原文地址::https://www.cnblogs.com/flyinggod/p/13415862.html
相关文章
1、Core文件作用、设置及用法----https://www.cnblogs.com/xiaodoujiaohome/p/6222895.html
2、Linux 系统设置 ulimit 以及 Core文件的生成----https://blog.csdn.net/zjb9605025/article/details/6553184
| 1 2 3 4 5 6 7 8 9 10 |
|
core dump的生成方式
Linux环境下进程发生异常而挂掉,通常很难查找原因,但是一般Linux内核给我们提供的核心文件,记录了进程在崩溃时候的信息。但是生成core文件需要设置开关,具体步骤如下:
1、查看生成core文件的开关是否开启,输入命令
ulimit -a
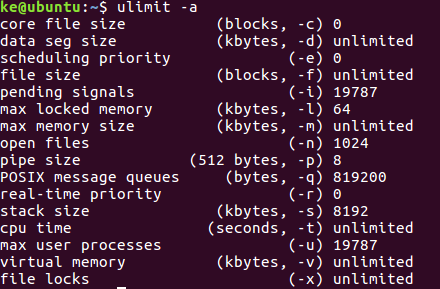
第一行core文件大小为0,没有开启。
2、使用 ulimit -c [kbytes] 可以设置系统允许生成的core文件大小。
| 1 2 3 |
|
执行命令 ulimit -c unlimited,然后ulimit -a查看core
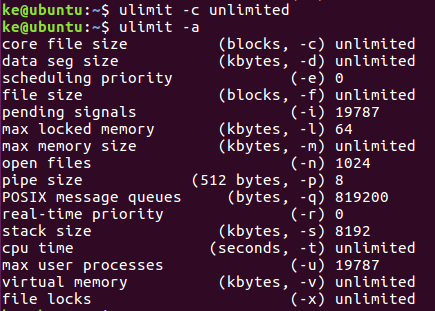
这样进程崩溃就可以生成core文件了,这种方法只能在shell中生效,需要此设置一直生效需要做如下设置
| 1 2 |
|
保存退出,重启服务器,改文件就长久生效,或者
source /etc/profile
不重启服务器,使用source使文件马上生效。
3.指定生成文件的路径和名字
默认情况下,core dump生成的文件名为core,而且就在程序当前目录下。新的core会覆盖已存在的core, 通过修改/proc/sys/kernel/core_uses_pid文件,可以控制core文件保存位置和文件格式。
vim /etc/sysctl.conf #进入编辑模式,加入下面两行 kernel.core_pattern=/tmp/corefile/core_%t_%e_%p kernel.core_uses_pid=0
在var下创建core目录,用
sysctl –p /etc/sysctl.conf
是修改马上生效。
core_pattern的命名参数如下:

%c 转储文件的大小上限 %e 所dump的文件名 %g 所dump的进程的实际组ID %h 主机名 %p 所dump的进程PID %s 导致本次coredump的信号 %t 转储时刻(由1970年1月1日起计的秒数) %u 所dump进程的实际用户ID
4、terminal中执行命令: kill -s SIGSEGV $$ , 可以看到/tmp/corefile下生成了一个core文件,说明已经设置成功。
在下列条件下不产生core 文件:
| 1 2 3 4 |
|
core dump的产生原理
发生coredump一般都是在进程收到某个信号的时候,Linux上现在大概有60多个信号,可以使用 kill -l 命令全部列出来。
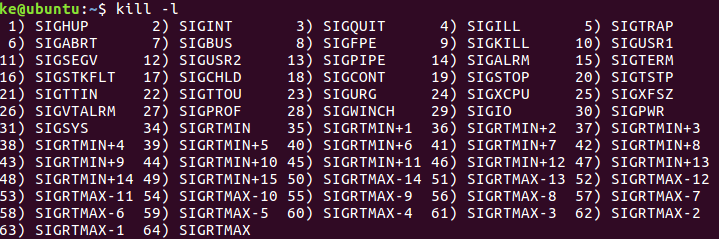
针对特定的信号,应用程序可以写对应的信号处理函数。如果不指定,则采取默认的处理方式, 默认处理是coredump的信号如下:
| 1 2 |
|
我们看到SIGSEGV在其中,一般数组越界或是访问空指针都会产生这个信号。另外虽然默认是这样的,但是你也可以写自己的信号处理函数改变默认行为,更多信号相关可以自行Google。
core dump文件调试
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
上述代码为会产生coredump的实例代码

此时此可执行程序下面产生了新的core文件
查看进程崩溃在何处

定位到崩溃的所在行
在编译的时候开启-g调试开关就可以
| 1 |
|

如果不想设置coredum全局模式,只需要针对当前进程产生可以定位崩溃位置的core文件,只需要4个操作,
| 1 2 3 4 |
|
上边的程序编译的时候有一点需要注意,需要带上参数-g, 这样生成的可执行程序中会带上足够的调试信息。编译运行之后你就应该能看见期待已久的“Segment Fault(core dumped)”或是“段错误 (核心已转储)”之类的字眼了。看看当前目录下是不是有个core或是core.xxx的文件。使用linux下经典的调试器GDB,首先带着core文件载入程序:gdb exefile core,这里需要注意的这个core文件必须是exefile产生的,否则符号表会对不上。载入之后大概是这个样子的
| 1 2 3 4 5 6 |
|
我们看到已经能直接定位到出core的地方了,在第8行写了一个只读的内存区域导致触发Segment Fault信号。在载入core的时候有个小技巧,如果你事先不知道这个core文件是由哪个程序产生的,你可以先随便找个代替一下,比如/usr/bin/w就是不错的选择。比如我们采用这种方法载入上边产生的core,gdb会有类似的输出
| 1 2 3 4 5 |
|
可以看到GDB已经提示你了,这个core是由哪个程序产生的。
GDB 常用操作
上边的程序比较简单,不需要另外的操作就能直接找到问题所在。现实却不是这样的,常常需要进行单步跟踪,设置断点之类的操作才能顺利定位问题。下边列出了GDB一些常用的操作。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|