1.文件
1.1 增:写入文件内容给文本文件
def writeTextFile(filePath, fileContent, encoding='utf8'):
with open(filePath, 'w', encoding=encoding) as file:
file.write(fileContent)
1.2 改:批量修改图片大小
import os
from PIL import Image
def getFilePathList(dirPath, partOfFileName=''):
allFileName_list = list(os.walk(dirPath))[0][2]
fileName_list = [k for k in allFileName_list if partOfFileName in k]
filePath_list = [os.path.join(dirPath, k) for k in fileName_list]
return filePath_list
def batchResizeImage(oldDirPath, newDirPath, height, width):
if not os.path.isdir(newDirPath):
os.mkdir(newDirPath)
jpgFilePath_list = getFilePathList(oldDirPath, '.jpg')
for jpgFilePath in jpgFilePath_list:
image = Image.open(jpgFilePath)
resized_image = image.resize((height, weight), Image.ANTIALIAS)
jpgFileName = os.path.split(jpgFilePath)[1]
saveFilePath = os.path.join(newDirPath, jpgFileName)
resized_image.save(saveFilePath)
oldDirPath = 'source_images'
newDirPath = 'train_images'
height = 640
width = 640
batchResizeImage(oldDirPath, newDirPath, height, width)
1.3 查:查询文件夹中的文件
import os
def getFileNameList(dirPath, partOfFileName=''):
allFileName_list = list(os.walk(dirPath))[0][2]
fileName_list = [k for k in allFileName_list if partOfFileName in k]
return fileName_list
def getFilePathList(dirPath, partOfFileName=''):
allFileName_list = list(os.walk(dirPath))[0][2]
fileName_list = [k for k in allFileName_list if partOfFileName in k]
filePath_list = [os.path.join(dirPath, k) for k in fileName_list]
return filePath_list
查:读取文件
def readTextFile(filePath, encoding='utf8'):
with open(filePath, encoding=encoding) as file:
return file.read()
查:搜索文件夹路径内含有指定内容的代码文件
import os
# 传入3个参数:文件夹路径dirPath、指定内容partOfFileContent、代码文件后缀名suffixOfFileName
def searchFileContent(dirPath, partOfFileContent, suffixOfFileName=''):
dirPath = os.path.expanduser(dirPath)
walk_list = list(os.walk(dirPath))
result_list = []
for walk in walk_list:
filePath_list = [os.path.join(walk[0], k) for k in walk[2] \
if k.rsplit('.', maxsplit=1)[1]==suffixOfFileName.strip('.')]
for filePath in filePath_list:
with open(filePath, encoding='=utf8') as file:
fileContent = file.read()
if partOfFileContent in fileContent:W
print(filePath)
result_list.append(filePath)
return result_list
2.xml
2.1 labelimg_yolo_txt转pascal voc_xml
from PIL import Image
import os
#读取文件尺寸
def ImgSize(image):
img = Image.open(image)
w,h = img.width,img.height
return w,h
#labelimg中yolo转voc图位转换
#width,height就是原图的w,h #xmin指中心点占横比例,xmax指中心点占竖比例 #ymin指bbox占整图宽比例,ymax指bbox占整图高比例
def ScaleCovertor(width,height,xmin,xmax,ymin,ymax):
center_x = round(float(xmin* width))
center_y = round(float(xmax * height))
bbox_width = round(float(ymin * width))
bbox_height = round(float(ymax * height))
xmin = str(int(center_x - bbox_width / 2 ))
ymin = str(int(center_y - bbox_height / 2))
xmax = str(int(center_x + bbox_width / 2))
ymax = str(int(center_y + bbox_height / 2))
return xmin,ymin,xmax,ymax
def Main(filepath): #filepath是txt文件夹路径(里面全是需要转换的txt文件)
#设置xml内部格式
xml_head = '''
<annotation>
<folder>Desktop</folder>
<filename>{}</filename>
<path>unknonw</path>
<source>
<database>unknow</database>
</source>
<size>
<width>{}</width>
<height>{}</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
'''
xml_obj = '''
<object>
<name>{}</name>
<pose>no</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>{}</xmin>
<ymin>{}</ymin>
<xmax>{}</xmax>
<ymax>{}</ymax>
</bndbox>
</object>
'''
xml_end = '''
</annotation>'''
counter = 1 #计数器
for filename in os.listdir(filepath): #现在的filename是带后缀的
print ('Processing:->>',filename,'Number %s'%counter) #打印当前文件名 和 第几个文件
#原图:
content=[] #建立内容列表,class,中心点占比,bbox占比
with open(filepath+'/'+filename,'r') as readlines:
for linecontent in readlines.readlines(): #读取每一行内容
content.append(linecontent) #添加到列表中
w,h = ImgSize('C:/Users/lenovo/Desktop/yuantu'+'/'+filename.split('.')[0]+'.jpg') #调用文件尺寸读取函数
#xml:
obj = '' #这里创建xml,建立空字符串
head = xml_head.format(str(filename.split('.')[0]+'.jpg'),str(w),str(h)) #向xml head里添加文件名 文件w和h
for info in content: #读取每个文件里的内容
infodetail = info.split(' ') #以空格切割列表内的数据
#单独读取每个数据保存到变量里
Class,XMin,XMax,YMin,YMax = infodetail[0],infodetail[1],infodetail[2],infodetail[3],infodetail[4],
xmin,ymin,xmax,ymax = ScaleCovertor(w,h,float(XMin),float(XMax),float(YMin),float(YMax))
label= {
1:'obstacle',0:'people'} #确定label和类的映射关系,下行用到
obj += xml_obj.format(label[int(Class)],xmin,ymin,xmax,ymax) #向主object里循环添加 一个图里的物体或类
#写入xml文件
with open('C:/Users/lenovo/Desktop/annotation2/xml'+filename.split('.')[0]+'.xml','w') as xmw:
#创建写入 合并 三个 xml主体部分
xmw.write(head+obj+xml_end)
counter+=1
Main('C:/Users/lenovo/Desktop/annotation2/txt') #txt文件夹

#验证转的对错
import matplotlib.pyplot as plt
import matplotlib.image as Image #这个读取库比较方便 不用把数据转来转去,plt可以直接使用
%matplotlib inline
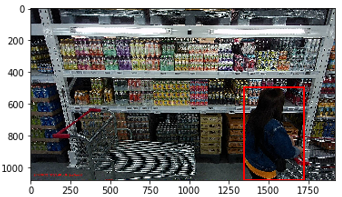
img = Image.imread('/Users/Desktop/annotation2/test/yuantu/'+'20190721062948_000394_cc8cdaa5ee38.jpg') #读取
x1,y1,x2,y2 = 1344, 495, 1722, 1080 # 自己找验证
plt.gca().add_patch (
plt.Rectangle(xy=(x1,y1),width=x2-x1,height=y2-y1,fill=False,edgecolor='red',linewidth=2)
)
plt.imshow(img)
plt.show() #根据环境添加
2.2 删除 w label
import re
import os
rawfolder='123' #存放三张xml的文件夹
newfolder='33333' #生成的新的xml文件夹
for i in os.listdir(rawfolder):
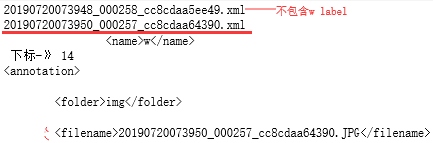
print (i) #输出#20190720073948_000258_cc8cdaa5ee49.xml
#20190720073950_000257_cc8cdaa64390.xml
#20190720073950_000258_cc8cdaa5ee3e.xml
with open(rawfolder+'/'+i,'r') as r:
content = r.readlines()
#print(content)
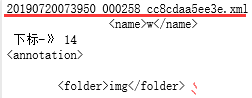
#输出['<annotation>\n', '\t<folder>img</folder>\n', '\t<filename>20190720073948_000258_cc8cdaa5ee49.JPG</filename>\n', ...]
c = 0
for j in content:
if '<name>w</name>' in j:
print (j,'下标-》',c) #c为14行<name>w</name>,从0行开始
start = 0
end = c-1 # c-1为上一行<object>
first_part = content[start:end]
second_part = content[end+12:] #整个一块为w的object
final = first_part+second_part
for x in final:
with open(newfolder+'/'+i,'a+') as w:
w.writelines(x)
print (x)
c+=1
# break
2.3 检查不是people和obstacle的label
# 检查不是people和obstacle的label
import re
import os
rawfolder='123'
#newfolder='33333'
for i in os.listdir(rawfolder):
# print (i)
with open(rawfolder+'/'+i,'r') as r:
content = r.readlines()
# print(content)
for j in content:
if '<name>' in j and ('people' not in j and 'obstacle'not in j):
print (j)
print (i)

2.4 读取指定后缀
import os
def get_filePathList(dirPath, partOfFileName=''):
all_fileName_list = next(os.walk(dirPath))[2] #['20190720072950_000256_cc8cdaa64390.JPG',
#'20190720073948_000258_cc8cdaa5ee49.JPG',
# '20190720073950_000257_cc8cdaa64390.JPG',
# '20190720074950_000259_cc8cdaa5ee3e .jpg',
#'20190720074950_000259_cc8cdaa5ee3e.JPG']
fileName_list = [k for k in all_fileName_list if partOfFileName in k] #去除除了'.JPG'文件,不含前面绝对路径
filePath_list = [os.path.join(dirPath, k) for k in fileName_list] #含全部路径,['',
# '']
#return fileName_list
return filePath_list
dirPath='C:/Users/lenovo/Desktop/lian'
a=get_filePathList(dirPath,'.JPG')
a
#print(len(a))

2.5 检查是否有图片漏标,并删除漏标图片
def delete_file(filePath):
if not os.path.exists(filePath): #filePath指C:/Users/lenovo/Desktop/lianxi/img\\20190720072950_000256_cc8cdaa64390.JPG'
print('%s 这个文件路径不存在,请检查一下' %filePath)
else:
print('%s 这个路径的文件需手动删除' %filePath)
def check_1(dirPath, suffix):
xmlFilePath_list = get_filePathList(dirPath, '.xml') # 与suffix不同,自己指定'.xml'
xmlFilePathPrefix_list = [k[:-4] for k in xmlFilePath_list] # 不带.xml
xmlFilePathPrefix_set = set(xmlFilePathPrefix_list)
#print(xmlFilePathPrefix_set) #{'绝对路径不带后缀',
# ' ' }
imageFilePath_list = get_filePathList(dirPath, suffix)
imageFilePathPrefix_list = [k[:-4] for k in imageFilePath_list] # 不带后缀
imageFilePathPrefix_set = set(imageFilePathPrefix_list)
#print(imageFilePathPrefix_set)
redundant_imgFilePathPrefix_list = list(imageFilePathPrefix_set - xmlFilePathPrefix_set)
redundant_imgFilePath_list = [k+'.JPG' for k in redundant_imgFilePathPrefix_list]
#上行带.JPG后缀, 如果自定义.0JPG,显示这个文件路径不存在,请检查一下
for imgFilePath in redundant_imgFilePath_list:
delete_file(imgFilePath)
dirPath='C:/Users/lenovo/Desktop/lx'
check_1(dirPath,'.JPG')
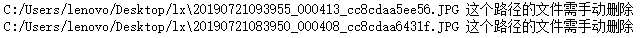
2.6 检测标记的box是否超过图片的边界,若有则显示删除与box相关的xml文件和图片文件
import xml.etree.ElementTree as ET
from PIL import Image
def check_2(dirPath, suffix):
xmlFilePath_list = get_filePathList(dirPath, '.xml')
#print(xmlFilePath_list) #['.xml全部路径',
# ' ']
allFileCorrect = True # 跳出for循环则执行 if allFileCorrect
for xmlFilePath in xmlFilePath_list:
imageFilePath = xmlFilePath[:-4] + '.' + suffix.strip('.')
#print(xmlFilePath)
#print(imageFilePath)
#C:/Users/lenovo/Desktop/lx\20190720072950_000256_cc8cdaa64390.xml
#C:/Users/lenovo/Desktop/lx\20190720072950_000256_cc8cdaa64390.JPG
#.....
image = Image.open(imageFilePath)
width, height = image.size
with open(xmlFilePath) as file:
fileContent = file.read()
#print(fileContent) #<annotation>...
root = ET.XML(fileContent) #根<annotation>...
object_list = root.findall('object') # <object>
for object_item in object_list:
bndbox = object_item.find('bndbox') #<bndbox>
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
if xmax>xmin and ymax>ymin and xmax<=width and ymax<=height:
continue
else:
delete_file(xmlFilePath)
delete_file(imageFilePath)
allFileCorrect = False
break
if allFileCorrect:
print('祝贺你! 已经通过检验,所有xml文件中的标注框都没有越界')
dirPath='C:/Users/lenovo/Desktop/lx' #lx文件夹里.xml和.JPG混在一起
check_2(dirPath,'.JPG')#''里必须.JPG或不填
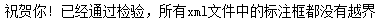
2.7 检查xmin<0…,并修改xmin…
#coding=utf-8
import os
import shutil
import random
from xml.etree.ElementTree import ElementTree,Element
import cv2
def read_xml(in_path):
'''
读取并解析xml文件
in_path: xml路径
return: ElementTree
'''
tree = ElementTree()
tree.parse(in_path)
return tree
def check():
url = "C:/Users/lenovo/Desktop/source/xml_sum" # xml_sum只存放xml的文件夹
for item in os.listdir(url): # item为.xml文件
tree = read_xml(url + "/" + item) # read_xml函数上面定义
root = tree.getroot()
object = root.findall("object")
size = root.find("size")
width =int(size.find("width").text)
height = int(size.find("height").text)
if object == None:
print(item)
continue
for it in object:
bndbox = it.find("bndbox")
if bndbox == None:
print(item)
xmin = int(bndbox.find("xmin").text)
xmax = int(bndbox.find("xmax").text)
ymin = int(bndbox.find("ymin").text)
ymax = int(bndbox.find("ymax").text)
if xmin <= 0 or xmin >= xmax or ymin <=0 or ymin >= ymax:
print(item)
if xmax > width or ymax> height:
print(item)
if __name__ =='__main__':
check() # 不输出则表示全对。输出123111.xml,没有列表引号
import xml.etree.ElementTree as ET
def generateNewXmlFile(old_xmlFilePath, new_xmlFilePath):
with open(old_xmlFilePath) as file:
fileContent = file.read()
root = ET.XML(fileContent)
object_list = root.findall('object')
for object_item in object_list:
bndbox = object_item.find('bndbox')
xmin = bndbox.find('xmin')
xminValue = int(xmin.text)
xmin.text = str(int(xminValue + 1))
ymin = bndbox.find('ymin')
yminValue = int(ymin.text)
ymin.text = str(int(yminValue + 1))
xmax = bndbox.find('xmax')
xmaxValue = int(xmax.text)
xmax.text = str(int(xmaxValue + 1))
ymax = bndbox.find('ymax')
ymaxValue = int(ymax.text)
ymax.text = str(int(ymaxValue + 1))
tree = ET.ElementTree(root)
tree.write(new_xmlFilePath)
old_dirPath ='C:/Users/lenovo/Desktop/999/8'
new_dirPath ='C:/Users/lenovo/Desktop/999/9'
def batch_modify_xml(old_dirPath, new_dirPath): #修改文件夹中的若干xml文件
#以下4行将new_dirPath和xmlFileName名称结合,内容是调用generateNewXmlFile函数改写
xmlFilePath_list = get_filePathList(old_dirPath, '.xml')
for xmlFilePath in xmlFilePath_list:
xmlFileName = os.path.split(xmlFilePath)[1] #1后
#print(xmlFileName) #输出 20190720073950_000257_cc8cdaa64390.xml
new_xmlFilePath = os.path.join(new_dirPath, xmlFileName)
generateNewXmlFile(xmlFilePath, new_xmlFilePath)
batch_modify_xml(old_dirPath, new_dirPath)
2.8 读取classname
def get_classNameList(txtFilePath):
with open(txtFilePath, 'r', encoding='utf8') as file:
fileContent = file.read()
line_list = [k.strip() for k in fileContent.split('\n') if k.strip()!='']
className_list= sorted(line_list, reverse=False)
return className_list
txtFilePath='C:/Users/lenovo/Desktop/labelImg/data/predefined_classes -outofstock.txt'
get_classNameList(txtFilePath)

import os
pathnoname,name=os.path.split("E:/lpthw/zedshaw/ex19.py")
print(pathnoname)
print(name)
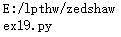
# 添加环境变量
import sys
sys.path.append('')
2.9 检查trainval.txt
import cv2
from os import listdir
from os.path import isfile,isdir,join
trainval_list = list()
with open('./trainval.txt','r') as f:
for line in f.readlines():
line = line.strip('\n')
a = line +'.jpg'
trainval_list.append(a)
print(trainval_list)

for i in trainval_list:
img_path = '{}{}'.format('./img3/',i)
img = cv2.imread(img_path)
try:
img.shape
print(img.shape) # 在img3文件夹中没有......11111.jpg图片
except:
print('fail read:' + img_path)
continue

B站/知乎/微信公众号:码农编程录
