一. 什么是语法糖
我们都知道语法糖是指在编程语言中添加某种语法,这种语法对语言的功能没有影响,但更方便程序员使用。比如Java中的for each循环,我们在写代码时可以这么写,使得代码更简洁。但编译为class文件后,for each就变成了普通的循环语句(使用goto、if等字节码实现)。
我想分享的是通过反编译、查看字节码了解Java中的一些常见语法糖是如何实现的。
二. 如何分析语法糖的实现原理
那么我们如何分析语法糖背后的实现原理呢?前面提到,Java代码文件被编译为class文件后,语法糖就变成了普通的基础语法(这个过程叫做解糖)。那么我们通过分析class文件就能了解解糖之后的基础语法就能知道Java是如何支持这些语法糖的。
分析class文件
class文件是二进制文件,要想直接看懂它需要十分熟悉它的组织结构。所以一般使用反编译工具将class文件反编译为可阅读的形式后再进行研究。
JDK中提供了javap命令,可以将class文件翻译为相对容易阅读的字节码形式。使用这种方式分析class文件可以得到最全面的信息,但也需要了解很多字节码相关的知识才能阅读。
除了javap命令还有很多第三方的工具可以直接将class文件反编译为Java代码。这种方式得到的结果可读性就很强了。IDEA中就集成了这样的反编译工具,直接用IDEA打开class文件就能看到反编译后的结果。
- javap命令
- IDEA
下面我们就用上述两种方式来分析一下Java中的一些语法糖。
三. Java中的语法糖
3.1 for each循环
(1)for each遍历数组
Java代码
int[] arr = {
1,2,3,4};
for(int i : arr) {
System.out.println(i);
}
反编译之后
int[] var1 = new int[]{
1, 2, 3, 4};
int var2 = 0;
int[] var3 = var1;
int var4 = var1.length;
for(int var5 = 0; var5 < var4; ++var5) {
int var6 = var3[var5];
var2 += var6;
}
我们可以看到,反编译之后for each循环变成了一个普通的for循环。可以理解为for each遍历数组是通过更为基础的for循环实现的。
3.2 装箱和拆箱
以Integer和int的相互转换为例
Java代码:
int num1 = 1000;
Integer num2 = num1;
int num3 = num2;
反编译之后:
short var1 = 1000;
Integer var2 = Integer.valueOf(var1);
int var3 = var2;
从反编译后的结果可以看到装箱的过程,即Integer.valueOf方法的使用。但看不出Integer到int的转换实现原理。
为了验证我们的结论,我们需要使用javap命令来看一下更底层的字节码。
javap -v BoxingAndUnboxing
Classfile /C:/Users/xiaozhigang/Desktop/Java语法糖/BoxingAndUnboxing.class
Last modified 2019-11-14; size 400 bytes
MD5 checksum 769b615cb1893668acb2c7660c6a233c
Compiled from "BoxingAndUnboxing.java"
public class BoxingAndUnboxing
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #5.#14 // java/lang/Object."<init>":()V
#2 = Methodref #15.#16 // java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
#3 = Methodref #15.#17 // java/lang/Integer.intValue:()I
#4 = Class #18 // BoxingAndUnboxing
#5 = Class #19 // java/lang/Object
#6 = Utf8 <init>
#7 = Utf8 ()V
#8 = Utf8 Code
#9 = Utf8 LineNumberTable
#10 = Utf8 main
#11 = Utf8 ([Ljava/lang/String;)V
#12 = Utf8 SourceFile
#13 = Utf8 BoxingAndUnboxing.java
#14 = NameAndType #6:#7 // "<init>":()V
#15 = Class #20 // java/lang/Integer
#16 = NameAndType #21:#22 // valueOf:(I)Ljava/lang/Integer;
#17 = NameAndType #23:#24 // intValue:()I
#18 = Utf8 BoxingAndUnboxing
#19 = Utf8 java/lang/Object
#20 = Utf8 java/lang/Integer
#21 = Utf8 valueOf
#22 = Utf8 (I)Ljava/lang/Integer;
#23 = Utf8 intValue
#24 = Utf8 ()I
{
public BoxingAndUnboxing();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=4, args_size=1
0: sipush 1000
3: istore_1
4: iload_1
5: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
8: astore_2
9: aload_2
10: invokevirtual #3 // Method java/lang/Integer.intValue:()I
13: istore_3
14: return
LineNumberTable:
line 3: 0
line 4: 4
line 6: 9
line 7: 14
}
SourceFile: "BoxingAndUnboxing.java"
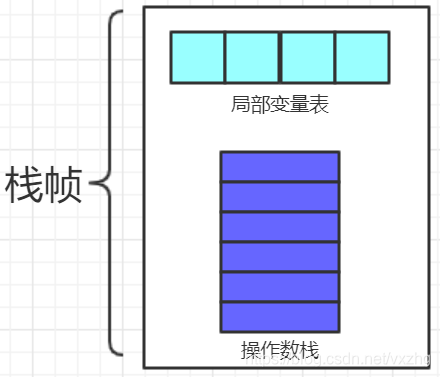
下面我们分析一下上面的字节码的执行过程。首先回忆一下Java的运行时数据区域的栈。如下图所示,对于每一个方法执行时都会被分配一个栈帧,一个栈帧包括操作数栈和局部变量表两部分。上述字节码中的main方法部分大部分代码都是对这两个结构的操作。
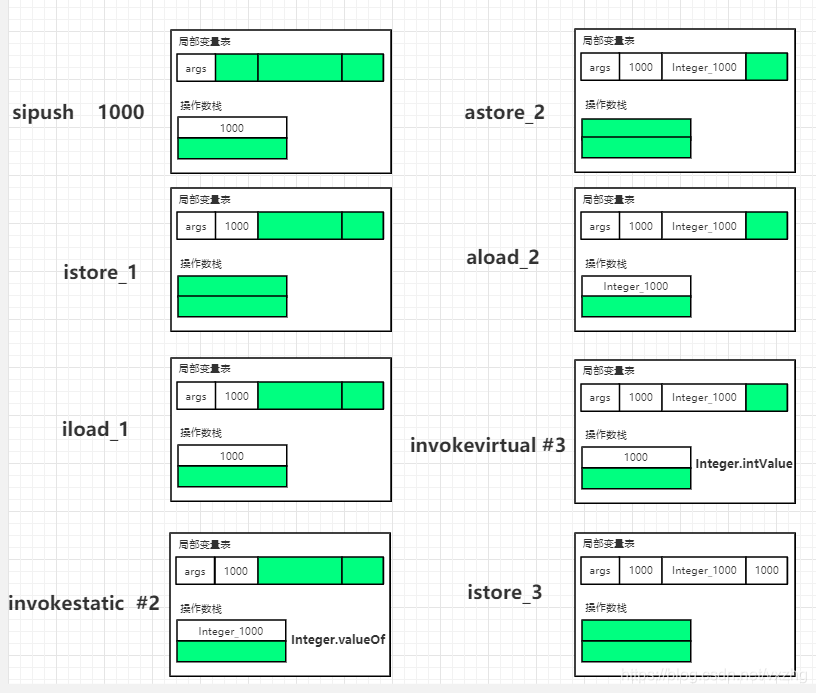
从字节码中我们可以看到装箱的操作,是通过Integer的valueOf方法实现的。
3.3 switch语句支持String类型
(1)switch语句支持String类型
Java代码:
String str = "hello";
switch(str) {
case "world":
System.out.println("world");
break;
case "hello":
System.out.println("hello");
break;
default:
break;
}
反编译后:
String var1 = "hello";
byte var3 = -1;
switch(var1.hashCode()) {
case 99162322:
if (var1.equals("hello")) {
var3 = 1;
}
break;
case 113318802:
if (var1.equals("world")) {
var3 = 0;
}
}
switch(var3) {
case 0:
System.out.println("world");
break;
case 1:
System.out.println("hello");
}
可以看到,Java是通过字符串的hashCode()和equals()方法来实现switch对String的支持的。我们知道switch是支持int类型的,而hashCode方法的返回值就是一个int类型。通过hashCode进行查找后,再使用equals方法进行判断来避免hash冲突。
(2)从字节码简单分析switch的实现原理
例子1:
public int tableSwitchTest(int num) {
switch(num) {
case 100: return 0;
case 101: return 1;
case 104: return 4;
default: return -1;
}
}
使用javap -c命令分析其字节码:
public int tableSwitchTest(int);
Code:
0: iload_1
1: tableswitch {
// 100 to 104
100: 36
101: 38
102: 42
103: 42
104: 40
default: 42
}
36: iconst_0
37: ireturn
38: iconst_1
39: ireturn
40: iconst_4
41: ireturn
42: iconst_m1
43: ireturn
很明显,字节码中的tableswitch实现了Java语法中的switch语句。100:36,表示操作数为100时跳到36那行去执行。就是iconst_0, ireturn这里,即返回了0。以此类推。但我们对比Java代码,会发现一个问题:在字节码中多出了102、103。这是因为编译器会对 case 的值做分析,如果 case 的值比较紧凑,中间有少量断层或者没有断层,会采用 tableswitch 来实现 switch-case,有断层的会生成一些虚假的 case 帮忙补齐连续,这样可以实现 O(1) 时间复杂度的查找:因为 case 已经被补齐为连续的,通过游标就可以一次找到。
例子2:
public int lookupSwitchTest(int num) {
switch(num) {
case 1: return 1;
case 100: return 100;
case 10: return 10;
default: return -1;
}
}
使用javap -c命令分析其字节码:
public int lookupSwitchTest(int);
Code:
0: iload_1
1: lookupswitch {
// 3
1: 36
10: 41
100: 38
default: 44
}
36: iconst_1
37: ireturn
38: bipush 100
40: ireturn
41: bipush 10
43: ireturn
44: iconst_m1
45: ireturn
而这个例子中的switch的实现使用了lookupswitch,这是因为这个例子中的case值分布的比较稀疏,如果采用上述补齐case的方式显然不合理。lookupswitch的键是经过排序,在查找时可以通过二分查找的方式实现,时间复杂度是O(logN)。
所以结论是:switch-case 语句 在 case 比较稀疏的情况下,编译器会使用 lookupswitch 指令来实现,否则,编译器会使用 tableswitch 来实现。
3.4 泛型
Java代码
HashMap<String, String> map = new HashMap<String, String>();
map.put("name", "xiaoming");
String name = map.get("name");
System.out.println(name);
反编译后
HashMap var1 = new HashMap();
var1.put("name", "xiaoming");
String var2 = (String)var1.get("name");
System.out.println(var2);
在反编译之后,泛型HashMap<String,String>不见了,只有普通类型HashMap。在进行get操作时,进行了强制类型转换,将Object类型转换为我们需要的String类型。
3.5 方法不定长参数
Java代码
public static void main(String[] args) {
print("hello","world");
}
public static void print(String...args) {
for(int i = 0; i < args.length; i++) {
System.out.println(args[i]);
}
}
反编译后:
public static void main(String[] var0) {
print("hello", "world");
}
public static void print(String... var0) {
for(int var1 = 0; var1 < var0.length; ++var1) {
System.out.println(var0[var1]);
}
}