
Knowledge Guided Text Retrieval and Reading for Open Domain Question Answering
介绍
在基于文本的open-domain QA中,如何在不牺牲覆盖面的情况下最好地利用知识库(KB)仍然是一个悬而未决的问题。之前的工作已经将知识库事实转化为句子,以提供额外的证据在本文中,但是不显式地使用知识库图结构。作者展示了这种结构对于在基于开放域文本的问答中检索文本段落和融合它们之间的信息是非常有益的。
作者介绍了一种基于文本的开放领域问答的通用方法,它是知识指导的:它检索和读取一个段落graph,其中顶点是文本的passages,边表示从外部知识库或同一篇文章中的共现中导出的关系。本文的目标是将文本语料库的高覆盖率与知识库中的结构信息相结合,以提高结果模型的检索覆盖率和准确性。与检索和读取一组passages的标准方法不同,该方法在每个阶段都集成了图形结构,以构建、检索和读取passages graph。
该方法首先通过基于知识库的graph结构和文本语料库中的共现扩展一组种子段落来检索段落图(下图1)。然后引入了一个reader模型,该模型扩展了BERT ,并传播来自相关段落及其关系的信息,实现了知识丰富的跨段落表示。

方法

左边为graph-retriever,右边为graph-reader,首先,graph-retriever通过实体链接或TF-IDF获得种子passages,并基于Wikidata和Wikipedia扩展该graph,从而构建图。然后,reader-retriever将该图作为输入,获得初始段落表示,并使用 M M M个融合层相对于该图更新它们。
问题定义
目标是基于一个文本语料库(Wikipedia) C C C来回答问题,该语料库由大量文章组成,每篇文章可以分为多个passages。另外还假设存在一个外部知识库(Wikidata) K K K = {( e 1 e_1 e1, r r r, e 2 e_2 e2)},其中 e 1 e_1 e1, e 2 e_2 e2是实体, r r r是一个关系,并且在文本语料库的文章和知识库的实体之间存在1-1映射。
graph-retriever
graph-retriever以一个question作为输入,使用知识库 K K K在 C C C中构造一个passage图。它获得Seed passages,并通过 M M M r _r r e _e e t _t t迭代扩展该passage图,直到它达到最大passages数: n n n。将 P P P ( ^( ( m ^m m ) ^) )表示为在第 m m m次迭代中获得的passage,并描述如何获得 P P P ( ^( ( 0 ^0 0 ) ^) )(Seed passages)并在第 m m m次迭代中更新该图( 1 1 1 ≤ m m m ≤ M M M r _r r e _e e t _t t)。
Seed passages.
graph-retriever首先从一组Wikipedia文章开始,选择一个:
(1)与输入question中的实体进行实体链接的文章;
(2)基于TF-IDF的检索系统返回的前 K K K个文章。
选择这些文章的第一段作为种子段 P P P ( ^( ( 0 ^0 0 ) ^) )。
Graph expansion.
(1) 首先,根据Wikidata中存在的关系,通过添加与 P P P ( ^( ( m ^m m − ^- − 1 ^1 1 ) ^) )相关的段落来更新段落图:如果 p i p_i pi ∈ ∈ ∈ P P P ( ^( ( m ^m m − ^- − 1 ^1 1 ) ^) )和 p j p_j pj是Wikipedia文章中对应于知识库实体 e e e p _p p i _i i和 e e e p _p p j _j j的第一个段落,则( e e e p _p p i _i i, r r r i _i i , _, , j _j j, e e e p _p p j _j j) ∈ ∈ ∈ K K K,则 p j p_j pj被添加到passage图中关系为 r r r i _i i , _, , j _j j。
注:虽然这可能包括一些与问题不密切相关的实体,但它仍然增加了与答案相关的实体的覆盖范围。
(2) 第二, P P P ( ^( ( m ^m m − ^- − 1 ^1 1 ) ^) )的支撑passage被添加到passage图中。具体来说,维基百科文章中与 P P P ( ^( ( m ^m m − ^- − 1 ^1 1 ) ^) )相关联的非第一段由BM25排名,并选择top K passages。如果passages属于同一个维基百科文章, 则可以构建它们之间的关系: r r r i _i i , _, , j _j j是 c c c h h h i i i l l l d d d和 r r r j _j j , _, , i _i i是 p p p a a a r r r e e e n n n t t t。
Final graph.
最后,检索由 n n n个passage组成的passage图:{ p 1 p_1 p1,…, p n p_n pn}。段落之间的关系用{ r r r i _i i , _, , j _j j ∣ | ∣ 1 1 1 ≤ i i i, j j j ≤ n n n}表示,其中 r r r i _i i , _, , j _j j要么是KB关系, c c c h h h i i i l l l d d d, p p p a a a r r r e e e n n n t t t或者 n n n o o o − - − r r r e e e l l l a a a t t t i i i o o o n n n。
graph-reader
graph-reader一个问题 q q q和 n n n个检索到的passages建模: p 1 p_1 p1, p 2 p_2 p2,…, p n p_n pn(以及它们的关系 r r r i _i i , _, , j _j j ),目的是在检索到的段落之一中以文本跨度的形式输出问题的答案。该方法不是独立处理每一篇文章,而是通过融合图结构中链接段落的信息来获得知识丰富的段落表示。
Initial Passage Representation
在形式上,给定问题 q q q和一个passage p i p_i pi,graph-reader首先获得一个问题感知的段落表示:
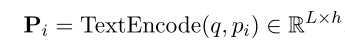
其中, L L L是每个passage的最大长度, h h h是隐藏维度。encoder选择为BERT。
此外,graph-reader通过关系encoder对关系 r r r i _i i , _, , j _j j进行编码:
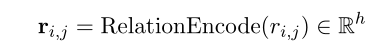
本文考虑最常见的98个关系,将其他关系归为未知关系,总计为100个(包括 n n n o o o − - − r r r e e e l l l a a a t t t i i i o o o n n n关系)。通过直接学习一个嵌入矩阵来获得每个关系的向量表示,这在实践中很有效。
Fusing Passage Representations
如图2右侧所示,graph-reader构建了 M M M个graph-aware融合层,通过在graph的边传播信息来更新passage表示。具体来说,graph-reader用 z z z ( ^( ( 0 ^0 0 ) ^) ) i _i i = MaxPool( P i P_i Pi)初始化段落表示。然后,基于其先前的表示、所有相邻通道及其关系,为每个融合层1 ≤ m ≤ M获得新的通道表示 z z z ( ^( ( m ^m m ) ^) ) i _i i。主要受(GCN)的启发,有两种可以考虑的迭代更新方法。
- Binary:考虑binary 关系(passage对是否相关):
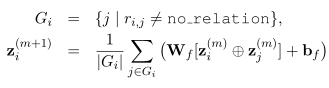
- relationship-aware:
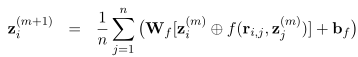
f f f是一个简单的concatention操作。
Answering Question
graph-reader使用更新的passage表示 z z z ( ^( ( m ^m m ) ^) ) 1 _1 1,…, z z z ( ^( ( m ^m m ) ^) ) n _n n来计算 p i p_i pi成为证据passage的概率。表示 Z Z Z = = = [ z z z ( ^( ( m ^m m ) ^) ) 1 _1 1,…, z z z ( ^( ( m ^m m ) ^) ) n _n n ] ∈ ∈ ∈ R R R h ^h h × ^× × n ^n n,定义:
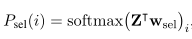
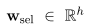
然后选择目标passage : i i i ∗ * ∗=
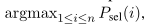
接下来计算答案跨度(位置: j j j和 k k k):
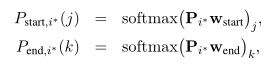
目标函数:
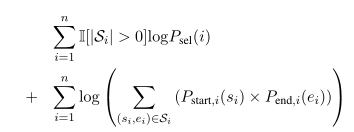
其中 S i S_i Si是一组跨度,对应于 p i p_i pi中的答案文本。
实验
数据集:NQ+TRIVER+WQ
Baselines:检索(text-match方法):BM25/TF-IDF
Reader:改变计算方式:
parreader:(不适用迭代图更新passage表示,并且单独计算passage表示)
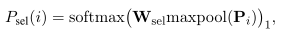
parreader++:(不适用迭代图更新passage表示,联合计算passage表示)
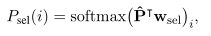
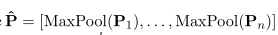
本文:(通过m轮迭代图更新passage表示,联合建模迭代后passage表示)
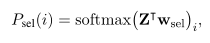
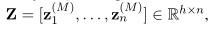
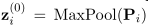
结果

消融实验
不同检索方法的影响(graph胜)

在gaph-reader中不同关系类型的影响
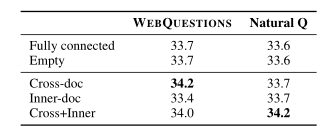
cross-doc:仅仅包括维基百科关系的passage(胜)
inner-doc:仅仅包括child和parent关系
cross+inner:都包括(胜)
将有关系的passage连接对实验的影响:(连接passage效果不好:败)
