
DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval
htps://github.com/pl8787/textnet-release.
Motivation
人类判断文本匹配过程:
- 检测相关位置
- 确定局部相关性
- 聚集本地相关性以输出相关性标签
DeepRank模拟上述人类判断过程。
问题定义
查询: q q q = ( w 1 w_1 w1, . . . , w M w_M wM)
文档: d d d = ( v 1 v_1 v1, . . . , v N v_N vN)
文档中的上下文: d d d( k k k) [ _[ [ p _p p ] _] ]=( v v v p _p p − - − k _k k,…, v v v p _p p,…, v v v p _p p + + + k _k k),以第一个单词为中心,序列长度为2k + 1。
词嵌入:Word2Vec
DeepRank
三部分:Detection Strategy + Measure Network + Aggregation Network

Detection Strategy
相关性位置通常在查询词出现在文档中的位置上。将 query-centric 上下文定义为相关位置,这是一个在中心位置带有查询terms的上下文。
给定一个查询 q q q 和文档 d d d , 如果 w u w_u wu= v p v_p vp , 以该查询术语 w u w_u wu 为中心的上下文表示为 s s s p ^p p u _u u( k k k) = d d d( k k k) [ _[ [ p _p p ] _] ]。在Detection步骤之后,可以获得一组单词序列 s s s p ^p p u _u u( k k k),每个单词序列代表一个本地相关位置。
Measure Network
如图2所示。首先构造一个张量作为输入。在张量上应用CNN或2D-GRU来输出向量,该向量代表局部相关性的表示。这样,在Measure步骤中可以很好地捕获重要的IR特征,例如exact/semantic匹配信号、 passage retrieval intrinsics和 proximity heuristics。

Input Tensor
给定一个查询q,和对应文档的上下文( w u w_u wu= v p v_p vp ): s s s p ^p p u _u u( k k k)
首先构建word-level交互矩阵S(相似度函数):
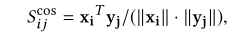
为了进一步将query/query-centric 的上下文的单词表示结合到input中,将 S S S i _i i j _j j的每个元素扩展到三维向量。因此,原始矩阵 S S S i _i i j _j j将变成三阶张量,表示为:

这样,输入张量可以被视为三个矩阵的连接:query matrix, query-centric context matrix, and
word-level interaction matrix.
CNN处理
一层CNN + max pooling
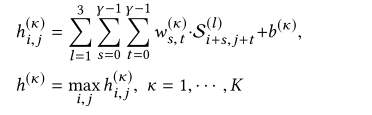
输出(K是kernel的数量)表示局部相关性:
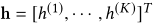
2D-GRU处理(接受3个方向隐藏状态)
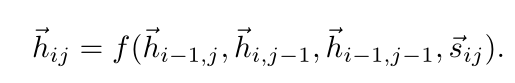
4个update gates 3个reset gates


Aggregation Network
对于CNN或者2D-RNN的输出 h h h , Aggregation Network 考虑原则:
- 查询词的重要性
查询词对于表达用户的信息需求至关重要,有些词比其他词更重要。
- 不同的匹配要求
匹配模式的分布在相关文档中可能有很大不同。
方法:首先进行了一个查询词级聚合,其中考虑了不同的匹配要求。当产生全局相关性分数时,应用术语gate网络来捕获不同术语的重要性。
Qery Term Level Aggregation
将位置指示符附加到每个向量 h h h,以编码相应的以查询为中心的上下文的位置信息。Aggregation Network中使用了不同的位置函数 g g g( p p p ):
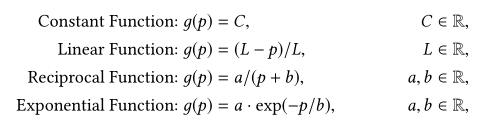
其中 p p p代表以查询为中心的上下文的位置,由查询对应文档的中心单词 v p v_p vp决定。在这个附加操作之后,以单词 v p v_p vp为中心的以查询词的上下文的局部相关性表示变成
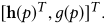
为了进行查询词级聚合,首先将具有相同中心词的 h h h( p p p)分组在一起,这代表关于相同查询词的所有局部相关。然后 RNN用于通过考虑位置信息来整合这种本地相关性。也就是说可以获得每个查询词 w u w_u wu的global相关性

其中 P P P( w u w_u wu)表示以查询术语为中心的所有以查询为中心的上下文的位置集。
Term Gating Network for Global Aggregation.
基于查询词级的全局相关性表示,通过考虑不同查询词的重要性,本文使用一个term gating network(类似于DRMM使用的网络)来获得最终的全局相关性得分。为每个查询词定义了一个权重参数 E E E w w w u _u u,并将所有查询词的级别相关度线性组合如下:
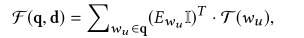
I I I为值全为1的向量,和 E E E w w w u _u u维度相同。
Model Training
Adam+L2+early stopping strategy
pairwise hinge loss:

实验
data Sets
LETOR4.0 and 搜狗查询日志
结果


