
GPT
无监督的预训练(LM)+有监督微调(task-specific)(多任务学习)
Unsupervised pre-training
语料库 U U U = {
u 1 u_1 u1,…, u n u_n un},LM(multi-layer Transformer decoder)损失:
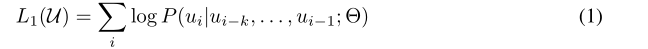
具体:
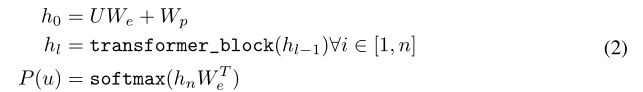
Supervised fine-tuning
输入句子:{
x 1 x_1 x1,…, x m x_m xm},lable: y y y
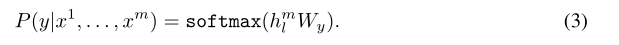
Loss:
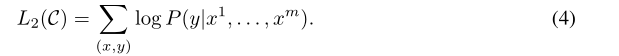
Unsupervised pre-training LM辅助 Supervised fine-tuning:

对task-specific的结构
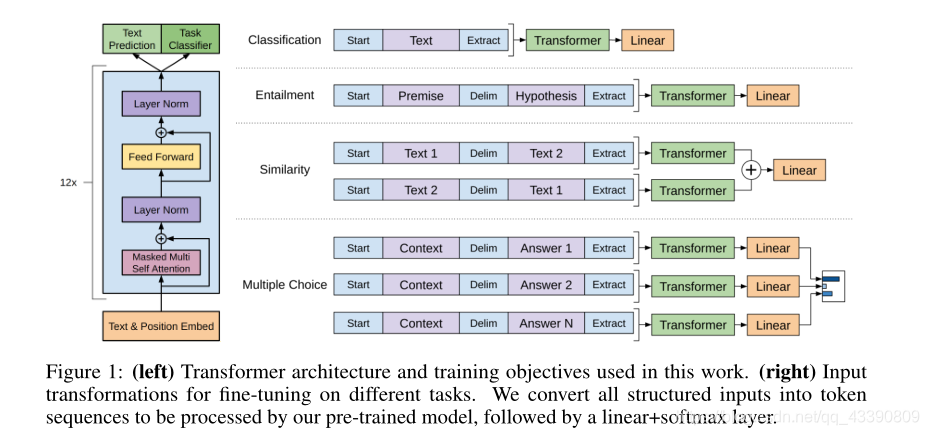
setup
12 layer Transformer decoder( with GELU) with masked self-attention heads(768hidden_size=768,12 attention head) ,FFN:3072维度。使用了学习过的位置嵌入,而不是正弦形式。我
GPT2
整体架构依旧是Transformer decoder,与GPT的区别:
1.GPT2去掉了微调层,只用LM
2.用了一个更大的数据集训练(40G:WebText)(成果)
3.GPT2使用48层Transformer。隐藏层维度为1600,参数15亿(-.-!)
4.将layer norm放在sub-block之前,并在最后一个self-attention后再增加一个layer norm
5.GPT-2将词汇表数量增加到50000个;最大的上下文大小 (context size) 从GPT的512提升到了1024 tokens;batch_size增加到512。
6.GPT-2 有一个叫做「top-k」的参数,模型会从概率前 k 大的单词中抽样选取下一个单词。显然,在之前的情况下,top-k = 1。
内部原理
参考https://www.cnblogs.com/zhongzhaoxie/p/13064404.html
1.输入编码
首先,从模型的输入开始。GPT-2 从嵌入矩阵中查找单词对应的嵌入向量,该矩阵也是模型训练结果的一部分。
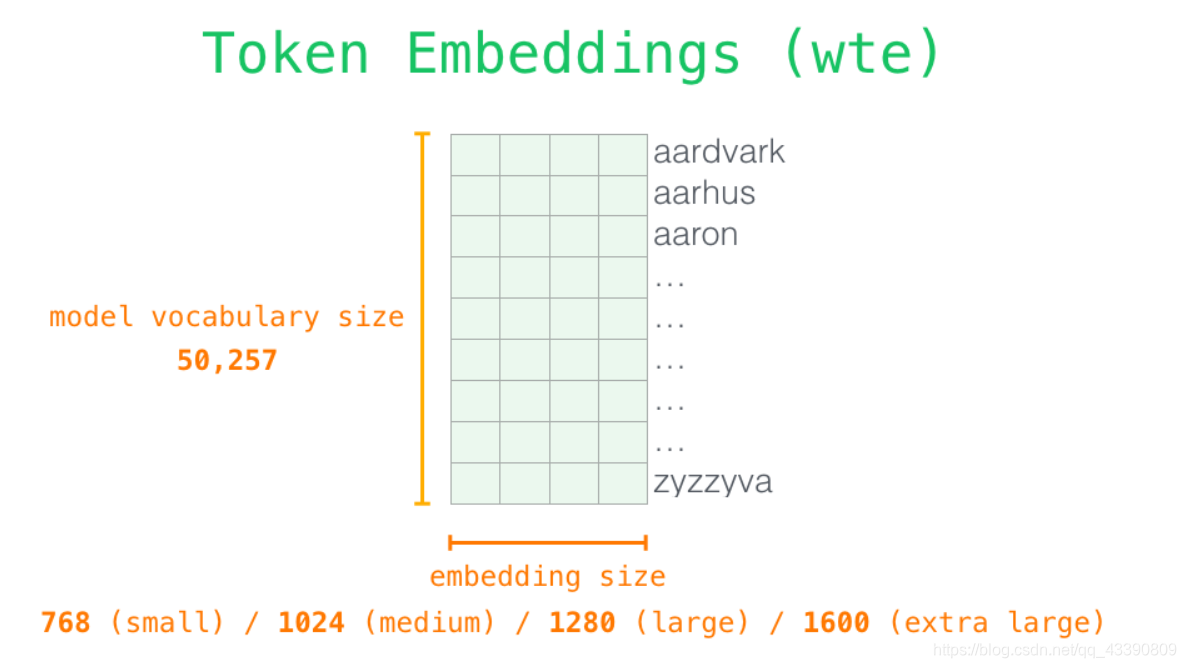
每一行都是一个词嵌入向量:一个能够表征某个单词,并捕获其意义的数字列表。嵌入向量的长度和 GPT-2 模型的大小有关,最小的模型使用了长为 768 的嵌入向量来表征一个单词。
所以在一开始,需要在嵌入矩阵中查找起始单词s对应的嵌入向量。但在将其输入给模型之前,还需要引入位置编码------一些向 transformer 模块指出序列中的单词顺序的信号。1024 个输入序列位置中的每一个都对应一个位置编码,这些编码组成的矩阵也是训练模型的一部分。
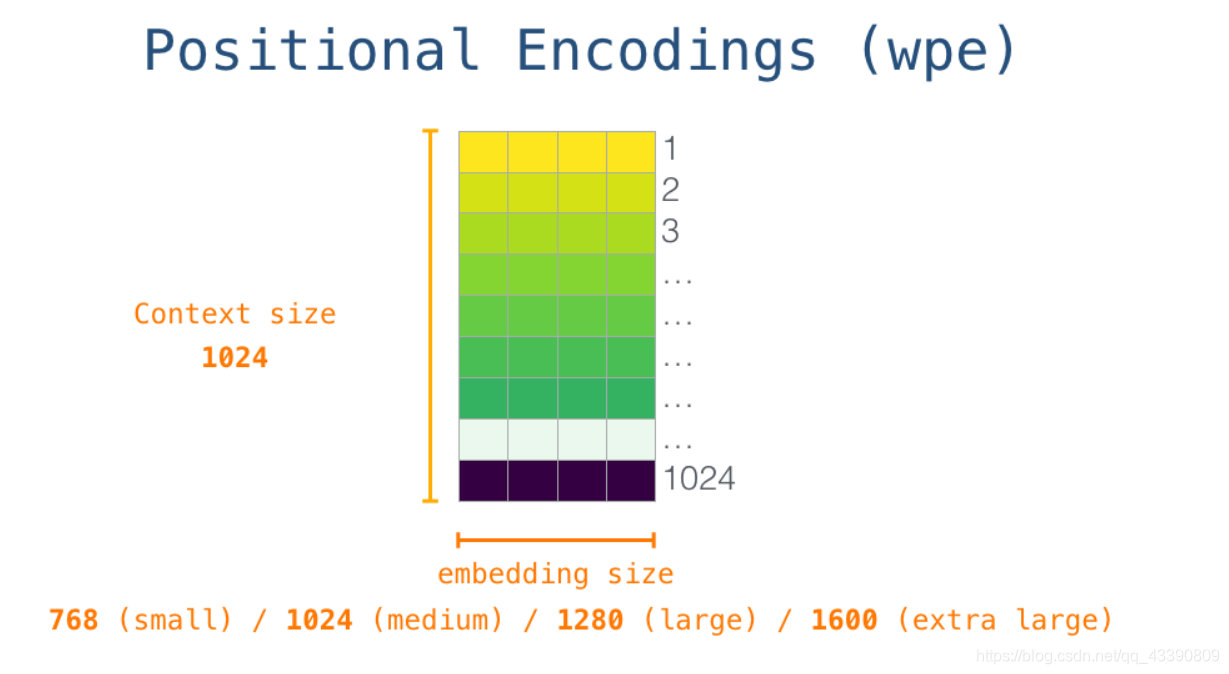
至此,输入单词在进入模型第一个 transformer 模块之前所有的处理步骤就结束了。如上文所述,训练后的 GPT-2 模型包含两个权值矩阵:嵌入矩阵和位置编码矩阵。
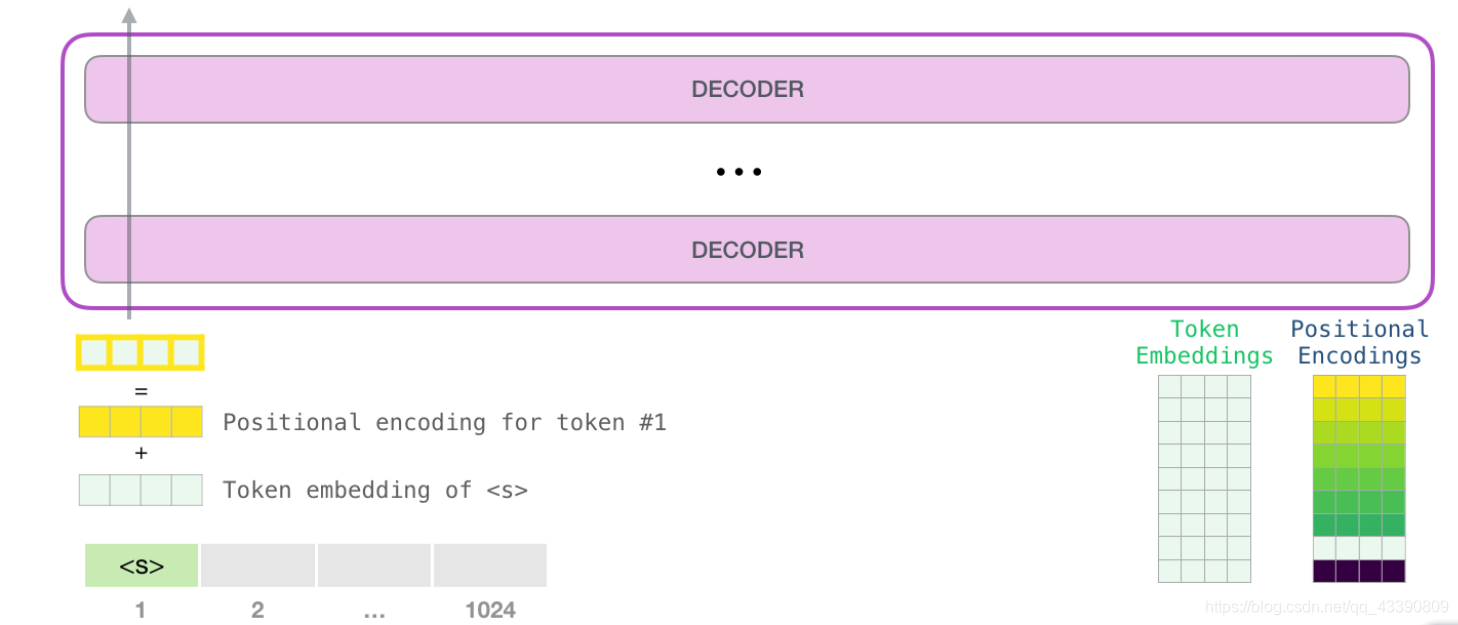
将单词输入第一个 transformer 模块之前需要查到它对应的嵌入向量,再加上 1 号位置位置对应的位置向量。
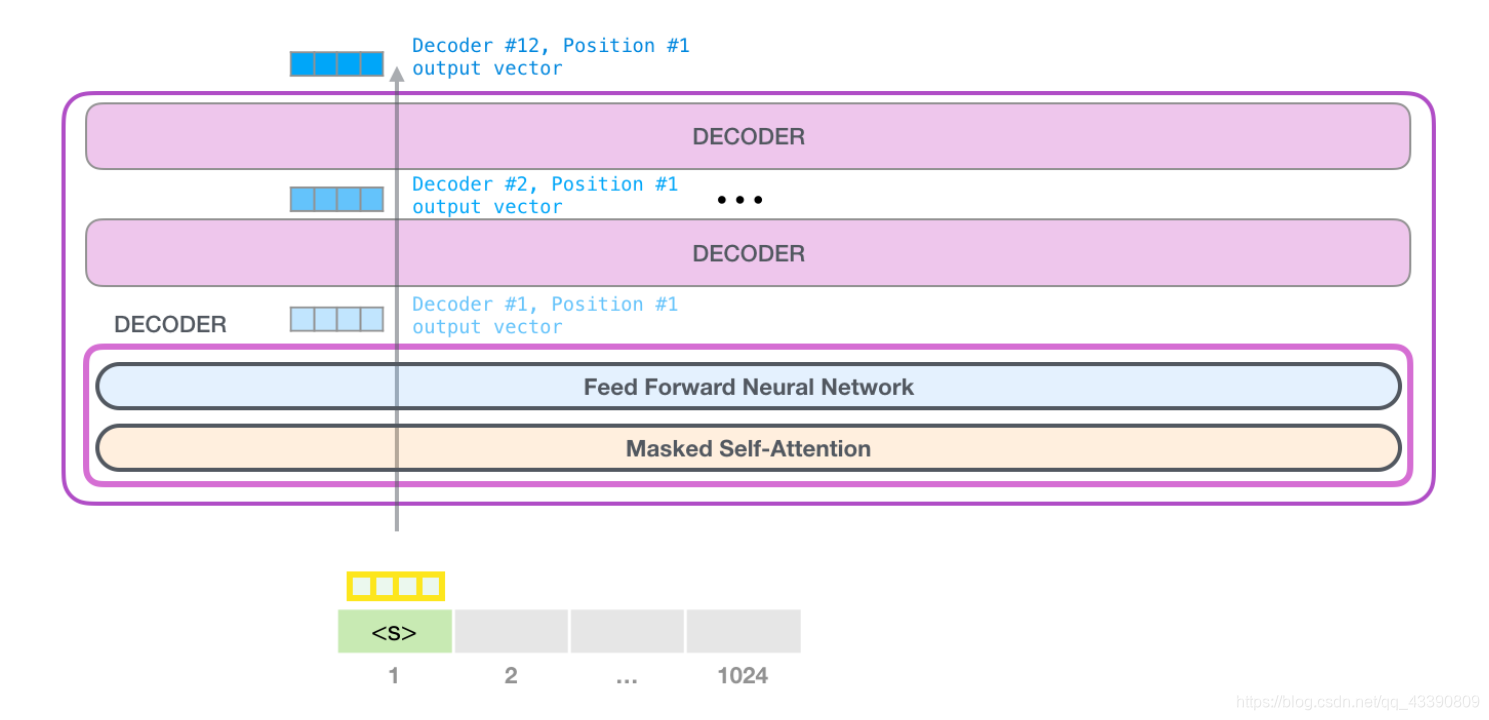
2.堆叠
第一个 transformer 模块处理单词的步骤如下:首先通过自注意力层处理,接着将其传递给神经网络层。第一个 transformer 模块处理完但此后,会将结果向量被传入堆栈中的下一个 transformer 模块,继续进行计算。每一个 transformer 模块的处理方式都是一样的,但每个模块都会维护自己的自注意力层和神经网络层中的权重。
自注意力机制
语言的含义是极度依赖上下文的,比如下面这个机器人第二法则:
机器人第二法则
机器人必须遵守人类给它的命令,除非该命令违背了第一法则。
这句话中,必须要让模型知道:
- 【它】指代机器人
- 【命令】即【人类给它的命令】
- 【第一法则】指代第一法则的完整内容
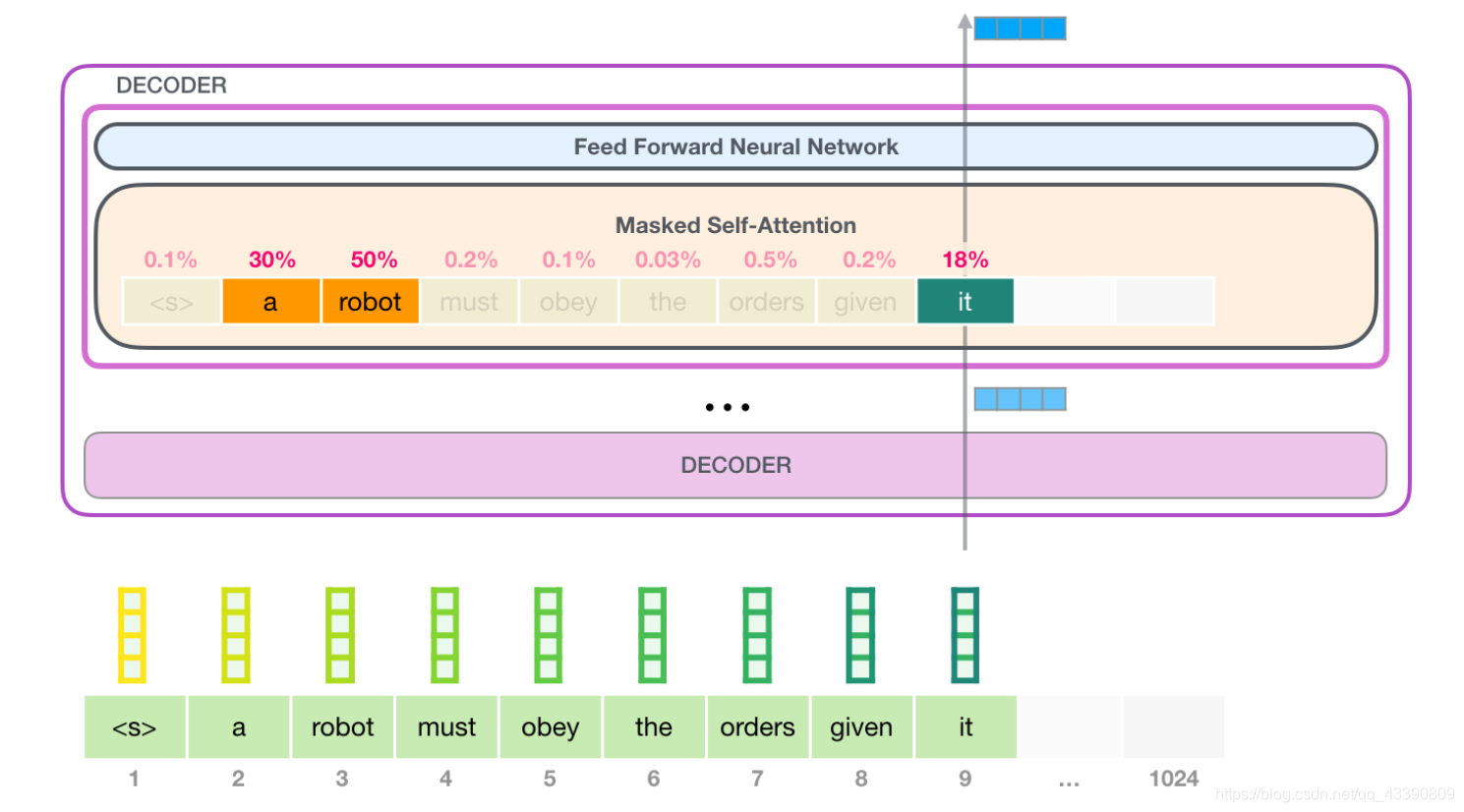
这就是自注意力机制所做的工作,它在处理每个单词(将其传入神经网络)之前,融入了模型对于用来解释某个单词的上下文的相关单词的理解。具体做法是,给序列中每一个单词都赋予一个相关度得分,之后对他们的向量表征求和。
举个例子,最上层的 transformer 模块在处理单词「it」的时候会关注「a robot」,所以「a」、「robot」、「it」这三个单词与其得分相乘加权求和后的特征向量会被送入之后的神经网络层。即:
自注意力机制沿着序列中每一个单词的路径进行处理,主要由 3 个向量组成:
- 查询向量(Query 向量):当前单词的查询向量被用来和其它单词的键向量相乘,从而得到其它词相对于当前词的注意力得分。只关心目前正在处理的单词的查询向量。
- 键向量(Key 向量):键向量就像是序列中每个单词的标签,它是搜索相关单词时用来匹配的对象。
- 值向量(Value 向量):值向量是单词真正的表征,当算出注意力得分后,使用值向量进行加权求和得到能代表当前位置上下文的向量。
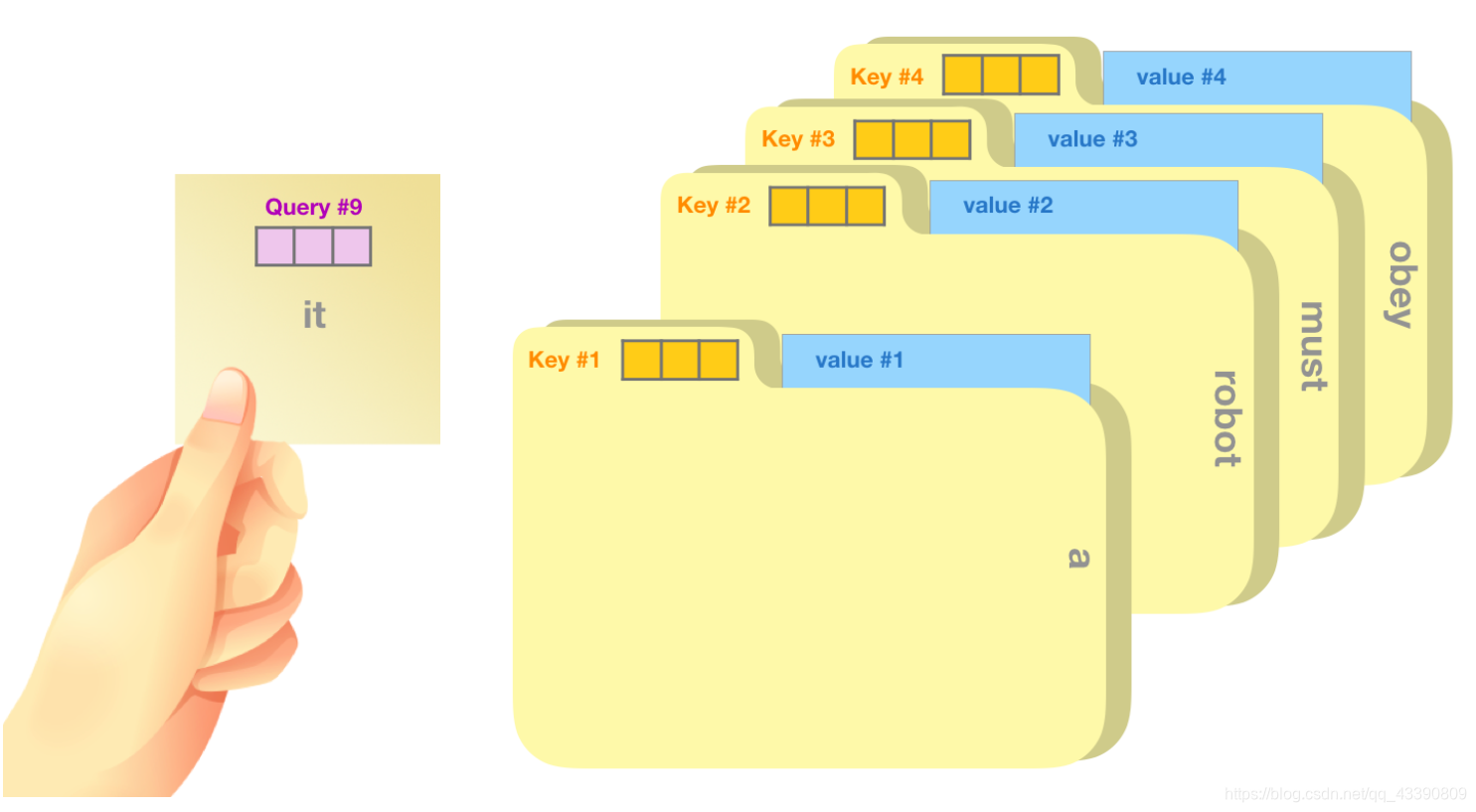
一个简单粗暴的比喻是在档案柜中找文件。查询向量就像一张便利贴,上面写着你正在研究的课题。键向量像是档案柜中文件夹上贴的标签。当你找到和便利贴上所写相匹配的文件夹时,拿出它,文件夹里的东西便是值向量。只不过最后找的并不是单一的值向量,而是很多文件夹值向量的混合。
将单词的查询向量分别乘以每个文件夹的键向量,得到各个文件夹对应的注意力得分(这里的乘指的是向量点乘,乘积会通过 softmax 函数处理)。
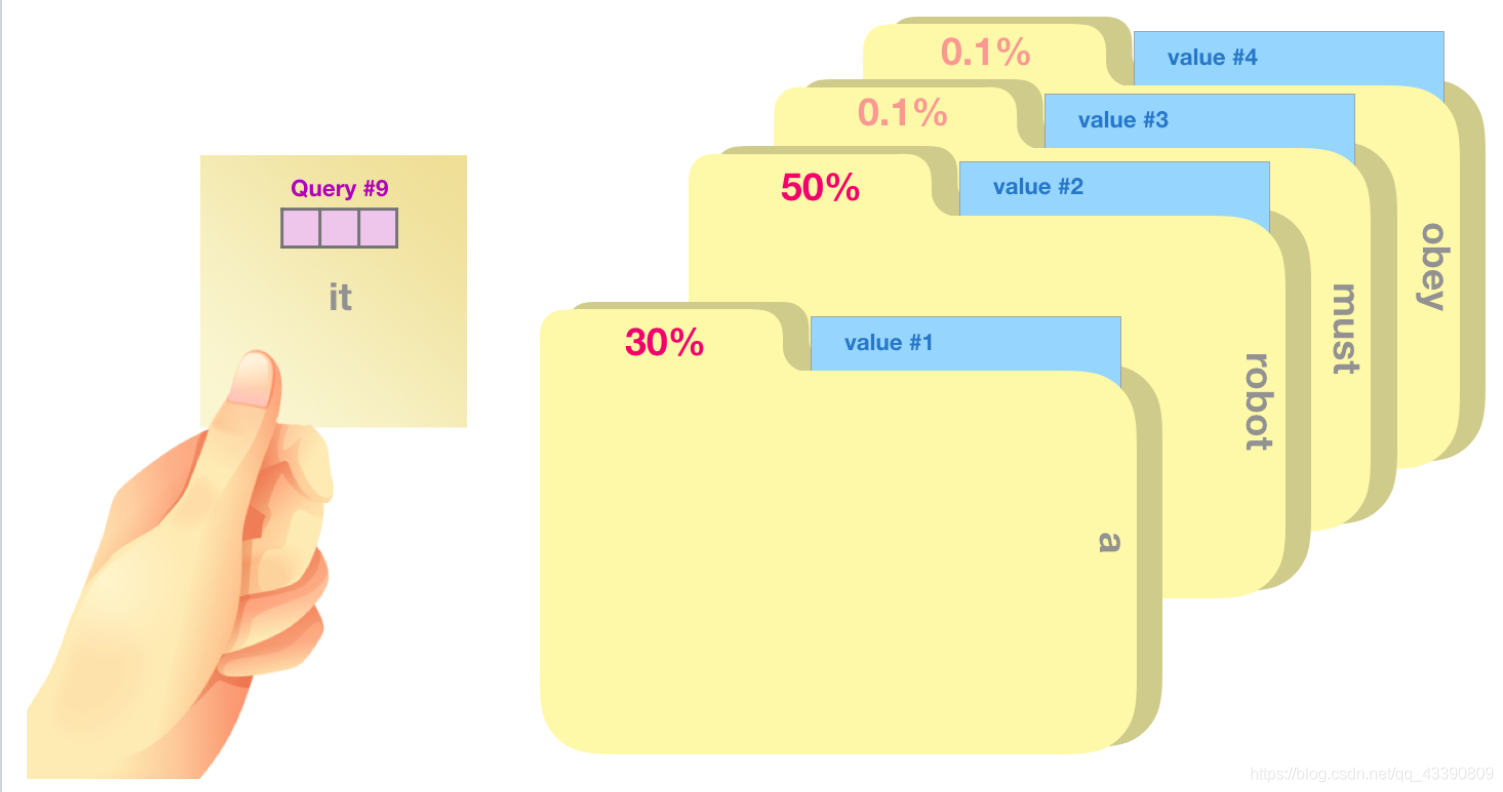
将每个文件夹的值向量乘以其对应的注意力得分,然后求和,得到最终自注意力层的输出。
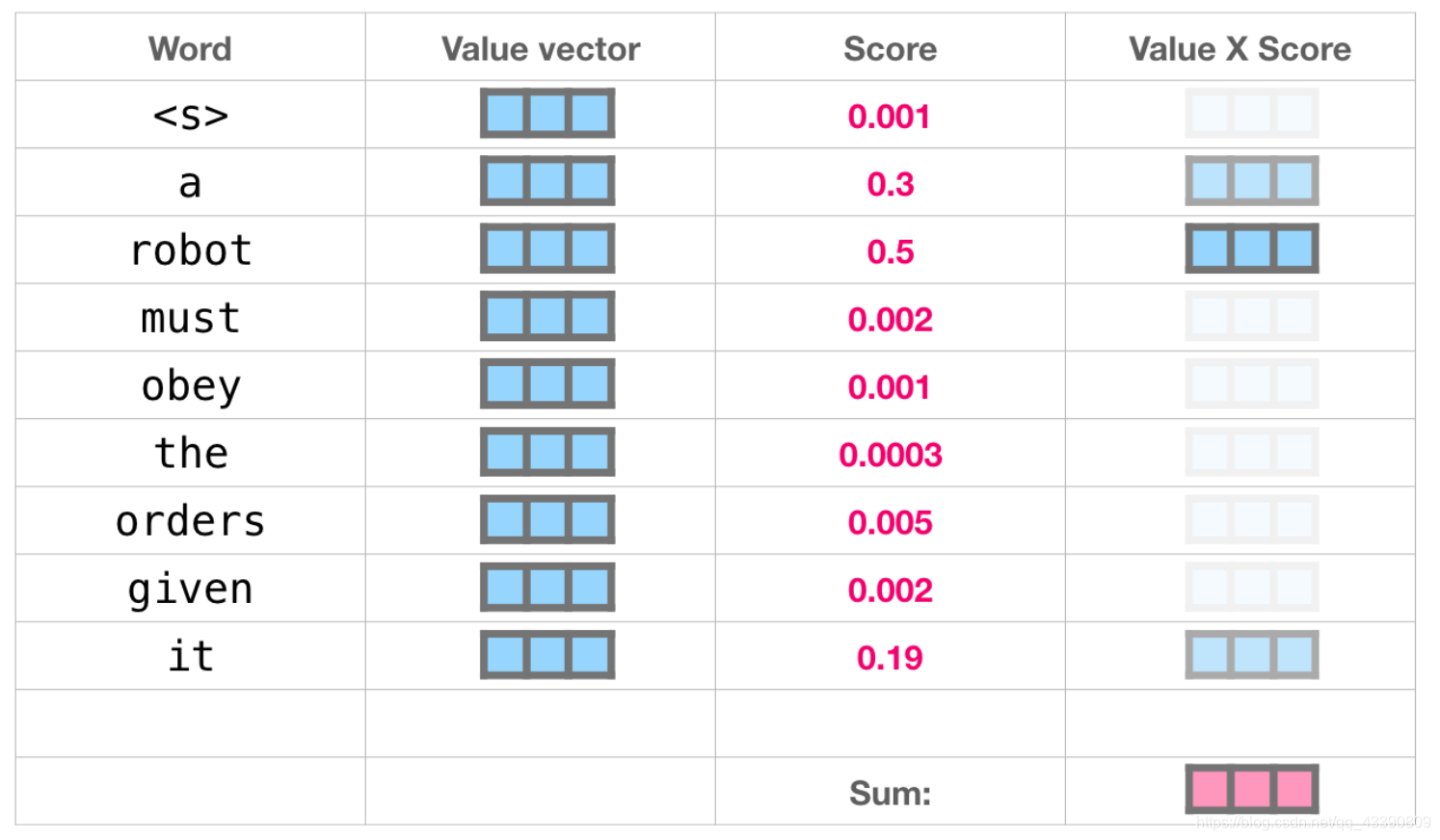
这样将值向量加权混合得到的结果是一个向量,它将其 50% 的「注意力」放在了单词「robot」上,30% 的注意力放在了「a」上,还有 19% 的注意力放在「it」上。
4.模型输出
当最后一个 transformer 模块产生输出之后(即经过了它自注意力层和神经网络层的处理),模型会将输出的向量乘上嵌入矩阵。
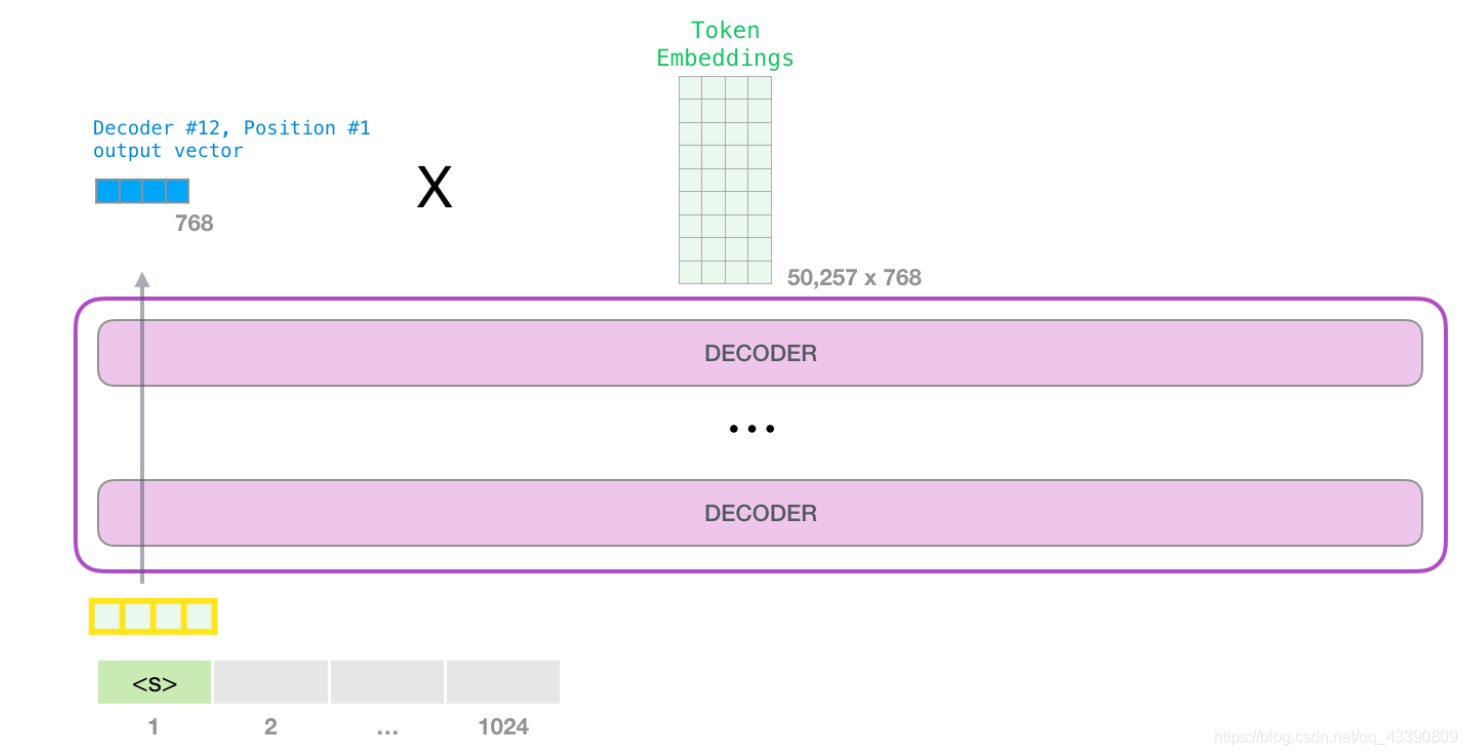
嵌入矩阵的每一行都对应模型的词汇表中一个单词的嵌入向量。所以这个乘法操作得到的结果就是词汇表中每个单词对应的注意力得分。

简单地选取得分最高的单词作为输出结果(即 top-k = 1)。但其实如果模型考虑其他候选单词的话,效果通常会更好。所以,一个更好的策略是对于词汇表中得分较高的一部分单词,将它们的得分作为概率从整个单词列表中进行抽样(得分越高的单词越容易被选中)。通常一个折中的方法是,将 top-k 设为 40,这样模型会考虑注意力得分排名前 40 位的单词。
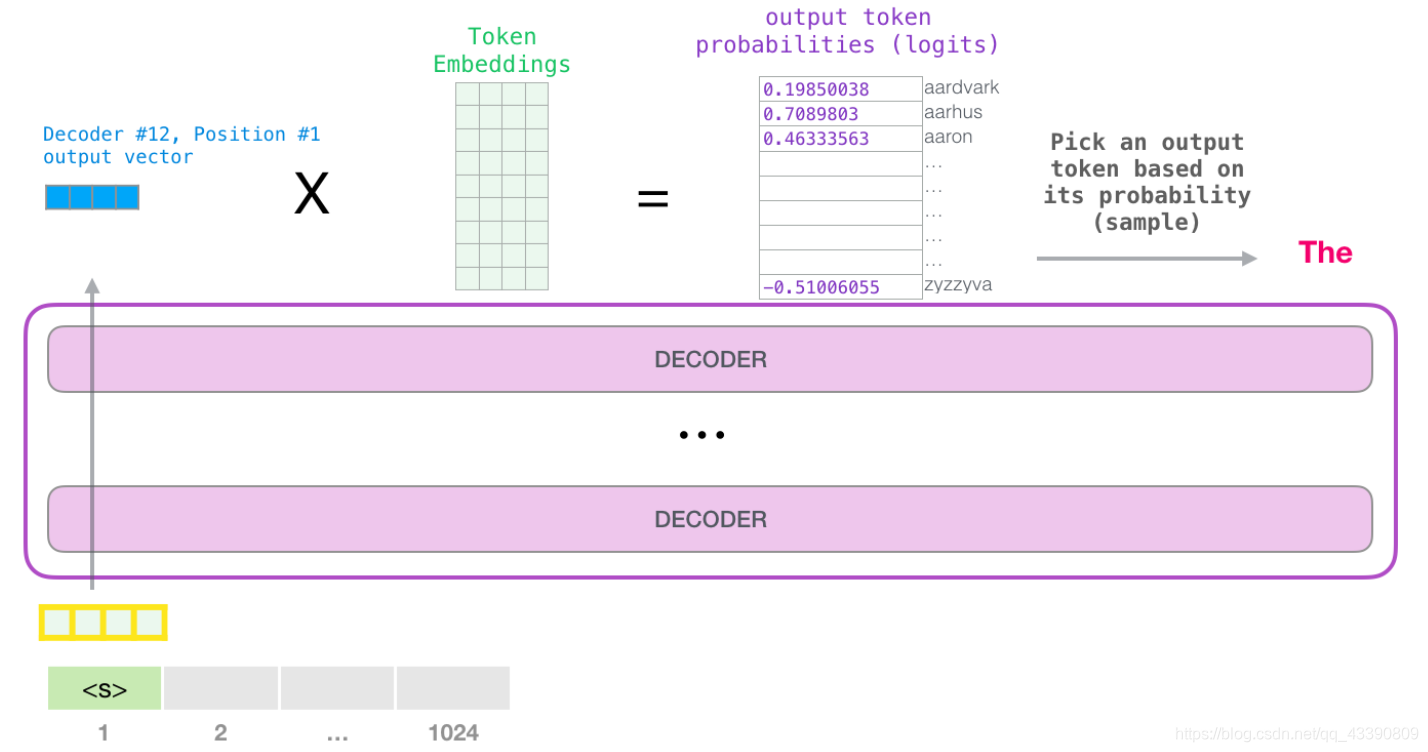
这样,模型就完成了一轮迭代,输出了一个单词。模型会接着不断迭代,直到生成一个完整的序列------序列达到 1024 的长度上限或序列中产生了一个终止符。
GPT-3
GPT-3依旧延续自己的单向语言模型训练方式,只不过这次把模型尺寸增大到了1750亿,并且使用45TB数据进行训练。同时,GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。
对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛华能力下降,更加无法应用到其他领域。
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。