目录
一、概述
1、定义
窗口函数是一组特殊函数
- 扫描多个输入行来计算每个输出值,为每行数据生成一行结构
- 可以通过窗口函数来实现复杂的计算和聚合
- 按功能可划分为:序列(排序),聚合,分析
2、语法
function (arg1,..., arg n) over ([partition by <...>] [order by <....>] [<window_clause>])
- partition by类似于group by,未指定则按整个结果集
- 只有指定order by子句之后才能进行窗口定义
- 可同时使用多个窗口函数
- 过滤窗口函数计算结果必须在外面一层
3、演示数据
创建employee_contract表
其字段如下:
+---------------+-----------------------------+----------+--+
| col_name | data_type | comment |
+---------------+-----------------------------+----------+--+
| name | string | |
| work_place | array<string> | |
| sex_age | struct<sex:string,age:int> | |
| skills_score | map<string,int> | |
| depart_title | map<string,array<string>> | |
+---------------+-----------------------------+----------+--+
表中数据如下:
+-------------------------+-------------------------------+----------------------------+---------------------------------+----------------------------------------+--+
| employee_external.name | employee_external.work_place | employee_external.sex_age | employee_external.skills_score | employee_external.depart_title |
+-------------------------+-------------------------------+----------------------------+---------------------------------+----------------------------------------+--+
| Michael | ["Montreal","Toronto"] | {
"sex":"Male","age":30} | {
"DB":80} | {
"Product":["Developer","Lead"]} |
| Will | ["Montreal"] | {
"sex":"Male","age":35} | {
"Perl":85} | {
"Product":["Lead"],"Test":["Lead"]} |
| Shelley | ["New York"] | {
"sex":"Female","age":27} | {
"Python":80} | {
"Test":["Lead"],"COE":["Architect"]} |
| Lucy | ["Vancouver"] | {
"sex":"Female","age":57} | {
"Sales":89,"HR":94} | {
"Sales":["Lead"]} |
+-------------------------+-------------------------------+----------------------------+---------------------------------+----------------------------------------+--+
二、窗口函数 - 序列
1、row_number()
对所有数值输出不同的序号,序号唯一连续
(1)给所有员工薪资排序,从低到高,针对所有员工
select name,dept_num,salary,
row_number() over(order by salary) as rn
from employee_contract;
运行结果如下:
+----------+-----------+---------+-----+--+
| name | dept_num | salary | rn |
+----------+-----------+---------+-----+--+
| Wendy | 1000 | 4000 | 1 |
| Will | 1000 | 4000 | 2 |
| Lily | 1001 | 5000 | 3 |
| Michael | 1000 | 5000 | 4 |
| Yun | 1002 | 5500 | 5 |
| Lucy | 1000 | 5500 | 6 |
| Jess | 1001 | 6000 | 7 |
| Mike | 1001 | 6400 | 8 |
| Steven | 1000 | 6400 | 9 |
| Wei | 1002 | 7000 | 10 |
| Richard | 1002 | 8000 | 11 |
+----------+-----------+---------+-----+--+
(2)按部门对每个员工薪资排序
select name,dept_num,salary,
row_number() over(partition by dept_num order by salary) as rn
from employee_contract;
运行结果如下:
+----------+-----------+---------+-----+--+
| name | dept_num | salary | rn |
+----------+-----------+---------+-----+--+
| Yun | 1002 | 5500 | 1 |
| Wei | 1002 | 7000 | 2 |
| Richard | 1002 | 8000 | 3 |
| Wendy | 1000 | 4000 | 1 |
| Will | 1000 | 4000 | 2 |
| Michael | 1000 | 5000 | 3 |
| Lucy | 1000 | 5500 | 4 |
| Steven | 1000 | 6400 | 5 |
| Lily | 1001 | 5000 | 1 |
| Jess | 1001 | 6000 | 2 |
| Mike | 1001 | 6400 | 3 |
+----------+-----------+---------+-----+--+
2、rank()
对相同数值,输出相同的序号,下一个序号跳过(1,1,3)
(1)给所有员工薪资排序,从低到高,针对所有员工
select name,dept_num,salary,
rank() over(order by salary) as rn
from employee_contract;
运行结果如下:
+----------+-----------+---------+-----+--+
| name | dept_num | salary | rn |
+----------+-----------+---------+-----+--+
| Wendy | 1000 | 4000 | 1 |
| Will | 1000 | 4000 | 1 |
| Lily | 1001 | 5000 | 3 |
| Michael | 1000 | 5000 | 3 |
| Yun | 1002 | 5500 | 5 |
| Lucy | 1000 | 5500 | 5 |
| Jess | 1001 | 6000 | 7 |
| Mike | 1001 | 6400 | 8 |
| Steven | 1000 | 6400 | 8 |
| Wei | 1002 | 7000 | 10 |
| Richard | 1002 | 8000 | 11 |
+----------+-----------+---------+-----+--+
3、dense_rank()
对相同数值,输出相同的序号,下一个序号连续(1,1,2)
(1)给所有员工薪资排序,从低到高,针对所有员工
select name,dept_num,salary,
dense_rank() over(order by salary) as rn
from employee_contract;
运行结果如下:
+----------+-----------+---------+-----+--+
| name | dept_num | salary | rn |
+----------+-----------+---------+-----+--+
| Wendy | 1000 | 4000 | 1 |
| Will | 1000 | 4000 | 1 |
| Lily | 1001 | 5000 | 2 |
| Michael | 1000 | 5000 | 2 |
| Yun | 1002 | 5500 | 3 |
| Lucy | 1000 | 5500 | 3 |
| Jess | 1001 | 6000 | 4 |
| Mike | 1001 | 6400 | 5 |
| Steven | 1000 | 6400 | 5 |
| Wei | 1002 | 7000 | 6 |
| Richard | 1002 | 8000 | 7 |
+----------+-----------+---------+-----+--+
(2)按部门分组,获取每个部门薪资最低的员工
select name,dept_num,salary from
(select name,dept_num,salary,
dense_rank() over(partition by dept_num order by salary) as rn
from employee_contract) t
where t.rn=1;
运行结果如下:
+--------+-----------+---------+--+
| name | dept_num | salary |
+--------+-----------+---------+--+
| Yun | 1002 | 5500 |
| Wendy | 1000 | 4000 |
| Will | 1000 | 4000 |
| Lily | 1001 | 5000 |
+--------+-----------+---------+--+
4、ntile(n)
将有序的数据集合平均分配到n个桶中, 将桶号分配给每一行,根据桶号,选取前或后n分之几的数据
(1)分桶查询
select name,dept_num,salary,
ntile(2) over(partition by dept_num order by salary)
as nlite
from employee_contract;
运行结果如下:
+----------+-----------+---------+--------+--+
| name | dept_num | salary | nlite |
+----------+-----------+---------+--------+--+
| Yun | 1002 | 5500 | 1 |
| Wei | 1002 | 7000 | 1 |
| Richard | 1002 | 8000 | 2 |
| Wendy | 1000 | 4000 | 1 |
| Will | 1000 | 4000 | 1 |
| Michael | 1000 | 5000 | 1 |
| Lucy | 1000 | 5500 | 2 |
| Steven | 1000 | 6400 | 2 |
| Lily | 1001 | 5000 | 1 |
| Jess | 1001 | 6000 | 1 |
| Mike | 1001 | 6400 | 2 |
+----------+-----------+---------+--------+--+
5、percent_rank()
(目前排名- 1)/(总行数- 1),值相对于一组值的百分比排名,即排名前百分比
(1)查询工资排名百分比
select name,dept_num,salary,
percent_rank() over(order by salary)
as pr
from employee_contract;
运行结果如下:
+----------+-----------+---------+------+--+
| name | dept_num | salary | pr |
+----------+-----------+---------+------+--+
| Wendy | 1000 | 4000 | 0.0 |
| Will | 1000 | 4000 | 0.0 |
| Lily | 1001 | 5000 | 0.2 |
| Michael | 1000 | 5000 | 0.2 |
| Yun | 1002 | 5500 | 0.4 |
| Lucy | 1000 | 5500 | 0.4 |
| Jess | 1001 | 6000 | 0.6 |
| Mike | 1001 | 6400 | 0.7 |
| Steven | 1000 | 6400 | 0.7 |
| Wei | 1002 | 7000 | 0.9 |
| Richard | 1002 | 8000 | 1.0 |
+----------+-----------+---------+------+--+
三、窗口函数 - 聚合
1、count()
计数,可以和distinct一起用
(1)统计每个部门人数
select name,dept_num,salary,
count(*) over(partition by dept_num) as rc
from employee_contract;
运行结果如下:
+----------+-----------+---------+-----+--+
| name | dept_num | salary | rc |
+----------+-----------+---------+-----+--+
| Lucy | 1000 | 5500 | 5 |
| Steven | 1000 | 6400 | 5 |
| Wendy | 1000 | 4000 | 5 |
| Will | 1000 | 4000 | 5 |
| Michael | 1000 | 5000 | 5 |
| Mike | 1001 | 6400 | 3 |
| Jess | 1001 | 6000 | 3 |
| Lily | 1001 | 5000 | 3 |
| Richard | 1002 | 8000 | 3 |
| Yun | 1002 | 5500 | 3 |
| Wei | 1002 | 7000 | 3 |
+----------+-----------+---------+-----+--+
2、sum()
求和
(1)求每个部门的工资总和
select name,dept_num,salary,
sum(salary) over(partition by dept_num order by salary) as sum_salary
from employee_contract;
运行结果如下:
+----------+-----------+---------+-------------+--+
| name | dept_num | salary | sum_salary |
+----------+-----------+---------+-------------+--+
| Wendy | 1000 | 4000 | 8000 |
| Will | 1000 | 4000 | 8000 |
| Michael | 1000 | 5000 | 13000 |
| Lucy | 1000 | 5500 | 18500 |
| Steven | 1000 | 6400 | 24900 |
| Lily | 1001 | 5000 | 5000 |
| Jess | 1001 | 6000 | 11000 |
| Mike | 1001 | 6400 | 17400 |
| Yun | 1002 | 5500 | 5500 |
| Wei | 1002 | 7000 | 12500 |
| Richard | 1002 | 8000 | 20500 |
+----------+-----------+---------+-------------+--+
(2)求所有人工资总和
select name,dept_num,salary,
sum(salary) over(order by salary) as sum_salary
from employee_contract;
运行结果如下:
+----------+-----------+---------+-------------+--+
| name | dept_num | salary | sum_salary |
+----------+-----------+---------+-------------+--+
| Wendy | 1000 | 4000 | 8000 |
| Will | 1000 | 4000 | 8000 |
| Lily | 1001 | 5000 | 18000 |
| Michael | 1000 | 5000 | 18000 |
| Yun | 1002 | 5500 | 29000 |
| Lucy | 1000 | 5500 | 29000 |
| Jess | 1001 | 6000 | 35000 |
| Mike | 1001 | 6400 | 47800 |
| Steven | 1000 | 6400 | 47800 |
| Wei | 1002 | 7000 | 54800 |
| Richard | 1002 | 8000 | 62800 |
+----------+-----------+---------+-------------+--+
3、avg()、max()、min()
平均值、最大值、最小值
select name,dept_num,salary,
avg(salary) over(partition by dept_num) as avgDept,
min(salary) over(partition by dept_num) as minDept,
max(salary) over(partition by dept_num) as maxDept
from employee_contract;
运行结果如下:
+----------+-----------+---------+--------------------+----------+----------+--+
| name | dept_num | salary | avgdept | mindept | maxdept |
+----------+-----------+---------+--------------------+----------+----------+--+
| Lucy | 1000 | 5500 | 4980.0 | 4000 | 6400 |
| Steven | 1000 | 6400 | 4980.0 | 4000 | 6400 |
| Wendy | 1000 | 4000 | 4980.0 | 4000 | 6400 |
| Will | 1000 | 4000 | 4980.0 | 4000 | 6400 |
| Michael | 1000 | 5000 | 4980.0 | 4000 | 6400 |
| Mike | 1001 | 6400 | 5800.0 | 5000 | 6400 |
| Jess | 1001 | 6000 | 5800.0 | 5000 | 6400 |
| Lily | 1001 | 5000 | 5800.0 | 5000 | 6400 |
| Richard | 1002 | 8000 | 6833.333333333333 | 5500 | 8000 |
| Yun | 1002 | 5500 | 6833.333333333333 | 5500 | 8000 |
| Wei | 1002 | 7000 | 6833.333333333333 | 5500 | 8000 |
+----------+-----------+---------+--------------------+----------+----------+--+
四、窗口函数 - 分析
1、cume_dist
小于等于当前值的行数/分组内总行数
(1)求每个部门中每个人的薪资排名比
select name,dept_num,salary,
cume_dist() over(partition by dept_num
order by salary) as cd
from employee_contract;
运行结果如下:
+----------+-----------+---------+---------------------+--+
| name | dept_num | salary | cd |
+----------+-----------+---------+---------------------+--+
| Wendy | 1000 | 4000 | 0.4 |
| Will | 1000 | 4000 | 0.4 |
| Michael | 1000 | 5000 | 0.6 |
| Lucy | 1000 | 5500 | 0.8 |
| Steven | 1000 | 6400 | 1.0 |
| Lily | 1001 | 5000 | 0.3333333333333333 |
| Jess | 1001 | 6000 | 0.6666666666666666 |
| Mike | 1001 | 6400 | 1.0 |
| Yun | 1002 | 5500 | 0.3333333333333333 |
| Wei | 1002 | 7000 | 0.6666666666666666 |
| Richard | 1002 | 8000 | 1.0 |
+----------+-----------+---------+---------------------+--+
2、lead/lag(col,n)
某一列进行往前/后第n行值(n可选,默认为1)
(1)以部门分组、员工薪资排序,求当前员工的后面一位员工的薪资,每个部门排名最后一个用默认值 NULL 表示
select name,dept_num,salary,
lead(salary,1) over(partition by dept_num order by salary) as lead
from employee_contract;
运行结果如下:
+----------+-----------+---------+-------+--+
| name | dept_num | salary | lead |
+----------+-----------+---------+-------+--+
| Wendy | 1000 | 4000 | 4000 |
| Will | 1000 | 4000 | 5000 |
| Michael | 1000 | 5000 | 5500 |
| Lucy | 1000 | 5500 | 6400 |
| Steven | 1000 | 6400 | NULL |
| Lily | 1001 | 5000 | 6000 |
| Jess | 1001 | 6000 | 6400 |
| Mike | 1001 | 6400 | NULL |
| Yun | 1002 | 5500 | 7000 |
| Wei | 1002 | 7000 | 8000 |
| Richard | 1002 | 8000 | NULL |
+----------+-----------+---------+-------+--+
(2)以部门分组、员工薪资排序,求当前员工的后面一位员工的薪资,每个部门排名最后一个用指定 0 表示
select name,dept_num,salary,
lead(salary,1,0) over(partition by dept_num order by salary) as lead
from employee_contract;
运行结果如下:
+----------+-----------+---------+-------+--+
| name | dept_num | salary | lead |
+----------+-----------+---------+-------+--+
| Wendy | 1000 | 4000 | 4000 |
| Will | 1000 | 4000 | 5000 |
| Michael | 1000 | 5000 | 5500 |
| Lucy | 1000 | 5500 | 6400 |
| Steven | 1000 | 6400 | 0 |
| Lily | 1001 | 5000 | 6000 |
| Jess | 1001 | 6000 | 6400 |
| Mike | 1001 | 6400 | 0 |
| Yun | 1002 | 5500 | 7000 |
| Wei | 1002 | 7000 | 8000 |
| Richard | 1002 | 8000 | 0 |
+----------+-----------+---------+-------+--+
(3)以部门分组、员工薪资排序,求当前员工的前面一位员工的薪资,每个部门排名第一个员工用默认值 NULL 表示
select name,dept_num,salary,
lag(salary,1) over(partition by dept_num order by salary) as lag
from employee_contract;
运行结果如下:
+----------+-----------+---------+-------+--+
| name | dept_num | salary | lag |
+----------+-----------+---------+-------+--+
| Wendy | 1000 | 4000 | NULL |
| Will | 1000 | 4000 | 4000 |
| Michael | 1000 | 5000 | 4000 |
| Lucy | 1000 | 5500 | 5000 |
| Steven | 1000 | 6400 | 5500 |
| Lily | 1001 | 5000 | NULL |
| Jess | 1001 | 6000 | 5000 |
| Mike | 1001 | 6400 | 6000 |
| Yun | 1002 | 5500 | NULL |
| Wei | 1002 | 7000 | 5500 |
| Richard | 1002 | 8000 | 7000 |
+----------+-----------+---------+-------+--+
(4)以部门分组、员工薪资排序,求当前员工的前面一位员工的薪资,每个部门排名第一个员工用指定值 0 表示
select name,dept_num,salary,
lag(salary,1,0) over(partition by dept_num order by salary) as lag
from employee_contract;
运行结果如下:
+----------+-----------+---------+-------+--+
| name | dept_num | salary | lag |
+----------+-----------+---------+-------+--+
| Wendy | 1000 | 4000 | 0 |
| Will | 1000 | 4000 | 4000 |
| Michael | 1000 | 5000 | 4000 |
| Lucy | 1000 | 5500 | 5000 |
| Steven | 1000 | 6400 | 5500 |
| Lily | 1001 | 5000 | 0 |
| Jess | 1001 | 6000 | 5000 |
| Mike | 1001 | 6400 | 6000 |
| Yun | 1002 | 5500 | 0 |
| Wei | 1002 | 7000 | 5500 |
| Richard | 1002 | 8000 | 7000 |
+----------+-----------+---------+-------+--+
3、firsvt_value、last_value
对该列到目前为止的首个值、最后一个值
select name,dept_num,salary,
first_value(salary) over(partition by dept_num order by salary) as fv,
last_value(salary) over(partition by dept_num order by salary) as lv
from employee_contract;
运行结果如下:
+----------+-----------+---------+-------+-------+--+
| name | dept_num | salary | fv | lv |
+----------+-----------+---------+-------+-------+--+
| Wendy | 1000 | 4000 | 4000 | 4000 |
| Will | 1000 | 4000 | 4000 | 4000 |
| Michael | 1000 | 5000 | 4000 | 5000 |
| Lucy | 1000 | 5500 | 4000 | 5500 |
| Steven | 1000 | 6400 | 4000 | 6400 |
| Lily | 1001 | 5000 | 5000 | 5000 |
| Jess | 1001 | 6000 | 5000 | 6000 |
| Mike | 1001 | 6400 | 5000 | 6400 |
| Yun | 1002 | 5500 | 5500 | 5500 |
| Wei | 1002 | 7000 | 5500 | 7000 |
| Richard | 1002 | 8000 | 5500 | 8000 |
+----------+-----------+---------+-------+-------+--+
五、窗口函数 - 窗口子句
1、含义
窗口子句由[<window_clause>]子句描述
- 用于进一步细分结果并应用分析函数
- rank、ntile、dense_rank、cume_dist、percent_rank、lead、lag和row_number函数不支持与窗口子句一起使用
- 支持两类窗口子句
- 行类型窗口
- 范围类型窗口
2、行窗口
(1)根据当前行之前或之后的行号确定的窗口
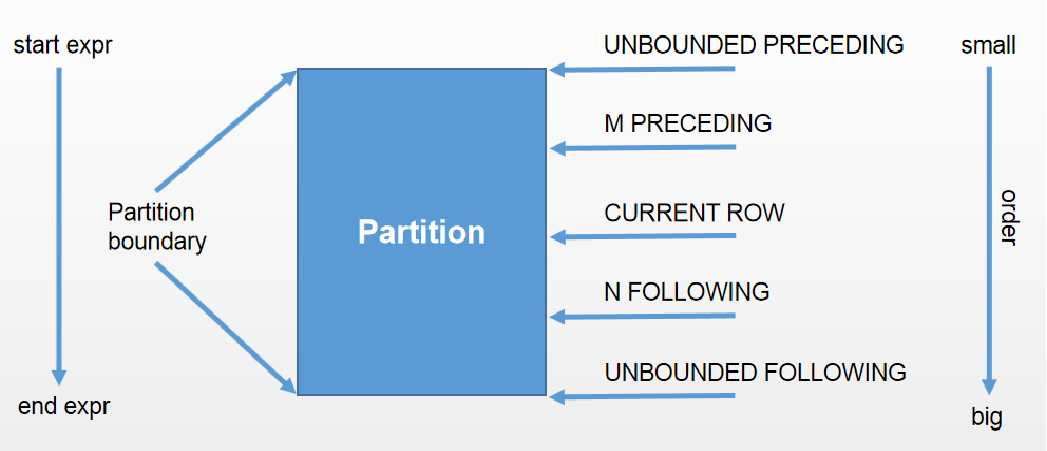
(2)语法:
rows between <start_expr> and <end_expr>
(3)<start_expr>取值
| 取值 | 意义 |
|---|---|
| unbounded preceding | 窗口起始位置(分组第一行) |
| current row | 当前行 |
| n preceding/following | 当前行之前/之后n行 |
(4)<end_expr>可以为下列值
| 取值 | 意义 |
|---|---|
| unbounded following | 窗口结束位置(分组最后一行) |
| current row | 当前行 |
| n preceding/following | 当前行之前/之后n行 |
示例:
select
name, dept_num as dept, salary as sal,
max(salary) over (partition by dept_num order by name rows between 2 preceding and current row) win1,
max(salary) over (partition by dept_num order by name rows between 2 preceding and unbounded following) win2,
max(salary) over (partition by dept_num order by name rows between 1 preceding and 2 following) win3,
max(salary) over (partition by dept_num order by name rows between 2 preceding and 1 preceding) win4,
max(salary) over (partition by dept_num order by name rows between 1 following and 2 following) win5,
max(salary) over (partition by dept_num order by name rows between current row and current row) win6,
max(salary) over (partition by dept_num order by name rows between current row and 1 following) win7,
max(salary) over (partition by dept_num order by name rows between current row and unbounded following) win8,
max(salary) over (partition by dept_num order by name rows between unbounded preceding and current row) win9,
max(salary) over (partition by dept_num order by name rows between unbounded preceding and 1 following) win10,
max(salary) over (partition by dept_num order by name rows between unbounded preceding and unbounded following) win11,
max(salary) over (partition by dept_num order by name rows 2 preceding) win12
from employee_contract order by dept, name;
运行结果如下:
+----------+-------+-------+-------+-------+-------+-------+-------+-------+-------+-------+-------+--------+--------+--------+--+
| name | dept | sal | win1 | win2 | win3 | win4 | win5 | win6 | win7 | win8 | win9 | win10 | win11 | win12 |
+----------+-------+-------+-------+-------+-------+-------+-------+-------+-------+-------+-------+--------+--------+--------+--+
| Lucy | 1000 | 5500 | 5500 | 6400 | 6400 | NULL | 6400 | 5500 | 5500 | 6400 | 5500 | 5500 | 6400 | 5500 |
| Michael | 1000 | 5000 | 5500 | 6400 | 6400 | 5500 | 6400 | 5000 | 6400 | 6400 | 5500 | 6400 | 6400 | 5500 |
| Steven | 1000 | 6400 | 6400 | 6400 | 6400 | 5500 | 4000 | 6400 | 6400 | 6400 | 6400 | 6400 | 6400 | 6400 |
| Wendy | 1000 | 4000 | 6400 | 6400 | 6400 | 6400 | 4000 | 4000 | 4000 | 4000 | 6400 | 6400 | 6400 | 6400 |
| Will | 1000 | 4000 | 6400 | 6400 | 4000 | 6400 | NULL | 4000 | 4000 | 4000 | 6400 | 6400 | 6400 | 6400 |
| Jess | 1001 | 6000 | 6000 | 6400 | 6400 | NULL | 6400 | 6000 | 6000 | 6400 | 6000 | 6000 | 6400 | 6000 |
| Lily | 1001 | 5000 | 6000 | 6400 | 6400 | 6000 | 6400 | 5000 | 6400 | 6400 | 6000 | 6400 | 6400 | 6000 |
| Mike | 1001 | 6400 | 6400 | 6400 | 6400 | 6000 | NULL | 6400 | 6400 | 6400 | 6400 | 6400 | 6400 | 6400 |
| Richard | 1002 | 8000 | 8000 | 8000 | 8000 | NULL | 7000 | 8000 | 8000 | 8000 | 8000 | 8000 | 8000 | 8000 |
| Wei | 1002 | 7000 | 8000 | 8000 | 8000 | 8000 | 5500 | 7000 | 7000 | 7000 | 8000 | 8000 | 8000 | 8000 |
| Yun | 1002 | 5500 | 8000 | 8000 | 7000 | 8000 | NULL | 5500 | 5500 | 5500 | 8000 | 8000 | 8000 | 8000 |
+----------+-------+-------+-------+-------+-------+-------+-------+-------+-------+-------+-------+--------+--------+--------+--+
3、范围窗口
范围窗口是取分组内的值在指定范围区间内的行
- 该范围值/区间必须是数字或日期类型
- 目前只支持一个order by列
示例:
select name, dept_num as dept, salary as sal,
max(salary) over (partition by dept_num order by name rows between 2 preceding and current row) win1,
salary - 1000 as sal_r_start,salary as sal_r_end,
max(salary) over (partition by dept_num
order by name range between 1000 preceding and current row) win13
from employee_contract order by dept, name;
运行结果如下:
+----------+-------+-------+-------+--------------+------------+--------+--+
| name | dept | sal | win1 | sal_r_start | sal_r_end | win13 |
+----------+-------+-------+-------+--------------+------------+--------+--+
| Lucy | 1000 | 5500 | 5500 | 4500 | 5500 | 5500 |
| Michael | 1000 | 5000 | 5500 | 4000 | 5000 | 5000 |
| Steven | 1000 | 6400 | 6400 | 5400 | 6400 | 6400 |
| Wendy | 1000 | 4000 | 6400 | 3000 | 4000 | 4000 |
| Will | 1000 | 4000 | 6400 | 3000 | 4000 | 4000 |
| Jess | 1001 | 6000 | 6000 | 5000 | 6000 | 6000 |
| Lily | 1001 | 5000 | 6000 | 4000 | 5000 | 5000 |
| Mike | 1001 | 6400 | 6400 | 5400 | 6400 | 6400 |
| Richard | 1002 | 8000 | 8000 | 7000 | 8000 | 8000 |
| Wei | 1002 | 7000 | 8000 | 6000 | 7000 | 7000 |
| Yun | 1002 | 5500 | 8000 | 4500 | 5500 | 5500 |
+----------+-------+-------+-------+--------------+------------+--------+--+