Scikit-Learn 简介
Scikit-Learn 数据表布局
机器学习是从数据创建模型的学问,因此你首先需要了解怎样表示数据才能让计算机理解。Scikit-Learn 认为数据表示最好的方法就是用数据表的形式。
示例:

Scikit-Learn的评估器API
主要遵照的设计原则:
-
统一性:所有对象使用共同接口连接一组方法和统一的文档。
-
内省:所有参数值都是公共属性。
-
限制对象层级:只有算法可以用 Python 类表示。数据集都用标准数据类型(NumPy 数组、Pandas DataFrame、SciPy 稀疏矩阵)表示,参数名称用标准的 Python 字符串。
-
函数组合:许多机器学习任务都可以用一串基本算法实现,Scikit-Learn 尽力支持这种可能。
-
明智的默认值:当模型需要用户设置参数时,Scikit-Learn 预先定义适当的默认值
Scikit-Learn 中的所有机器学习算法都是通过评估器 API 实现的,它为各种机器学习应用提供了统一的接口。
模型超参数与验证
背景:

当我们选择了模型类之后,还有许多参数需要配置。我们可能要考虑到以下问题:

一些重要的参数必须在选择模型类时确定好。这些参数通常被称为超参数,即在模型拟合数据之前必须被确定的参数。
( 而Scikit-Learn 中,运用 fit() 方法后获得的模型参数都带一条下划线。)
为了作出正确的选择,我们需要一种方式来验证选中的模型和超参数是否可以很好地拟合数据。
验证时的常见错误:用同一套数据训练和评估模型。
模型验证正确方法:
-
留出集(如train_test_split 工具),缺点是进行模型验证使失去了一部分训练机会,尤其是在训练数据集规模比较小的时候问题更明显。
-
交叉验证法:Scikit-Learn 为不同应用场景提供了各种交叉检验方法,都以迭代器(iterator)形式在 cross_validation 模块中实现。 特例:交叉检验的轮数与样本数相同的极端情况,也就是说每次只有一个样本做测试,其他样本全用于训练。这种交叉检验类型被称为 LOO(leave-one-out,只留一个)交叉检验。
示例:

选择最优模型
1.偏差与方差
“最优模型”的问题基本可以看成是找出偏差与方差平衡点的问题。
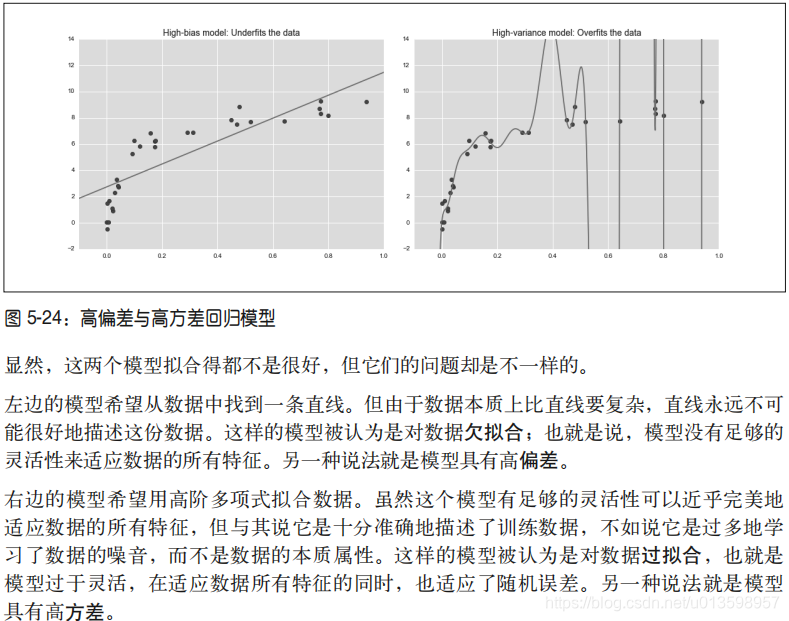
• 对于高偏差模型,模型在验证集的表现与在训练集的表现类似。
• 对于高方差模型,模型在验证集的表现远远不如在训练集的表现。
改善关键点:模型复杂度。(由此引出验证曲线)
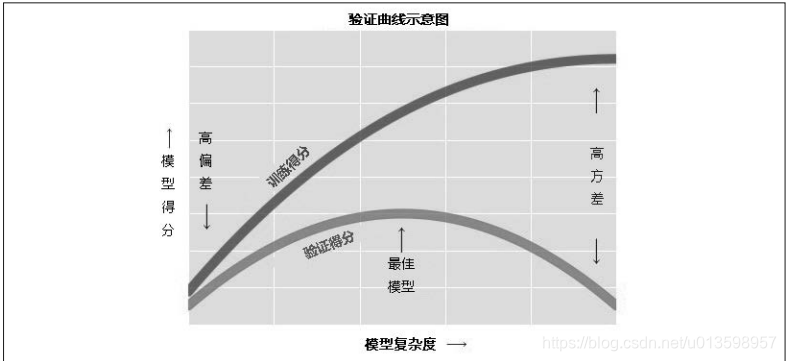
验证曲线:
首先,认为一般情况下,模型拟合自己接触过的数据,比拟合没接触
过的数据效果要好。
不同模型复杂度的调整方法大不相同。如线性回归主要是是对多项式次数的确定。
如何更方便地控制模型复杂度?通过可视化验证曲线可回答这个问题——利用 Scikit-Learn 的 validation_curve 函数就可以简单地实现。只要提供模型、数据、参数名称和验证范围信息,函数就会自动计算验证范围内的训练得分和验证得分。
2.学习曲线
影响模型效果的另一个重要因素是最优模型往往受到训练数据量的影响。
大数据集支持更复杂的模型。
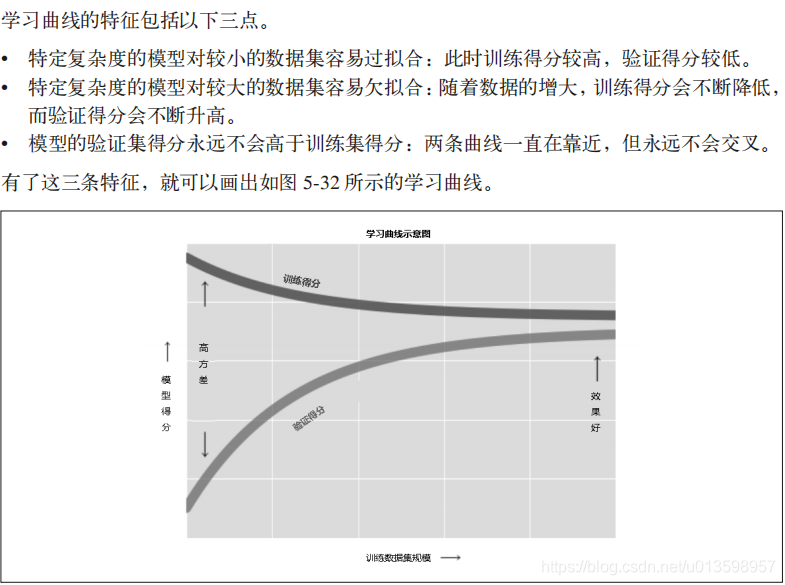
学习曲线最重要的特征是,随着训练样本数量的增加,分数会收敛到定值。此时认为增加更多的训练样本也无济于事。改善模型性能的唯一方法就是换模型(通常是同类换成更复杂的模型)。
sklearn 学习曲线:

特征工程
向量化:把任意格式的数据转换成具有良好特性的向量形式。
-
分类特征
常用的解决方法是独热编码。有效增加额外的列,让 0 和 1 出现在对应的列分别表示每个分类值有或无。


缺陷:如果你的分类特征有许多枚举值,那么数据集的维度就
会急剧增加。然而,由于被编码的数据中有许多 0,因此用稀疏矩阵表示会非常高效 -
文本特征
绝大多数社交媒体数据的自动化采集,都是依靠将文本编码成数字的技术手段。数据采集最简单的编码方法之一就是单词统计:给你几个文本,让你统计每个词出现的次数,然后放到表格中。

结果是一个稀疏矩阵,里面记录了每个短语中每个单词的出现次数。

-
图像特征:以像素为特征表示图像是最简单的方法。但是在许多类型的任务中,这类方法一般不太合适。
-
衍生特征:输入特征经过数学变换衍生出来的新特征。
举例:将一个线性回归转换成多项式回归,并不是通过改变模型来实现,而是通过改变输入数据。这种处理方式有时被称为基函数回归。
这种不通过改变模型,而是通过变换输入来改善模型效果的理念,正是许多更强大的机器学习方法的基础。
-
处理缺失值
缺失值填充:相应的策略很多,有的简单(例如用列均值替换缺失值),有的复杂(例如用矩阵填充或其他模型来处理缺失值)。

-
管道处理
当你需要将多个步骤串起来使用时,手动应用一个个方法可能会比较麻烦,sklearn 提供了管道处理方法减少代码量。
