存可能常常不够使用。为此,paging 即 linux 中的 swap,会将较少使用的页移到速度较慢的存储设备,比如硬盘。Linux 中经常使用的 swap 分区就是用来存储这些不常用的页。
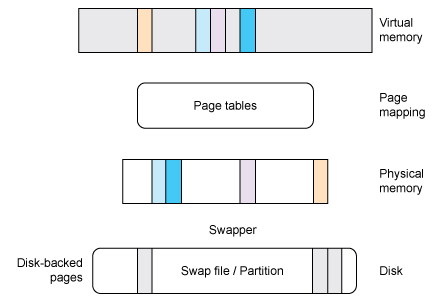
选择一个页面来交换存储的过程被称为一个页面置换算法,可以通过使用许多算法(至少是最近使用的)来实现。这些都是《操作系统原理》课程中,曾经学过的知识,在此不再多说。
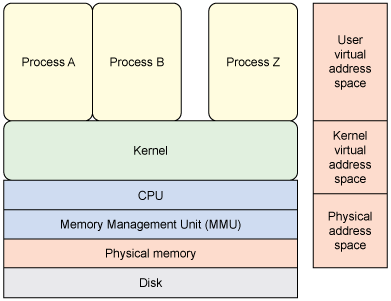
并不是所有的页面都适合交换。例如,响应中断的内核代码或者管理页表和交换逻辑的代码,这些页面决不能被换出,因此它们是固定的,或者是永久地驻留在内存中。尽管内核页面不需要进行交换,然而用户页面需要,但是它们可以被固定,通过 mlock(或 mlockall)函数来锁定页面。这就是用户空间内存访问函数的目的。如果内核假设一个用户传递的地址是有效的且是可访问的,最终可能会出现内核严重错误(kernel panic)(例如,因为用户页面被换出,而导致内核中的页面错误)。该应用程序编程接口(API)确保这些边界情况被妥善处理。2
内核 API
以下是用户空间内存访问 API,这些函数经常出现在驱动层面,且不依赖于特定的架构
| 函数 | 描述 |
|---|---|
access_ok |
检查用户空间内存指针的有效性 |
copy_to_user |
将数据从内核空间复制到用户空间 |
copy_from_user |
将数据从用户空间复制到内核空间 |
strnlen_user |
用户空间内存中缓冲区字符串的长度 |
strncpy_from_user |
从用户空间复制一个字符串到内核 |
get_user |
从用户空间获取一个简单变量 |
put_user |
向用户空间输入一个简单变量 |
下图可以更加详细的说明这些函数的调用情况
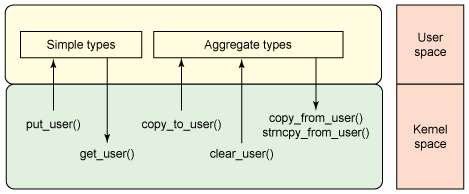
access_ok
access_ok 函数在想要访问的用户空间检查指针的有效性。调用函数提供指向数据块的开始的指针、块大小和访问类型(无论这个区域是用来读还是写的)。函数原型定义如下:
access_ok( type, addr, size );
type 参数可以被指定为 VERIFY_READ 或 VERIFY_WRITE。VERIFY_WRITE 也可以识别内存区域是否可读以及可写(尽管访问仍然会生成 -EFAULT)。该函数简单检查地址可能是在用户空间,而不是内核。
get_user
要从用户空间读取一个简单变量,可以使用 get_user 函数,该函数适用于简单数据类型,比如,char 和 int,但是像结构体这类较大的数据类型,必须使用 copy_from_user 函数。该原型接受一个变量(存储数据)和一个用户空间地址来进行 Read 操作
get_user( x, ptr );
get_user 函数将映射到两个内部函数其中的一个。在系统内部,这个函数决定被访问变量的大小(根据提供的变量存储结果)并通过 __get_user_x 形成一个内部调用。成功时该函数返回 0
put_user
可以使用 put_user 函数来将一个简单变量从内核写入用户空间。和 get_user 一样,它接受一个变量(包含要写的值)和一个用户空间地址作为写目标:
put_user( x, ptr );
和 get_user 一样,put_user 函数被内部映射到 put_user_x 函数 ,成功时,返回 0,出现错误时,返回 -EFAULT。
copy_to_user
copy_to_user 函数将数据块从内核复制到用户空间。该函数接受一个指向用户空间缓冲区的指针、一个指向内存缓冲区的指针、以及一个以字节定义的长度。该函数在成功时,返回 0,否则返回一个非零数,指出不能发送的字节数。
copy_to_user( to, from, n );
copy_from_user
copy_from_user 函数将数据块从用户空间复制到内核缓冲区。它接受一个目的缓冲区(在内核空间)、一个源缓冲区(从用户空间)和一个以字节定义的长度。和 copy_to_user 一样,该函数在成功时,返回 0 ,否则返回一个非零数,指出不能复制的字节数。
copy_from_user( to, from, n );
该函数首先检查从用户空间源缓冲区读取的能力(通过 access_ok),然后调用 __copy_from_user,最后调用 __copy_from_user_ll。从此开始,根据构架,为执行从用户缓冲区到内核缓冲区的零拷贝(不可用字节)而进行一个调用。优化组装函数包含管理功能。
总结
本文多数来源于 IBM M. Jones 的翻译,增加了内存分页的说明,并修改了许多翻译错误的地方。这里只是粗略介绍一下,内核与用户交互常用的一些函数,如果你觉得本文只是泛泛而谈,并没有实际的说明,如果你还想看一下实际案例,内核和用户空间数据传输,在代码上到底是如何表现的,可以访问笔者之前的一篇文章:设备驱动与 ioctl 函数详细分析