参考书籍:《Python 3网络爬虫开发实战》
Scrapy 进阶:Selector、
Selector(选择器)
除了Beautiful Soap、pyquery、正则表达式等工具能提取网页数据,Scrapy 还提供了自己的数据提取方法,即 Selector(选择器)。 Selector 是基于lxml来构建的,支持XPath 选择器、CSS选择器以及正则表达式(均自带),功能全面,解析速度和准确度非常高。
直接使用
Selector 是一个可以独立使用的模块,我们可以直接利用 Selector 这个类来构建一个选择器对象(构建的时候传入text参数), 然后调用它的相关方法 xpath() ,css() (Selector的2个选择器,正则表达式不属于选择器)等来提取数据。
示例:
from scrapy import Selector
body= '<html><head><title>Hello World</title></head><body></body> </ html> ’
selector = Selector(text=body) # !!构建的时候传入text参数
title = selector.xpath('//title/text()').extract_first()
print(title)
# 输出:
Hello World
# 我们在这里没有在 Scrapy 框架中运行,而是把 Scrapy 中的 Selector 单独拿出来使用了
结合Scrapy
一种情况是,对Scrapy 的回调函数中的参数response 直接调用 xpath()或者 css()方法来提取数据。
response 有一个属性 selector ,我们调用 response.selector 返回的内容就相当于用 response 的 body 构造了 Selector 对象。通过这个 Selector 对象我们可以调用解析方法如 xpath()、 css ()等,通过向方法传入 XPath 或 CSS 选择器参数就可以实现信息的提取。
为了简洁,可以使用response .xpath()和 response. css(),它们二者的功能完全等同于 response.selector.xpath()和 response.selector.css()。
注意,如果结果的形式是 Selector 组成的列表,其实它是 Selectorlist 类型,但能调用的方法与Selector基本相同。
第一次解析获得的Selector 结果,可继续提取信息。
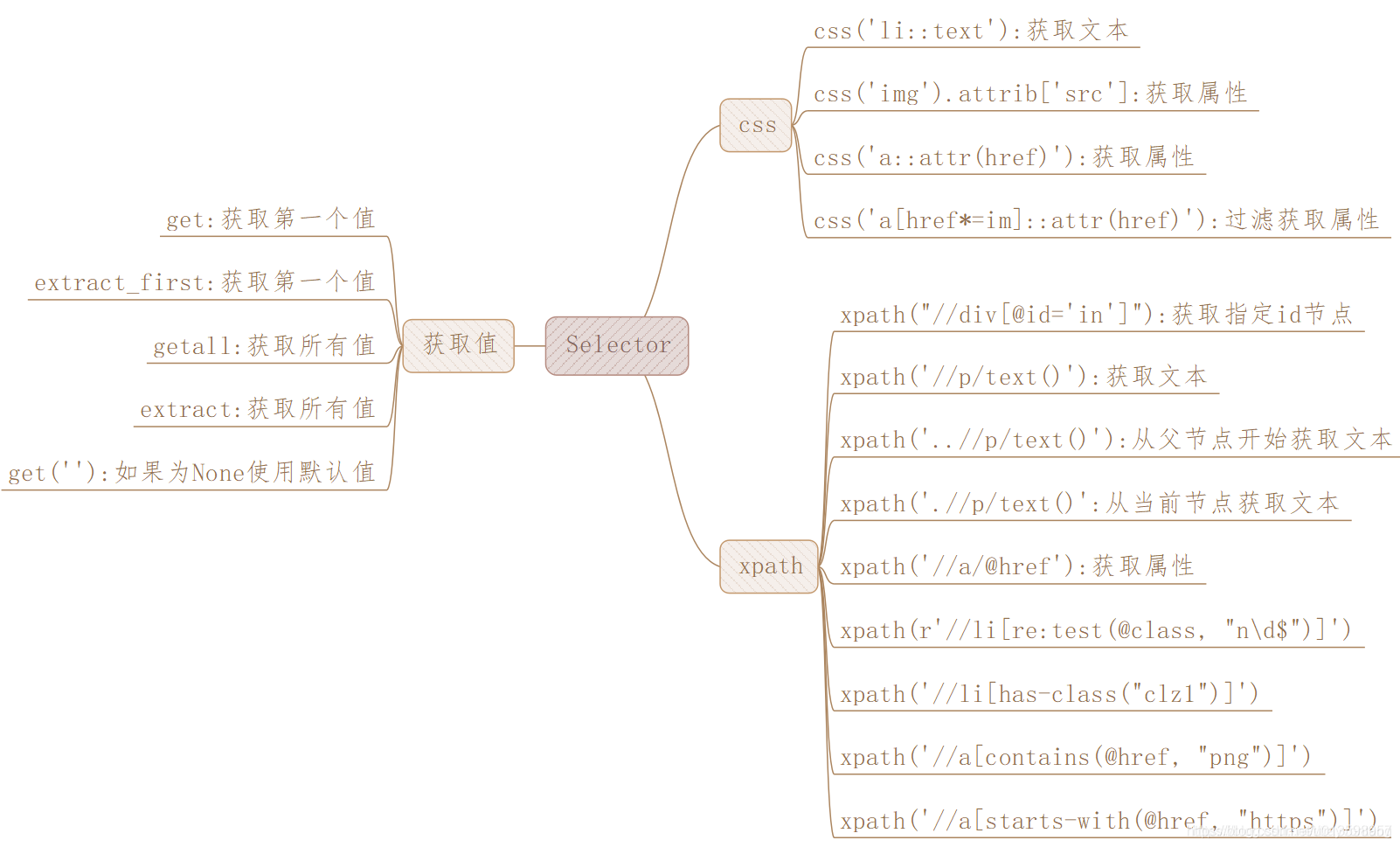
当获取的内容是 Selector 或者 Selectorlist 类型时,它们并不是真正的文本内容。extract()方法可以把获取真实需要的内容,结果是列表形式。 而用 text() 改写 XPath 表达式可以选取节点的内部文本和属性。

利用 extract_first ()方法专门提取匹配的第一个结果,同时我们也不用担心数组越界的问题(尝试获取空列表)。

Selector之下,我们可以随意使用 xpath()和 css ()方法二者自由组合实现嵌套查询,二者是完全兼容的。
还有正则表达式:

注意的是, response 对象不能直接调用 re() 和 re_first() 方法,直接调用会提示没有该属性。 如果想要对全文进行正则匹配,可以先调用 xpath() 方法再正则匹配。
Spider 的用法
上一篇笔记简单提到过Spider,它是Scrapy 爬虫项目的核心类。概括来讲, Spider 要做的事有两件:
- 定义爬取网站的动作
- 分析爬取下来的网页
回顾:
我们定义的 Spider 继承 scrapy.Spider

scrapy.spiders.Spider这个类提供了 start_requests() 方法的默认实现,读取并请求start_urls属性,并根据返回的结果调用parse()方法解析结果。
# scrapy.Spider下,有这些基础属性:
# name 爬虫名称,是定义 Spider 名字的字符串。Spider的名字定义了 Scrapy 如何定位并初始化Spider ,它必须是唯一的
# allowed_domains 允许爬取的域名,是可选配置,不在此范围的链接不会被跟进爬取
# start_urls 它是起始 URL列表,当我们没有实现 start _requests ()方法时,默认会从这个列表开始抓取
# custom_settings 它是一个字典,是专属于本Spider的配置,此设置会覆盖项目全局的设置。此设置必须在初始化前被更新,必须定义成类变量
# crawler 它是由from_crawler()方法设置的,代表的是本Spider类对应的Crawler对象。Crawler对象包含了很多项目组件,利用它我们可以获取项目的一些配置信息,如最常见的获取项目的设置信息,即Settings
# settings 它是一个Settings对象,利用它我们可以直接获取项目的全局设置变量
# 不只基础属性,Spider还有一些常用的方法:
# start_requests() 此方法用于生成初始请求,它必须返回一个可迭代对象。此方法会默认使用start_urls里面的URL来构造Request,而且Request是GET请求方式。如果我们想在启动时以POST方式访问某个站点,可以直接重写这个方法,发送POST请求时使用FormRequest即可。
# parse() 当Response没有指定回调函数时,该方法会默认被调用。它负责处理Response,处理返回结果,并从中提取出想要的数据和下一步的请求,然后返回。该方法需要返回一个包含Request或Item的可迭代对象。
# closed() 当Spider关闭时,该方法会被调用,在这里一般会定义释放资源的一些操作或其他收尾操作。
Downloader Middleware
Downloader Middleware 即下载中间件,它是处于 Scrapy Request 和Response 之间的处理模块。

Downloader Middleware 的功能十分强大,修改 User-Agent、 处理重定向、设置代理、失败重试、设置 cookies 等功能都需要借助它来实现。
需要说明的是, Scrapy 其实已经提供了许多 Downloader Middleware ,比如负责失败重试、自动重定向等功能的 Middleware ,它们被DOWNLOADER MIDDLEWARES BASE 变量所定义。
(一个字典格式,value代表了调用的优先级,数字小的 Downloader Middleware 会被优先调用)
Scrapy 提供了另外一个设置变量 DOWNLOADER_MIDDLEWARES ,我们直接修改它就可以自定义,如添加件、禁用件。
-
单独定义 Downloader Middleware:
# 核心的方法有三个: # (只需要实现至少一个方法,就可以定义 Downloader Middleware) process_request(request, spider) # Request 被 Scrapy 从引擎调度给 Downloader 之前,我们都可以用该方法对 Request 进行处理 # 返回值必须为 None 、Response 对象、Request对象之一,或者抛出 IgnoreRequest异常 process_response(request,response spider) # 在 Scrapy 引擎便将 Response 发送给 Spider 进行解析之前 # 返回值对象除了不能为 None,其余同上,者抛出 IgnoreRequest异常 process_exception(request, exception, spider) # 当Downloader process_request()方法抛出异常时,该方法被调用 # 返回值必须为 None 、Response 对象、Request对象之一
Spider Middleware 的用法
Spider Middleware 是介入到 Scrapy Spider 处理机制的钩子框架。

与 Downloader Middleware 类似,Scrapy 也已经提供了许多 Spider Middleware。
-
单独定义 Spider Middleware 的核心方法:(与下载中间件类比)
process_spider_input(response spider) # 当 Response 被 Spider Middleware 处理时 process_spider output(response, result, spider) # Spider处理 Response 返回结果时 process_spider_exception(response, exception, spider) # Spider 或 Spider Middleware process_spider _input() 方法抛出异常时 process_start_requests(start_requests spider) # process_start_requests()方法以 Spider 启动的 Request 为参数被调用 # 执行的过程类似 process_spider_output() # 但它没有相关联的 Response,并且必须返回 Request # 只需要实现其中一个方法就可以定义一个 Spider Middleware
Spider Middleware 使用的频率不如 Downloader Middleware 高,在必要的情况下它可以用来方便数据的处理。